
eBay is the second most visited online marketplace; It gets around 1.2 billion monthly visitors. Therefore, you can get plenty of insights into your competitors and your brand if you scrape data from eBay. In this tutorial, you can learn how to scrape eBay listings using Python.
Data Extracted by Scraping eBay
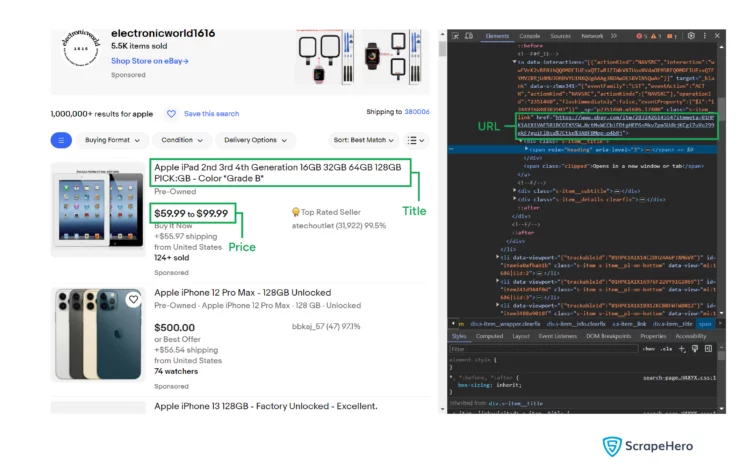
Here, you will scrape data from eBay to get three pieces of information.
- Price
- Title
- URL
To locate these, you must analyze the webpage and understand the XPaths. You can use the developer options to figure them out.
Set up the environment
To scrape eBay with Python, you must first set up the environment by installing Python and the necessary packages. This Python script to search eBay uses three external libraries.
- requests
- Unicodecsv
- lxml
You can install them using Python pip.
pip install requests unicodecsv lxmlScrape eBay Listings: The Code
The first part of the code to scrape data from eBay contains import statements. These will allow you to use the libraries and the modules.
import argparse
import requests
import unicodecsv as csv
from lxml import html
Here,
- argparse allows you to make your script accessible from the command line
- unicodecsv enables you to read and write CSV
- requests can send HTTP requests and receive response
- lxml can parse HTML code
The code has one defined function, parse(). Its purpose is to
1. Accept a brand name
This code gets the brand name from the user as a command line argument. You use the argparse module for that.
2. Send requests to eBay and get a response
The next step is to use requests to send HTTP requests. You also send headers along with the HTTP request; these headers tell the eBay server that the request originated from a legitimate user.
3. Scrape products from the response
The code then uses the html.fromstring() method of parsing the response text, which is the source code.
The function uses XPaths to locate an element. The XPath syntax allows you to locate any HTML element; however, you must analyze the webpage’s structure.
Your browser’s developer options can help you find the HTML code of any element, which will help you figure out the XPaths. For example,
raw_title = product.xpath('.//div[contains(@class,"s-item__title")]//text()')The above code gets the text inside a div element with the class “s-item_title”
4. Return the scraped data
After data extraction, the function returns the scraped data as an array.
def parse(brand):
url = 'https://www.ebay.com/sch/i.html?_nkw={0}&_sacat=0'.format(brand)
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'}
failed = False
# Retries for handling network errors
for _ in range(5):
print ("Retrieving %s"%(url))
response = requests.get(url, headers=headers, verify=False)
parser = html.fromstring(response.text)
print ("Parsing page")
if response.status_code!=200:
failed = True
continue
else:
failed = False
break
if failed:
return []
product_listings = parser.xpath('//li[contains(@class,"s-item")]')
raw_result_count = parser.xpath("//h1[contains(@class,'count-heading')]//text()")
result_count = ''.join(raw_result_count).strip()
print ("Found {0} for {1}".format(result_count,brand))
scraped_products = []
for product in product_listings:
raw_url = product.xpath('.//a[contains(@class,"s-item__link")]/@href')
raw_title = product.xpath('.//div[contains(@class,"s-item__title")]//text()')
raw_product_type = product.xpath('.//h3[contains(@class,"item__title")]/span[@class="LIGHT_HIGHLIGHT"]/text()')
raw_price = product.xpath('.//span[contains(@class,"s-item__price")]//text()')
price = ' '.join(' '.join(raw_price).split())
title = ' '.join(' '.join(raw_title).split())
product_type = ''.join(raw_product_type)
title = title.replace(product_type, '').strip()
data = {
'url':raw_url[0],
'title':title,
'price':price
}
scraped_products.append(data)
return scraped_productsAll eBay products are public, and scraping public data is legal. However, eBay does not allow bots to access its site and may block you. That is why the above code uses the headers of a legitimate user while sending an HTTP request.
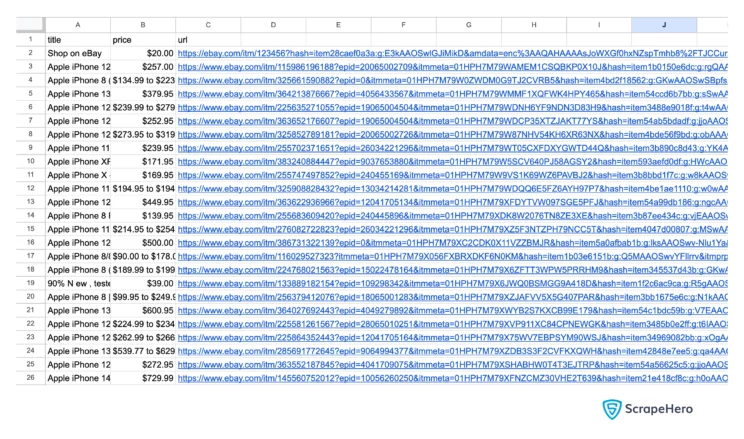
Finally, you will set up the code to accept arguments from the command line and call parse(). The function parse() will return parsed data that you will write to a CSV file using the writerow() method.
if __name__=="__main__":
argparser = argparse.ArgumentParser()
argparser.add_argument('brand',help = 'Brand Name')
args = argparser.parse_args()
brand = args.brand
scraped_data = parse(brand)
if scraped_data:
print ("Writing scraped data to %s-ebay-scraped-data.csv"%(brand))
with open('%s-ebay-scraped-data.csv'%(brand),'wb') as csvfile:
fieldnames = ["title","price","url"]
writer = csv.DictWriter(csvfile,fieldnames = fieldnames,quoting=csv.QUOTE_ALL)
writer.writeheader()
for data in scraped_data:
writer.writerow(data)
else:
print("No data scraped")In the above code, the argparse parse module parses the arguments passed during execution and passes them to the brand variable.
You can ignore the first value. The website has a hidden element with a similar XPath as that of the product listings.
How to Use the Script
You can paste the code into a file and save it with the py extension. For example, let’s say you save the file as ebay_scraper.py. You can then use the command line to scrape Apple products.
python ebay_scraper.py apple You can also use -h option with the script to understand the syntax
usage: ebay_scraper.py [-h] brand
positional arguments:
brand Brand Name
optional arguments:
-h, --help show this help message and exit
The code limitations
There are two primary limitations of the code.
You can use this code to scrape competitor prices from eBay for now. However, eBay changes the site’s structure frequently. The code will fail to locate the elements whenever that happens.
That means you must reanalyze the website source code and find the new XPaths.
Another problem is that the code is not suitable for large-scale web scraping. eBay might block your IP when you scrape a large number of data sets. Therefore, you must use proxy rotation to address that.
Proxy rotation involves changing your IP address after you scrape a certain amount of data. This script does not use proxy rotation.
In Summary
You can scrape eBay listings using Python. The libraries, requests, and lxml, together, enable you to make HTTP requests and parse the response.
However, you must update the code whenever eBay changes its structure. When the structure changes, the XPath also changes, and you must figure out the new XPaths again by analyzing the HTML code.
You also need to extend the code to perform large-scale web scraping to bypass the anti-scraping measures, like rate limiting. But this would require knowledge of IP rotation. Try ScrapeHero services if you want to avoid learning all this.
ScrapeHero is a full-service web scraping service provider. We can create customized enterprise-grade web scrapers for you, including an eBay web scraper. You can stop worrying about learning how to scrape eBay listings yourself.



