Most modern websites prevent scraping by blocking bots when they are detected. Various techniques are implemented to overcome such blocking.
This article solely focuses on one such technique: IP rotation. You will also learn some essential tips for using proxies and rotating IP addresses.
Techniques To Prevent Blocking by Websites
Before diving deep into the technique of IP rotation, let’s get an overview of some standard methods that prevent websites from getting blocked by websites while scraping.
- Rotating IP Addresses
- Using Proxies
- Rotating and Spoofing User-Agents
- Using Headless Browsers
- Reducing the Crawling Rate
Rotating Proxies and Static Proxies
Rotating proxies are proxies that assign different IP addresses for every connection from a large pool of proxies.
So, for 1000 requests, 1000 different IP addresses are assigned, thus bypassing anti-scraping measures. Rotating proxies change the IP addresses at regular intervals.
Meanwhile, static proxies are proxies that access the web from a single IP address. When a static proxy is used, the IP address will remain constant for all subsequent requests throughout the entire session.
Usually Datacenter and ISP proxies are static as they are hosted on always-online servers with fixed IPs.
How To Send Requests Through a Proxy in Python Using Requests
If you are using Python-Requests, you can send requests through a proxy by configuring the proxies argument. For example:
import requests
proxies = {
'http': 'http://10.10.1.10:3128',
'https': 'http://10.10.1.10:1080',
}
requests.get('http://example.org', proxies=proxies)
Finding a Proxy
There are many websites dedicated to providing free proxies on the internet. One such site is Free Proxy List. From this site, let’s pick a proxy that supports https.
The proxy chosen is–
IP: 207.148.1.212 Port: 8080
Note: This proxy might not work when you test it. In that case pick another proxy from the website.
Request HTTPBin’s IP endpoint and test if the request went through the proxy.
import requests
url = 'https://httpbin.org/ip'
proxies = {
"http": 'http://209.50.52.162:9050',
"https": 'http://209.50.52.162:9050'
}
response = requests.get(url,proxies=proxies)
print(response.json())
{'origin': '209.50.52.162'}
You can see that the request went through the proxy. Now, send requests through a pool of IP addresses.
Rotating Requests Through a Pool of Proxies in Python
Gather a list of some active proxies from the Free Proxy List. You can also use private proxies if you have access to them.
Whether you prefer the flexibility of manual copy and paste or the control of automation through a scraper, you can create your list of proxies.
You can write a script to grab all the necessary proxies and construct this list dynamically every time you initialize your web scraper.
Here’s the code to pick up IPs automatically by web scraping. Note that the code could change when the website updates its structure.
import requests
from lxml.html import fromstring
def get_proxies():
url = 'https://free-proxy-list.net/'
response = requests.get(url)
parser = fromstring(response.text)
proxies = set()
for i in parser.xpath('//tbody/tr')[:10]:
if i.xpath('.//td[7][contains(text(),"yes")]'):
#Grabbing IP and corresponding PORT
proxy = ":".join([i.xpath('.//td[1]/text()')[0], i.xpath('.//td[2]/text()')[0]])
proxies.add(proxy)
return proxies
The function get_proxies will return a set of proxy strings that can be passed to the request object as proxy config.
proxies = get_proxies()
print(proxies)
{'121.129.127.209:80', '124.41.215.238:45169', '185.93.3.123:8080', '194.182.64.67:3128', '106.0.38.174:8080', '163.172.175.210:3128', '13.92.196.150:8080'}
Now that you have the list of Proxy IP Addresses in a variable proxy, you can rotate it using a Round-Robin method.
import requests
from itertools import cycle
import traceback
#If you are copy pasting proxy ips, put in the list below
#proxies = ['121.129.127.209:80', '124.41.215.238:45169', '185.93.3.123:8080', '194.182.64.67:3128', '106.0.38.174:8080', '163.172.175.210:3128', '13.92.196.150:8080']
proxies = get_proxies()
proxy_pool = cycle(proxies)
url = 'https://httpbin.org/ip'
for i in range(1,11):
#Get a proxy from the pool
proxy = next(proxy_pool)
print("Request #%d"%i)
try:
response = requests.get(url,proxies={"http": proxy, "https": proxy})
print(response.json())
except:
#Most free proxies will often get connection errors. You will have to retry the entire request using another proxy to work.
#You can just skip retries as its beyond the scope of this tutorial and you are only downloading a single url
print("Skipping. Connection error")
Request #1
{'origin': '121.129.127.209'}
Request #2
{'origin': '124.41.215.238'}
Request #3
{'origin': '185.93.3.123'}
Request #4
{'origin': '194.182.64.67'}
Request #5
Skipping. Connection error
Request #6
{'origin': '163.172.175.210'}
Request #7
{'origin': '13.92.196.150'}
Request #8
{'origin': '121.129.127.209'}
Request #9
{'origin': '124.41.215.238'}
Request #10
{'origin': '185.93.3.123'}
Request #5 had a connection error, probably because the free proxy you grabbed was overloaded with users trying to get their proxy traffic through.
Complete Code
from lxml.html import fromstring
import requests
from itertools import cycle
import traceback
def get_proxies():
url = 'https://free-proxy-list.net/'
response = requests.get(url)
parser = fromstring(response.text)
proxies = set()
for i in parser.xpath('//tbody/tr')[:10]:
if i.xpath('.//td[7][contains(text(),"yes")]'):
proxy = ":".join([i.xpath('.//td[1]/text()')[0], i.xpath('.//td[2]/text()')[0]])
proxies.add(proxy)
return proxies
#If you are copy pasting proxy ips, put in the list below
#proxies = ['121.129.127.209:80', '124.41.215.238:45169', '185.93.3.123:8080', '194.182.64.67:3128', '106.0.38.174:8080', '163.172.175.210:3128', '13.92.196.150:8080']
proxies = get_proxies()
proxy_pool = cycle(proxies)
url = 'https://httpbin.org/ip'
for i in range(1,11):
#Get a proxy from the pool
proxy = next(proxy_pool)
print("Request #%d"%i)
try:
response = requests.get(url,proxies={"http": proxy, "https": proxy})
print(response.json())
except:
#Most free proxies will often get connection errors. You will have to retry the entire request using another proxy to work.
#You can just skip retries as its beyond the scope of this tutorial and you are only downloading a single url
print("Skipping. Connection error")
6 Essential Tips for Using Proxies and Rotating IP Addresses
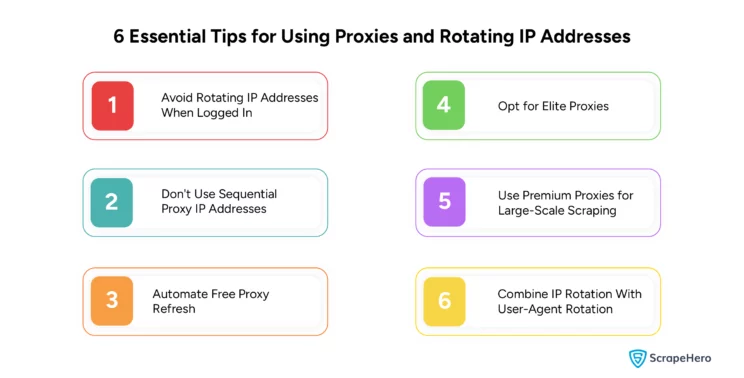
1. Avoid Rotating IP Addresses When Logged In
Do not rotate the IP address when scraping websites after logging in or using sessions. The website already knows who you are when you log in through the session cookies it sets.
To maintain the logged-in state, you must keep passing the session ID in your cookie headers.
The servers can tell whether you are a bot when the same session cookie comes from multiple IP addresses and can block you.
A similar logic applies if you send back that session cookie to a website. The website already knows this session uses a particular IP and a User-Agent.
Rotating these two fields would do you more harm than good.
So, using a single IP address and maintaining the exact request headers for each unique login is better.
2. Don’t Use Sequential Proxy IP Addresses
Avoid using proxy IP addresses that are in a sequence.
Even the simplest anti-scraping plugins can detect that you are a scraper if the requests come from IP addresses that are continuous or belong to the same range like:
64.233.160.0
64.233.160.1
64.233.160.2
64.233.160.3
Some websites have gone as far as blocking entire providers, like AWS, and have even blocked entire countries.
3. Automate Free Proxy Refresh
Automate picking up and refreshing your proxy list to save time and avoid disruptions.
Free proxies often expire quickly, mostly days or hours before the scraping even completes.
To prevent the expiry of proxies from disrupting your scrapers, write some code that automatically picks up and refreshes the proxy list you use for scraping with working IP addresses.
This will also save you a lot of time!
4. Opt for Elite Proxies
Use elite proxies whenever you are using free/ paid proxies. All proxies aren’t the same.
There are three main types of proxies available on the internet.
4.1. Transparent Proxy
A transparent proxy is a server between your computer and the internet that redirects your requests and responses without modifying them.
Transparent proxies send your actual IP address in the HTTP_X_FORWARDED_FOR header.
A website not only determines your REMOTE_ADDR but also checks for specific proxy headers that will still know your IP address.
The HTTP_VIA header is also sent, revealing that you are using a proxy server.
4.2. Anonymous Proxy
An anonymous proxy does not send your IP address in the HTTP_X_FORWARDED_FOR header.
Instead, it submits the IP address of the proxy, or it’ll just be blank.
The HTTP_VIA header is sent with a transparent proxy, which would reveal you are using a proxy server.
An anonymous proxy server does not tell websites your real IP address anymore, which can be helpful for maintaining privacy on the Internet.
The website can still see you are using a proxy server, but in the end, it doesn’t matter as long as the proxy server does not disclose your IP address.
An anonymous proxy server will be detected and blocked if someone wants to restrict page access.
4.3. Elite Proxy
An elite proxy only sends the REMOTE_ADDR header while the other headers are empty.
It will make you seem like a regular internet user not using a proxy.
An elite proxy server is ideal to pass any internet restrictions and protect your privacy to the fullest extent.
You will seem like a regular internet user who lives in the country where your proxy server is running.
Elite proxies are your best option as they are hard to be detected. Use anonymous proxies if it’s just to keep your privacy on the internet.
Only use transparent proxies as the last choice, although the chances of success are meager.
5. Use Premium Proxies for Large-Scale Scraping
If you are scraping thousands of pages, get premium proxies.
Free proxies on the internet are constantly abused and end up on blocklists used by anti-scraping tools and web servers.
For large-scale web scraping, you should pay for good proxies. Many providers will even rotate the IPs for you.
6. Combine IP Rotation With User-Agent Rotation
Use IP rotation in combination with rotating User-Agents. IP rotation on its own can help you get past some anti-scraping measures.
If you are banned even after using proxy rotation, a good solution is adding header spoofing and rotation.
Wrapping Up
Proxies can hide your IP addresses and help you navigate web traffic. Rotating proxies are vital in web scraping as they securely rotate the IP addresses of the requests, assisting in overcoming anti-scraping methods employed by websites.
Building and maintaining proxies can be time-consuming and complex, impacting your data extraction flow. Purchasing proxy pools from commercial services is convenient but costly and less customizable for large-scale operations.
In such instances, you can avail of ScrapeHero web scraping services to ensure reliable data extraction. Our expertise in efficient IP management and advanced anti-detection techniques ensures that all your data needs, which power your business, are met.
Frequently Asked Questions
To rotate IP addresses in Python you can use the `requests` library along with a list of proxy IPs. Cycle through this list for each request by updating the `proxies` parameter in your request settings.
Use free proxy lists and automate their rotation with a script. Note that free proxies are less reliable and are blocked often.
Use libraries such as`requests’ or `http.client’ to configure the HTTP requests to route through a proxy server. Specify the proxy address request settings to route traffic through it.
To make rotating proxies, compile a list of proxy servers and use a script to switch proxies for each request.
A rotating 4G proxy dynamically provides different IP addresses using mobile networks. IPs are changed at intervals or after each request, effectively mimicking real user behavior.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



