

You can use any programming language for web scraping, but Python remains popular because of its highly readable syntax. Moreover, its vast community has resulted in numerous libraries for web scraping. But how does web scraping work? Here is a technical guide on how to scrape websites with Python.
How to Scrape a Website with Python
Web scraping refers to extracting data from the internet without human interaction. A computer will run a program that surfs the web, gathers data, and stores it locally.
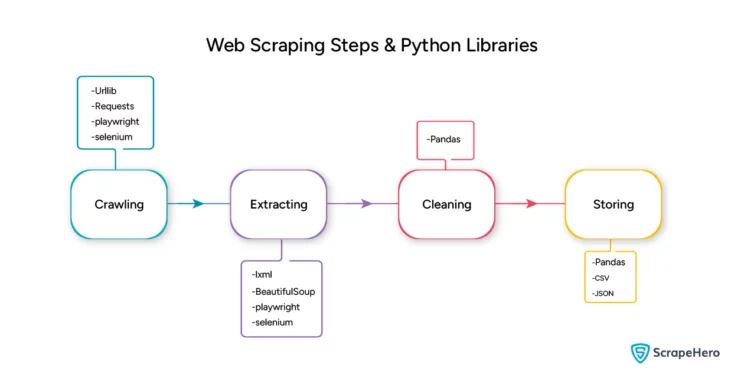
Web scraping has four primary steps:
- Crawling: The program first follows links and understands a website’s content. It indexes and may even download web pages. However, the data would be unstructured and not practical for analysis. You can omit this step if you only want to scrape from a specific web page.
- Extracting: This step converts the unstructured data into a structured, usable form. You then locate the elements from which you need data and extract the required information.
- Cleaning: The extracted data may have several issues, including inconsistencies, duplicates, corruptions, etc. Therefore, you might need to clean it to make it usable.
- Storing: After cleaning the data, the final step is to store it. You can store it in a format that is easily accessible later. Two such formats are CSV and JSON; both are popular choices for storage.
Setting up the Environment to Scrape a Website Using Python
Using Python for web scraping requires you to set the environment where you can run Python scripts. To set up the environment, you must
- Install Python
- Install pip
- Install libraries
You can download the package from their website and install both Python and pip simultaneously. After that, you can install various Python libraries with
pip install <package-name>
Python Libraries and Modules for Web Scraping
Here are some popular Python libraries used in web scraping:
- Urllib
- Requests
- lxml
- BeautifulSoup
- Pandas
- Playwright
- Selenium
- CSV
- JSON
Urllib
Urllib comes with Python’s standard library; it is a collection of four modules:
- urllib.request lets you open and read URLs
- urllib.error lets you view exceptions raised in urllib.request
- urllib.parse can convert HTML code into usable form
- urllib.robotparser understands robots.txt files
You can import them by
import urllib.request
import urllib.parse
import urllib.error
import urllib.robotparser
To open a URL using urllib.request, use the urlopen method. The code sends an HTTP GET request to the URL and gets the response.
response = urllib.request.urlopen(“https://something.com/someotherthing”)The response variable will now contain the HTML response. You can read the response text with the read() method.
responseMessage = response.read()To get the status code, use
responseStatus = response.statusYou can get the URL with
responseURL = response.urlAnd for headers, use
responseHeaders = response.headers.items()You might need to send HTTP headers with the GET request. For example, you may want to tell the server that the request originated from a user. The Request method enables you to do that.
request = urllib.request.Request(“https://something.com/somewhere”, headers= {“Referer”: “https://somdomain.com”})After getting the response, you need to parse the data and extract it using other Python libraries.
Requests
Requests is an external library; this means you must install it separately using pip.
pip install requestsImport the requests library with
import requestsYou can send GET requests using the get method; it also accepts headers.
headers = {
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Sa"
"fari/537.36",
"Accept-Language": "en-US, en;q=0.5"
}
response = requests.get(url, headers = headers)
For the status code, use the status_code method.
response_code = response.status_codeYou can get the text from the response using
responseText = response.textAgain, you will use other Python libraries to parse the response text and extract the data.
LXML
LXML is also an external library. It allows you to parse HTML code. You can install it with pip.
pip install lxmlNow import the HTML class from the lxml library.
from lxml import htmlYou can now parse the response text of an HTTP request.
parser = html.fromstring(response_text)You can get any element using its XPath. For example, the code below extracts the text of an h3 element with the class “item_title.”
title = parser.xpath(‘.//h3[contains(@class,"item__title")]//text()’)BeautifulSoup
Now, LXML can quickly get you the desired HTML element. However, the XPath syntax is tedious to use. Web scraping using Python BeautifulSoup is much more convenient.
BeautifulSoup offers several methods to extract the HTML elements that are more intuitive than XPaths.
You can install BeautifulSoup with pip.
pip install beautifulsoup4Then you can import the library using
from bs4 import BeautifulSoupAfter that, you can parse any HTML code by calling BeautifulSoup and passing the code as an argument. You can also specify the parser you want to use; otherwise, BeautifulSoup will choose the best-installed parser.
soup = BeautifulSoup(html_code, ‘lxml’)BeautifulSoup accepts a “parent.child” syntax. For example, you can get an h3 element inside a div element using
soup.div.h3There are three ways to get the corresponding text.
soup.div.h3.string
soup.div.h3.text
soup.div.h3.get_text()You can also search for all the tags of a specific kind using the find_all method. It gets a list of h3 tags as an array.
soup.h3.find_all()To get the HTML of tags, you can use the str() method.
str(soup.div.h3)You can also use CSS selectors to locate elements.
soup.select('p.name span')The above code gets the span object inside a p element with a class name.
Pandas
Pandas is the best option if you only want to extract tables from an HTML page. Its method, read_html, makes extracting tables very convenient.
You can install Pandas using
pip install pandas Then import Pandas.
import pandas as pdNow, you can read a table from an HTML page by specifying the URL.
tables = pd.read_html(‘https://sampleurl.com/samplepath’)The above code returns all the tables as an array. You can get each table by specifying the index.
tableZero = table[0]The read_html() function accepts various arguments to process and filter data. For example,
pd.read_html(url,match='Rank',skiprows=list(range(21,243)),index_col = 'Rank',converters = {'Date': get_year },keep_default_na=False)Here,
- url specifies the URL from which you want to get the tables.
- match selects the tables that have a header named “Rank.”
- skiprows skips the specified rows.
- index_col sets the index column of the table.
- converters lets you process information directly.
- Here, Pandas will use a get_year function that gets the year from the date.
- keep_default_na=False replaces the NaN values with an empty string.
Playwright
All the above libraries directly access webpages using HTTP requests. However, those methods may fail because of server restrictions. Libraries like Playwright can overcome these problems by using a full-fledged browser.
Playwright uses a Chromium browser to access the internet. It can run in headless and headful modes. A headless mode does not show you the execution of the Playwright. On the other hand, you can see what Playwright does in the headful mode.
You can install Playwright with pip.
pip install playwrightThen, you must install the Playwright browser.
playwright installTo import Playwright, use the code below. You must also import the asyncio for executing Playwright asynchronously.
from playwright.async_api import async_playwright
import asyncio
To launch the Playwright browser, use
browser = await playwright.chromium.launch(headless=False)In the above code, headless=False represents that the execution is headful. Use headless=True for a headless execution.
Now, create a new browser context.
context = browser.new_context()The next step is to create a new page.
page = await context.new_page()To navigate to a URL, use
await page.goto(‘https://scrapeme.live/shop’)To select an element, you can use the query_selector_all() method. It selects all the elements for a given selector. For example, select all the URLs from the website with the class product with the li.product selector.
all_elements = await page.query_selector_all(‘li.product’)The above code will return a list; if you want to get only one element, use
one_element = await page.query_selector(‘h2’)To get the text, you can use the inner_text() method
element_text = one_element.inner_text()You can also perform actions such as click, fill, tap, etc. For that, use the locator() method. This function accepts RegEx, XPath, and CSS selectors. Use the following steps to click on an element with the text “Search”:
- Locate the element
element = page.locator(“text=Search”) - Click on the element
await element.click()
You may need to wait for some time before your selector loads. The wait_for_selector() method ensures that the program waits until the selector gets loaded on the web page.
Finally, you must close both the browser and the context after your operations.
await context.close()
await browser.close()Selenium
You saw that you must install the Playwright browser to use Playwright. However, Selenium allows you to use Chrome, Firefox, Safari, or Opera.
Install Selenium using
pip install -U seleniumUse the import statements to import the necessary classes from the Selenium library.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import ByNext, you can open the browser with
browser = webdriver.Chrome()To go to a specific page, use
page = browser.get(‘https://somesite.com’)You can then select any element.
element = page.find_element(By.TAG_NAME, ‘p’)Here, you used TAG_NAME; however, you can use other locators:
- ID
- NAME
- XPATH
- LINK_TEXT
- PARTIAL_LINK_TEXT
- TAG_NAME
- CLASS_NAME
- CSS_SELECTOR
After selecting an element, you can extract the text.
element.textOr, you can click on it if it is a link.
element.click()If the element is a text-input field, type in it using the send_keys method.
element.send_keys(‘Sample words you can type’)You can also send keyboard actions to interactive elements, such as search boxes. For example, press the return key after typing in a search box using
element.send_keys(Keys.RETURN)
CSV
CSV is an in-built module in the Python standard library. It allows you to read and write CSV files; you can use it to store the extracted data. To import the library, write
import csvYou can read a CSV file using
sampleFile = open(“sample.csv”)
reader= csv.reader(sampleFile)To write a file, you can use the csv.writer() method
newFile = open(“newFile.csv”)
writer = csv.writer(newFile)
writer.writerow([“value1”,”value2”,”value3”])JSON
JSON is another module from the Python standard library that enables encoding and decoding JSON files. You can use json.load() to read a JSON file.
file = open(“file.json”)
jsonFile = json.load(file)You can write a JSON object with json.dump(). Suppose data is the object you wish to write. Then,
outFile = open(“newFile.json”)
json.dump(data, outFile)The above code writes the data object into a JSON file named newFile.json.
There you go! You read about some of the popular Python libraries for web scraping. Next, you can check out these in-depth tutorials:
They will show you how Python libraries and modules work together to scrape data from a website.
Anti-Scraping Measures
Now that you know how to web scrape with Python, it’s essential to know about anti-scraping measures.
Web scrapers and crawlers can access content from websites very quickly. You can overload their servers if you perform web scraping irrationally. Moreover, websites love human traffic. Therefore, they make it difficult for bots to access their sites. The most common methods are
- Varying Layouts: Web scrapers locate elements using XPaths or CSS selectors. These depend on the structure. Therefore, web scrapers will not locate elements if websites frequently change layouts.
- CAPTCHA: They are a type of test that can tell humans and computers apart. CAPTCHAs may not present themselves every time. Websites may only demand that you solve CAPTCHAs when they suspect the traffic is not of human origin.
- Rate Limiting: When a website only allows a certain number of requests per second, it is called rate limiting. Rate limiting ensures you don’t overload their servers.
- IP Blocking: This anti-scraping measure is the strictest of all. A website may block your IP address, preventing you from accessing it. IP blocking is only an extreme case and usually has an expiry.
You can overcome these measures to some extent and scrape without getting blocked. For example, while data scraping with Python, you can
- make your web scraper capable of extracting details from multiple layouts. That means your program will become more complicated.
- use CAPTCHA solvers that use optical character recognition (OCR). Moreover, vary your crawling algorithms to make it seem like user-generated traffic so that you may avoid CAPTCHAs.
- use Virtual Private Networks (VPNs) to rotate your IP to overcome rate limiting and IP blocking. VPNs allow you to pose as a different traffic source each time.
- ‘User-Agent’ headers to specify that the request is from a user.
Conclusion
Python is an excellent choice for web scraping because of its readability and its numerous libraries for web scraping. In this guide, you read how to scrape a website using Python libraries. Some libraries are for sending requests to the servers, while others help you parse HTML data.
You also read that websites employ anti-scraping measures and that there are ways to overcome them.
However, web scraping is a technical skill, and all these methods require advanced programming knowledge. You can avoid coding yourself by using web scraping services like ScrapeHero. ScrapeHero services include large-scale crawling, data extraction, and many more. Leave coding to us; we will build enterprise-grade web scrapers customized to your needs.
Are you looking for a ready-made solution? Try an affordable ScrapeHero web scraper from ScrapeHero Cloud. Make an account, choose a web scraper, and instruct what to scrape. With just a few clicks, you can get high-quality data.
FAQ
-
How do I practice web scraping in Python?
One way to learn how to scrape data from a web page using Python is to use Google Colab. It is a cloud environment specially designed for coding in Python. You can also set up a Python environment on your computer once you become familiar with web scraping.
-
What are good Python web scraping tutorials?
You can check out these Python tutorials on our website. They will show you how to scrape data from a website using various Python libraries.
-
Is web scraping legal?
Scraping publicly available data is legal, which is what Google does. However, scraping personal data that is behind a login page or paywall is illegal.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data


