
Web scraping vs. web crawling is a topic frequently discussed online. In fact, these terms, web scraping and web crawling, are often used interchangeably, although there are distinct differences.
Web scraping is the extraction of data from websites, whereas web crawling is the process used by search engines to index the content of websites or discovering URLs on the web. In most cases, there is a need to combine web scraping and web crawling.
This article offers a comprehensive overview of web crawling vs. web scraping. You also get a clear picture of how web scraping and web crawling work, their strengths, weaknesses, and applications.
What is Web Scraping?
Web scraping is the process of extracting and examining specific raw data from identified sources on the internet, using tools designed to efficiently pull data from these target websites. These websites are usually known, even if the specific page URLs may not be.
What is Web Crawling?
Web crawling is an automated method of accessing publicly available websites and gathering content from those websites. It indexes web pages, supports search engine functions, and monitors website health.
Web Crawler vs. Web Scraper
A scraper is a tool designed to extract data from websites. It navigates through web pages, identifies and retrieves the specific data points and then saves this data in a structured format for further use.
Scraper converts specific website content into a structured format, including tables, JSON, databases, and XML representations. It facilitates tasks such as market research and competitive analysis.
Although web data collection can also be done manually by copying and pasting information from websites, which is not practical, a scraper aids in streamlining these processes.
A web crawler, web spider, or crawler is a program that searches and gathers URLs without necessarily knowing them in advance. The URLs are further processed and used for various purposes, such as indexing pages for search engines.
Web crawlers scan web pages to understand every website page to retrieve, update, and index information when users perform search queries. The goal of a crawler is to understand the content of a website. This allows users to extract information from one or more pages as needed.
The crawler gathers all relevant page URLs and downloads the HTML files, and then the scraper is used to extract data fields from those pages.
Web Scraping vs. Web Crawling– Significance in Data Extraction
Before learning the similarities and differences between web crawling and web scraping, you need to understand their role in data extraction.
Understanding Web Scraping
Web scraping can be summarized as:
- Sending a request to the desired website.
- Retrieving the information in HTML format.
- Analyzing and extracting the relevant data by parsing the textual code.
- Saving the extracted content in a preferred format such as JSON, XML, Excel, CSV, or a database. This enables easy retrieval and future use of the stored data.
Web Scraping Techniques
Web scraping isn’t as simple or complicated. With the mentioned techniques, you can scrape the web without many hurdles:
1. HTML Parsing
This technique involves parsing the HTML structure of a web page using libraries like BeautifulSoup or LXML. It allows you to navigate the document’s elements and extract data based on their tags, attributes, or CSS selectors.
2. Headless Browsers
Headless browsers, like Puppeteer or Playwright, allow you to automate browser actions programmatically. They simulate user interactions and the rendering of web pages, enabling the scraping of dynamic websites that heavily rely on JavaScript for content generation.
3. API Access
Some websites provide APIs (Application Programming Interfaces) that allow developers to access and retrieve data in a structured manner. Instead of scraping the HTML content, you can directly query the API endpoints to retrieve the desired data, usually in JSON or XML format.
4. Manual Navigation
This involves manually navigating through a website and collecting web data along the way. If the desired data is dispersed across multiple pages or is not easily accessible through automated scraping techniques, manual navigation may be preferable.
Benefits of Web Scraping
Web scraping offers several benefits across various industries and applications. Some of its key benefits include:
1. Data Extraction Efficiency
Web scraping automates data collection from the web, significantly reducing the time required compared to manual methods. It quickly traverses multiple web pages, collecting vast amounts of data in a fraction of the time.
2. Cost Savings
By automating data extraction, web scraping eliminates manual data entry, reducing the costs associated with labor and potential human error. This cost-saving advantage allows for the reallocation of resources to other essential business operations.
3. High Insightfulness
Web scraping collects diverse data from a website. This data can help businesses understand competitors, identify market trends, and track customer sentiment, aiding strategic decision-making processes.
4. Real-Time Data
Web scraping can provide real-time data ensuring the most recent information is readily available. For example, getting Amazon product prices and inventory availability in real-time. This feature is critical in sectors such as finance, where up-to-date data is essential.
5. Data Accuracy
Web scraping automates data extraction, reducing the risk of human error and increasing accuracy. Advanced tools can also manage complex data structures and formats, ensuring high reliability.
Legal and Ethical Considerations in Web Scraping
The legality of web scraping depends on several factors, such as the jurisdiction, the methods used, the type of data, and the usage of the data that is scraped. But gathering or scraping publicly available information is not illegal.
Challenges in Web Scraping
The diverse and complex nature of the internet introduces many challenges to web scraping. Some key challenges include:
1. HTML Fingerprint
Unlike browser fingerprinting, which gathers data from a wide array of browser and device characteristics, the HTML fingerprinting method focuses solely on HTML headers.
The filtering process starts with a granular inspection of HTML headers. These can indicate whether a visitor is a human or a bot, malicious or safe. Header signatures are compared against a constantly updated database of over 10 million known variants.
2. IP Reputation
Websites often use IP reputation to safeguard against malicious activities, such as spamming and unauthorized data scraping. Visits from IP addresses with a history of being used in assaults are treated with suspicion and are more likely to be scrutinized further.
To overcome this challenge, proxies are rotated and IP addresses are changed frequently. This prevents single IPs from being flagged.
3. Progressive Challenges
A set of challenges, such as cookie support and JavaScript execution, is used to filter bots and minimize false positives. A CAPTCHA challenge can also help identify and block bots that pretend to be humans.
But you can scrape websites without getting blocked by bot detection tools if certain practices are followed.
4. Behavior Analysis
Tracking the ways visitors interact with a website can reveal abnormal behavioral patterns, such as a suspiciously aggressive rate of requests and illogical browsing patterns. This helps websites detect bots that pose as human visitors and block them.
Exploring Web Crawling
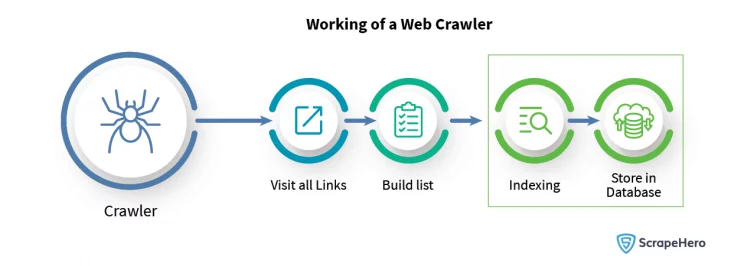
The web crawling process can be broken down into the following steps:
- Fetch the URLs provided from the crawl frontier.
- Proceed to explore each page that is linked to those URLs.
- Evaluate and categorize all web pages encountered.
- Store the collected URL data in the database by indexing it.
Applications of Web Crawling
Web crawling involves using automated scripts or programs to index data from web pages. Web crawling applications include:
1. Search Engine Indexing (Google Bot)
Web crawling is essential for search engine indexing. For instance, Google uses its web crawler, Google Bot, to scan and index billions of web pages. This indexed data is displayed when users enter search queries on Google.
2. Website Health Monitoring
Web crawling can help maintain the health of websites. Web crawlers scan websites to identify issues such as broken links or coding errors, helping to ensure optimal website performance and user experience.
3. Content Aggregation
Content aggregation sites use web crawling to collect information from various sources in a single location. For example, news aggregation sites use web crawling to pull articles from different publications, creating a single platform for diverse content.
4. Competitive Analysis
Web crawling can be used for competitive analysis by extracting data from competitors’ websites. This could include information about pricing, new product launches, and marketing strategies, providing valuable insights for strategic decision-making.
5. Crawling Policies
The actions of a web crawler are determined by a set of policies working together:
- Selection Policy
A selection policy states the pages to download, i.e., it determines which pages to download or crawl. There are different approaches to page selection, depending on the specific requirements of the crawling. Some common selection policies include:- Breadth-First Search
- Depth-First Search
- Focused Crawling
- Revisit Policy
A revisit policy states when to check for changes made to the pages, i.e., it determines when to check for changes to the previously crawled pages. Crawlers can revisit web pages periodically to detect updates, new content, or changes in existing content.
The choice of revisit policy depends on the frequency of updates on the target websites and the desired freshness of the data. - Politeness Policy
A politeness policy states how to avoid overloading websites. It governs how crawlers interact with websites to avoid overloading and respecting their resource limitations. Crawlers should be designed to be polite and avoid causing disruption or excessive load on web servers. - Parallelization Policy
A parallelization policy states how to coordinate distributed web crawlers. It addresses the coordination and management of distributed web crawlers when multiple crawlers are deployed to accelerate the crawling process.
It also involves efficient workload distribution and coordination to avoid duplicate crawling, manage shared resources, and ensure comprehensive coverage.
Challenges of Web Crawling
Even though web crawling has its own advantages, it also possesses unique challenges. Some of them are:
1. Database Freshness
A website’s content is updated regularly. Dynamic websites, for example, change their content based on the activities and behaviors of visitors. This means the website’s source code does not remain the same after you crawl the website. In order to give users the latest information, web crawlers need to crawl web pages more frequently.
2. Crawler Traps
Websites employ different techniques, such as crawler traps, to prevent web crawlers from accessing and crawling certain web pages. A crawler trap, also known as a spider trap, traps a web crawler in a vicious crawling circle by causing it to make infinite requests.
Websites may also unintentionally create crawler traps. When a crawler encounters a crawler trap, it enters something like an infinite loop that wastes the crawler’s resources.
3. Network Bandwidth
Downloading a large number of irrelevant web pages, utilizing a distributed web crawler, or recrawling many web pages all result in a high rate of network capacity consumption.
4. Duplicate Pages
Web crawler bots primarily crawl all duplicate content on the web; however, they only index one version of a page. Duplicate content makes it difficult for search engine bots to determine which version of duplicate content to index and rank.
When Googlebot discovers a group of identical web pages in search results, it indexes and selects only one of these pages to display in response to a user’s search query.
Crawling vs. Scraping – Tools Used
Various tools and software are available for web scraping. For instance: ScrapeHero Cloud. There are also many web crawling tools and frameworks available on the market, such as Apache Nutch, which you can try.
Web Scraping vs. Web Crawling – Differences

Web scraping is about extracting data from one or more known websites and focusing on specific domains without necessarily knowing the exact page URLs. Usually, you scrape 5-10-20 or more data fields.
Also, even if the URL is one, when you scrape, you extract the data not necessarily for the URL but for other data fields like product names or product prices that are displayed on the website.
Web crawling is about finding or discovering URLs or links without prior knowledge of them on the web and downloading the HTML files for future use. For example, search engines crawl the web and index pages later, displaying them in the search results.
In web data extraction projects, there is a need to combine both web crawling and web scraping. You crawl the URLs to discover them and download the HTML files. Even when you don’t have the page URLs of a specific website, you can scrape if you know the domain.
First, you create a crawler that will collect all page URLs, and then you create a scraper that extracts data fields from these pages. Once the data is scraped, you can store it in a database or use it for further processing. This way, the data that is collected through crawling is utilized through scraping. These two processes contribute to the overall data extraction workflow.
Web Scraping vs. Web Crawling – Similarities
There are many similarities between web crawling and web scraping, and they include:
- Making HTTP requests is the common way for web crawling and scraping to access data.
- Both processes are automated, which leads to more accurate data retrieval.
- Web crawlers and scrapers risk being blocked through an IP clampdown or other means.
- Despite differences in their workflows, web crawling and web scraping both involve downloading data from the web.
Wrapping Up
Web scraping and web crawling are key methods for data extraction and indexing from the web. Web scraping efficiently pulls specific data, aiding in market research and competitive analysis tasks.
On the other hand, web crawling is essential for indexing web pages, supporting search engine functions, and monitoring website health. Both web scraping and web crawling play vital roles in understanding and navigating the digital landscape.
Businesses can access web data without worrying about crawling and scraping with the help of ScrapeHero Web Scraping Service and ScrapeHero Web Crawling Service. With a decade of experience, we cater to clients from various industries.
Our clientele encompasses a diverse spectrum, including major corporations, renowned household brands, mid-sized businesses, and emerging startups. Additionally, we have established associations with prominent entities across various sectors, such as global financial corporations, the US healthcare industry, leading global management consulting firms, and the Big Four accounting firms, among others.
Frequently Asked Questions
A spider and a crawler are the same. It is a tool that is used to navigate the web and index content. A scraper is designed to extract specific data from websites for data analysis or market research.
The legality of web crawling and scraping varies by jurisdiction. It also depends on the website’s terms of service, copyright laws, and data protection regulations. Scraping publicly available data is not illegal.
Data scraping is a broad term and can be defined as the extraction of data from any source, including databases, files, and other digital formats. Web scraping is the process of extracting data from websites, utilizing the HTML structure of the web page.
After the data is extracted through web scraping, you can store it in a database. This data is later used for analysis, reporting, or integration with other systems.
In web data extraction projects, crawling is used to discover URLs and download HTML files, while scraping is used to extract the desired data from these files.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



