

When web scraping you often come across HTML tables in the pages. But how can you extract this tabular data? Web scraping using Pandas is the solution. A method called read_html, is used to read tables from websites using Pandas. You can pass the HTML content or the URL to a web page with tabular data directly.
This article explores in detail about scraping tabular data with Pandas. Let’s start with a basic example.
- Load the first table with population data for countries from the List of countries and dependencies by population into a Pandas DataFrame.
- Get the top 20 countries.
- Make the Rank column the index.
- Replace all NaN values with an empty string.
- Extract the year from the Date column.

Before you begin web scraping using Pandas, make sure you have these packages installed in Python:
- Pandas
- LXML
To install them:
pip install pandas lxml
Loading a Specific Table Using String or RegEx Matching
For scraping tabular data with Pandas, you must first load a specific table from a page with multiple tables using string or RegEx matching. For this, import the required libraries first.
# Import pandas
import pandas as pdNow, read the table from the webpage using read_html.
# Fetch all the tables present in the HTML content
url = 'https://scrapeme.live/population-data.html'
all_tables = pd.read_html(url)If you check the length of the all_tables object, you can see that Pandas has created two DataFrames, one for the population data table and another for the population statistics table below it.
# Check the length of tables list
print(len(all_tables))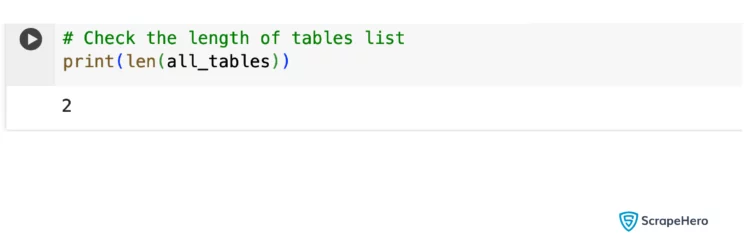
You have multiple tables now. But how can you get just the required table (the first table) from the webpage?
In this example, you can just use all_tables[0] to get the first table. But that wouldn’t always be the case with other web pages that may have multiple HTML tables.
# Check the first table
all_tables[0]![Using all_tables[0] to get the first table when web scraping using Pandas.](https://www.scrapehero.com/wp/wp-content/uploads/2024/01/Using-all_tables0-to-get-the-first-table-744x401.webp)
# Check the second table
all_tables[1]![Using all_tables[1] to get the second table when web scraping using Pandas.](https://www.scrapehero.com/wp/wp-content/uploads/2024/01/Using-all_tables1-to-get-the-second-table-744x378.webp)
The read_html function has a parameter called match, which can be used to extract only those tables that match a certain string or Regular Expression.
# Fetching tables with the matching keyword
all_tables = pd.read_html(url,match='Rank')Use the keyword “Rank” found on the table header to filter out all other tables. You just need to use a string or regex that is not common to other tables in the HTML page.
![]()
# Check the length of table
print(len(all_tables))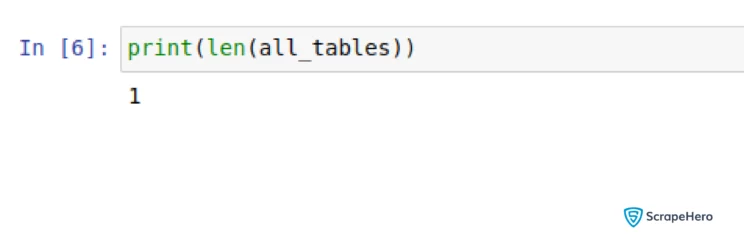
You will just have 1 table.
Limit the Number of Rows Extracted
There are 241 rows in total. Limit the data to the first 20 rows. Here, you could use the head method of the resulting DataFrame. But let’s try another way. Use parameter skiprows, which takes an integer or a list as arguments, skipping any number of rows from the extracted table.
# fetch the required table with the first 20 rows
all_tables = pd.read_html(url,match='Rank',skiprows=list(range(21,243)))Set the Index of the DataFrame Directly in read_html
Set the Rank as the index of the DataFrame. You can always do this later by using the set_index method of a DataFrame. Interestingly, read_html has a parameter called index_col which takes in the name of the index column, and sets it as index.
# Setting Rank column as index column
all_tables = pd.read_html(url,match='Rank',skiprows=list(range(21,243)),index_col = 'Rank')![]()
Transform a Column Using Converter Functions
The column date is in the form of Date, Month and Year. To get only the Year, convert the Date column. For this, use the parameter converter to actively input a dictionary. Here, the key is the column name that you need to transform, and the value is a function that takes a single argument, which is the cell content.
# Transforming the Date column
from datetime import datetime
def get_year(data_string):
return datetime.strptime(data_string, '%d %b %Y').year
all_tables = pd.read_html(url,match='Rank',skiprows=list(range(21,243)),index_col = 'Rank',converters = {'Date': get_year })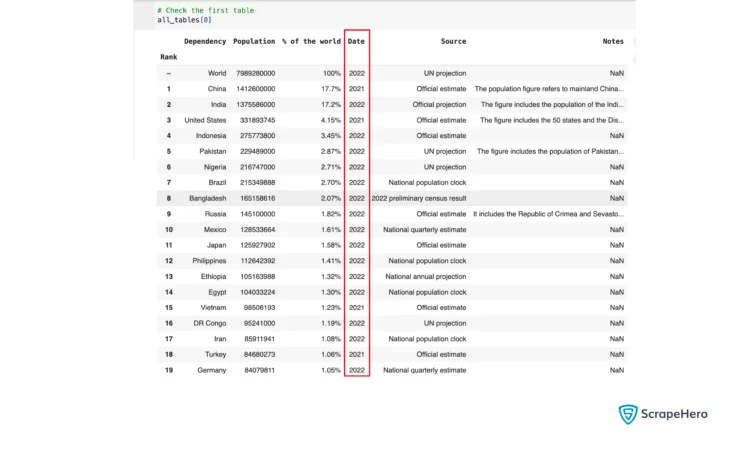
Parsing Dates
You can also use the parameter parse_dates to change the date format.
# Make column Date into Date data type
all_tables = pd.read_html(url,match='Rank',skiprows=list(range(21,243)),index_col = 'Rank',parse_dates=[4])Replacing NaN With Empty String
You can see some NaN values in the dataset, which represent empty values. Remove the NaN values with custom values by using the parameter keep_default_na. For example:
# Replace NaN fields
all_tables = pd.read_html(url,match='Rank',skiprows=list(range(21,243)),index_col = 'Rank',converters = {'Date': get_year },keep_default_na=False)Exporting to CSV
After scraping tabular data with Pandas, write it into a CSV file so that it will open in Excel sheet. Pandas supports exporting data into multiple formats, such as JSON, CSV, Excel, and HTML. Write the data into a CSV file, population_data.csv.
# getting the required table from list
population_table = all_tables[0]
# saving CSV in the current working directory
population_table.to_csv('population_data.csv', index=False)You can exclude the index column(Rank) from the CSV by setting the parameter index to False.
Here are some more features of read_html in Pandas that you must understand.
Using HTML Content Instead of URL in read_html
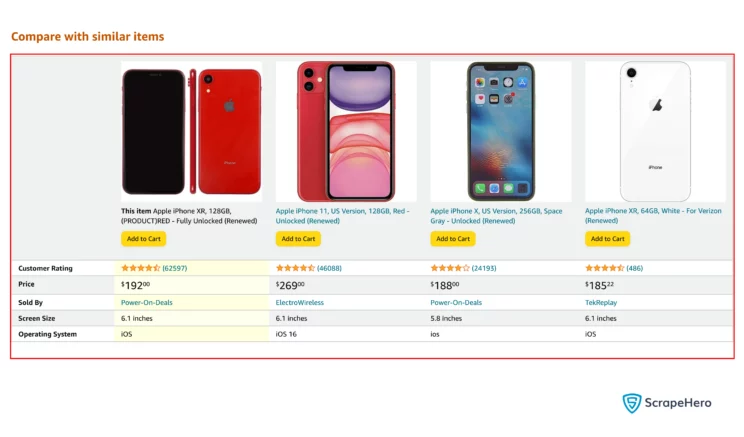
This time, let’s scrape a table with product comparison data from the website Amazon.com.
Let’s first try to fetch the table from the URL using the read_html() method.
# Fetch all the tables present in the HTML content
url = 'https://www.amazon.com/Apple-iPhone-Fully-Unlocked-128/dp/B07P611Q4N'
all_tables = pd.read_html(url)Instead of a list of tables, an HTTP 503 Error is shown.
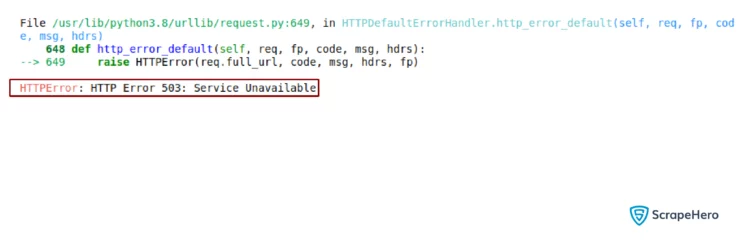
As you can see, the error is returned from the urllib module. The read_html() method uses urllib to send requests. This 503 error happens because Amazon.com knows this request is not coming from a browser, as it doesn’t have any of the needed HTTP headers.
This may also occur due to the website blocking access using anti-scraping measures, which may not be as simple to fix.
For this problem, there is a simple fix: tell Amazon that you are using a browser by passing certain browser-specific HTTP headers. But Pandas does not let you change the HTTP headers.
So, use the Python Requests library to first download the HTML with the right set of HTTP headers, and then give just the downloaded HTML content of the page to Pandas to parse and read the tables.
To install requests:
pip install requests
# HTTP request to amazon using python requests module
import requests
# define the headers required
headers = {
'authority': 'www.amazon.com',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-language': 'en-GB,en-US;q=0.9,en;q=0.8',
'cache-control': 'no-cache',
'device-memory': '8',
'downlink': '10',
'dpr': '1',
'ect': '4g',
'pragma': 'no-cache',
'rtt': '100',
'sec-ch-device-memory': '8',
'sec-ch-dpr': '1',
'sec-ch-ua': '"Chromium";v="106", "Google Chrome";v="106", "Not;A=Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Linux"',
'sec-ch-viewport-width': '1920',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36',
'viewport-width': '1920',
}
# http request with headers
response = requests.get(url, headers=headers)
# checking the status code and obtaining the html response content
if(response.status_code == 200):
html_content = response.textNow, pass the HTML content to Pandas read_html() and extract the required table.
# fetching all the tables in html content passed
all_tables = pd.read_html(html_content)Load a Specific Table From a Page With Multiple Tables Using HTML Attributes
Check the number of tables extracted.
# Check the length of tables list
print(len(all_tables))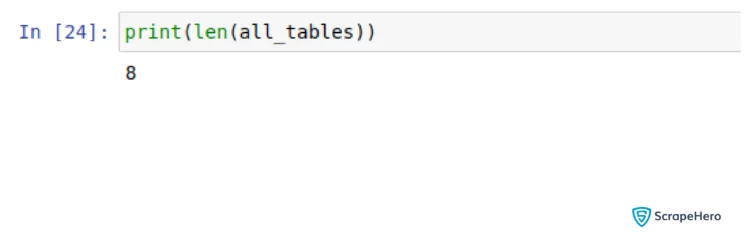
You can observe that many unwanted tables are being fetched. To get the required table, you can use the parameter attrs. This parameter takes a dictionary of HTML attributes that can be used to identify the table from the HTML content.
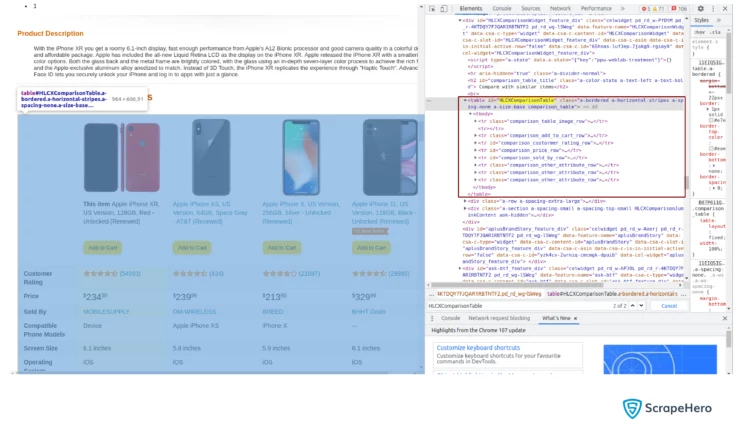
From the screenshot, you can see that the required table has an attribute id which is HLCXComparisonTable. This can be used to identify the table in the HTML content.
# fetching the required table
all_tables = pd.read_html(html_content,attrs={'id': 'HLCXComparisonTable'})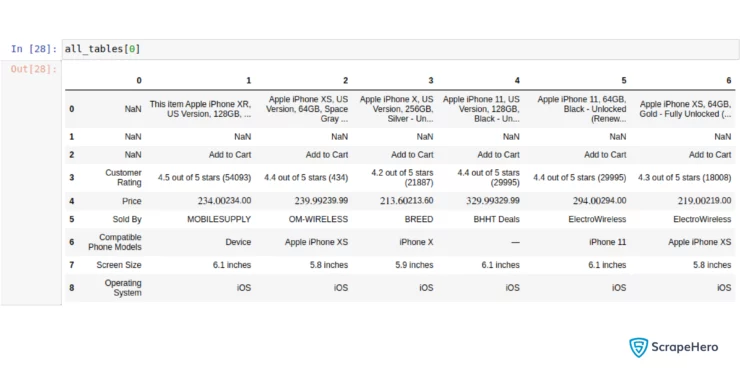
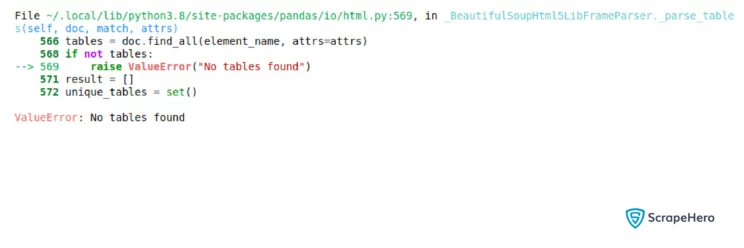
If the attributes (attrs) are not matching with any table in the HTML content, Pandas will raise a Value Error saying no tables found. For example:
# fetching the required table
no_tables = pd.read_html(html_content,attrs={'id': 'table_name_not_to_be_found'})Here, table id should match table_name_not_to_be_found which is not present in the webpage.
Exporting to JSON
The data is ready after web scraping using Pandas. Let’s write it into a JSON file – Comparison_table.json.
# Getting the required table from list
comparison_tables = all_tables[0]
# saving JSON in the current working directory
comparison_tables.to_json('Comparison_table.json', index=False)Wrapping Up
Web scraping using Pandas is primarily useful for extracting basic HTML tables from a web page if you just need a few pages. This article has already covered all the important aspects of how to scrape websites using Pandas.
If you need to extract data that is not tabular or scrape data from thousands of pages, this method is not recommended. In such cases, instead of Pandas, you can use Python packages such as LXML or BeautifulSoup.
You can also make use of ScrapeHero Cloud, which offers pre-built crawlers and APIs if you have specific web scraping needs, like scraping Airbnb listings. It is affordable, fast, and reliable, offering a no-code approach to users without extensive technical knowledge.
For enterprise-grade scraping, it is better that you consult ScrapeHero to meet your needs. ScrapeHero web scraping services are bespoke, custom, and more advanced, and we provide these services to all industries globally.
Frequently Asked Questions
-
Can Pandas be used for web scraping?
Yes. Web scraping using Pandas is possible, but with some limitations. It is not suitable for scraping non-table data from web pages.
-
Why can’t you scrape some tables using Pandas?
If the table is nested within complex HTML structures or is loaded dynamically with JavaScript, if the URL is incorrect, or if the website prevents scraping, then you may not be able to scrape some tables using Pandas.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



