

Web Crawling Service
Web crawling at scale, optimized for enterprises
Transform your data into actionable insights with our bespoke AI solutions
3000 Pages per Second
AI-Powered Data Quality Checks
Handle Complex JS Websites
Navigate Anti-Bot Measures

Capabilities
ScrapeHero’s web crawling services are built for efficiency
Crawl Complex Websites
We crawl data from various websites, including e-Commerce, news, job boards, and forums, and even those with IP blacklisting and anti-bot measures.
Access Data in any Format
Access crawled data in any format - JSON, CSV, XML, etc. Stream data as well directly from our API or have it delivered to Dropbox, Amazon S3, Box, FTP, etc.
High-Speed Web Crawling
Our web crawling infrastructure can scrape up to 3000 pages per second for sites with moderate anti-scraping measures, making it ideal for enterprise-grade web crawling.
Schedule Crawling Tasks
Our job scheduler is fault-tolerant and ensures that your web crawling tasks run on schedule without missing a beat.
High Quality Data
Our web crawling service has built-in automated checks to remove duplicate data and re-crawl invalid data and uses Machine Learning to validate data quality.
ETL Assistance
We can perform complex and custom transformations – custom filtering, insights, fuzzy product matching, and fuzzy de-duplication on large amounts of data.
Web crawling services for data-driven decisions across industries
Our web crawling service can provide industry-specific data that best suits your business.
E-commerce
Stay updated on the latest prices, product availability, reviews, and other relevant details of various products in real-time.
Real Estate
Track real estate market, gather property data for valuation, and strategize urban planning with population and resource data.
Travel
Collect hotel reviews, pricing, availability, and airline ticket prices to optimize pricing and enhance customer service.
Looking for something else?
What you see here is only a tiny sample of the types of data we can scrape. Schedule a free call to explore the feasibility of scraping your desired data source.
Use cases
Web Crawling supplies data for diverse data needs
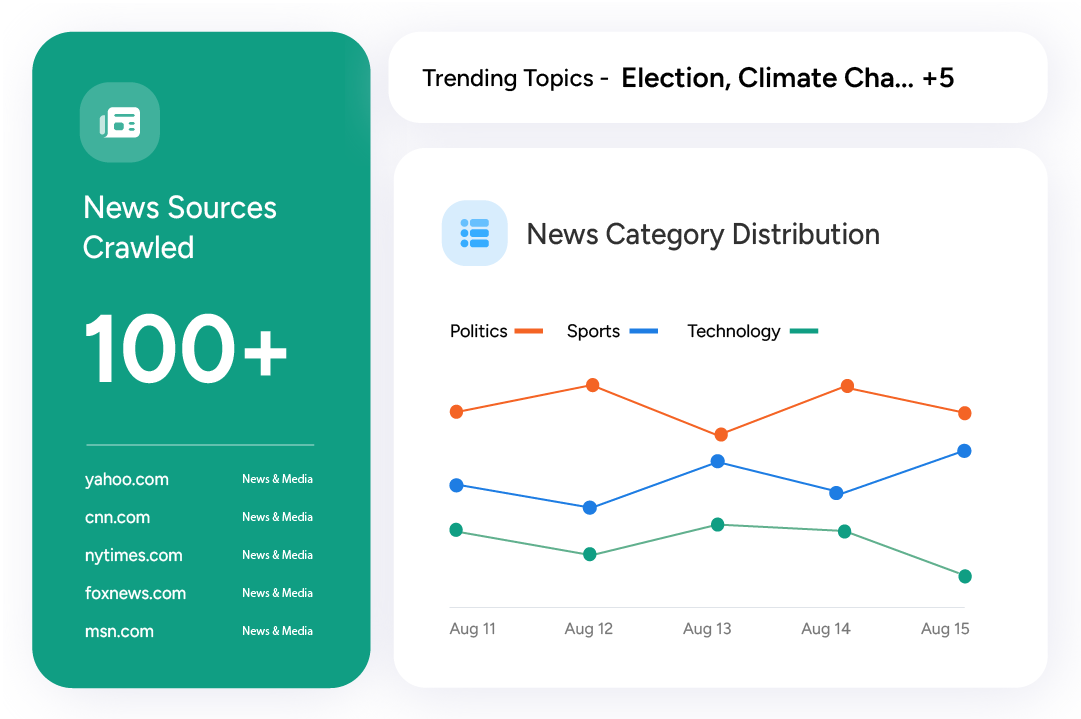
News Aggregation
Aggregate news articles from thousands of sources for analysis and research using our advanced NLP-based news detection platform. No need to build thousands of scrapers.
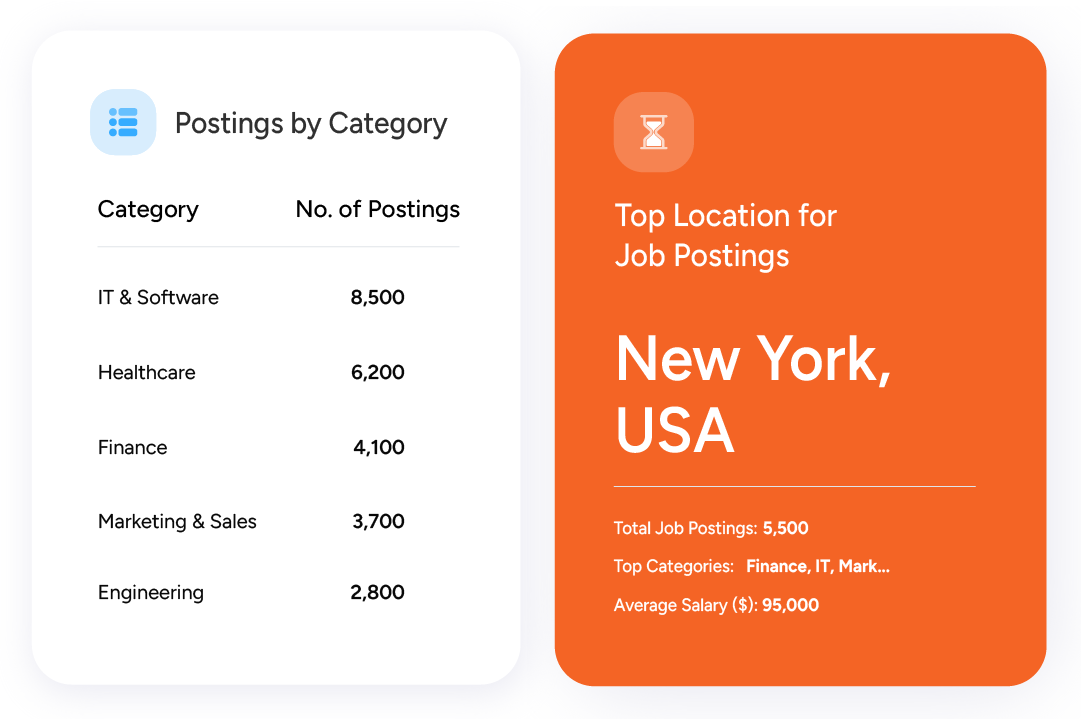
Job Data Feeds
Collect job postings by crawling numerous job sites and career pages, and use the data for building job aggregator websites, conducting research and analysis, and gaining competitive intelligence.
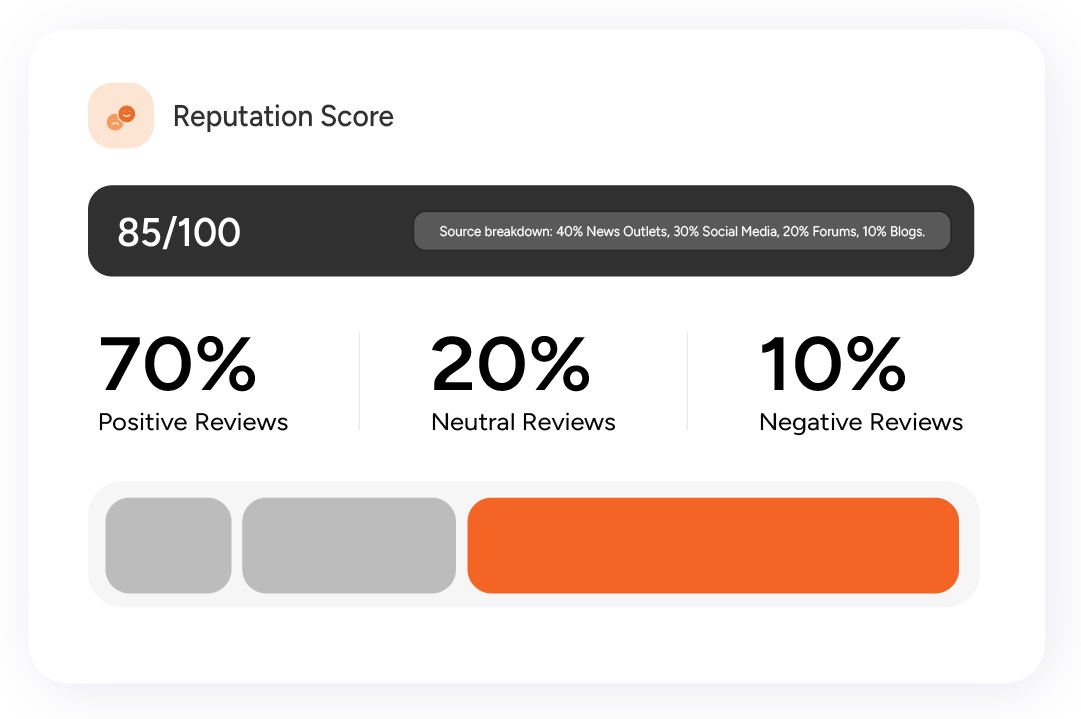
Background Research
Conduct background research for the reputation of individuals or businesses by crawling reputed online sources and applying text classification and sentiment analysis to the gathered data.
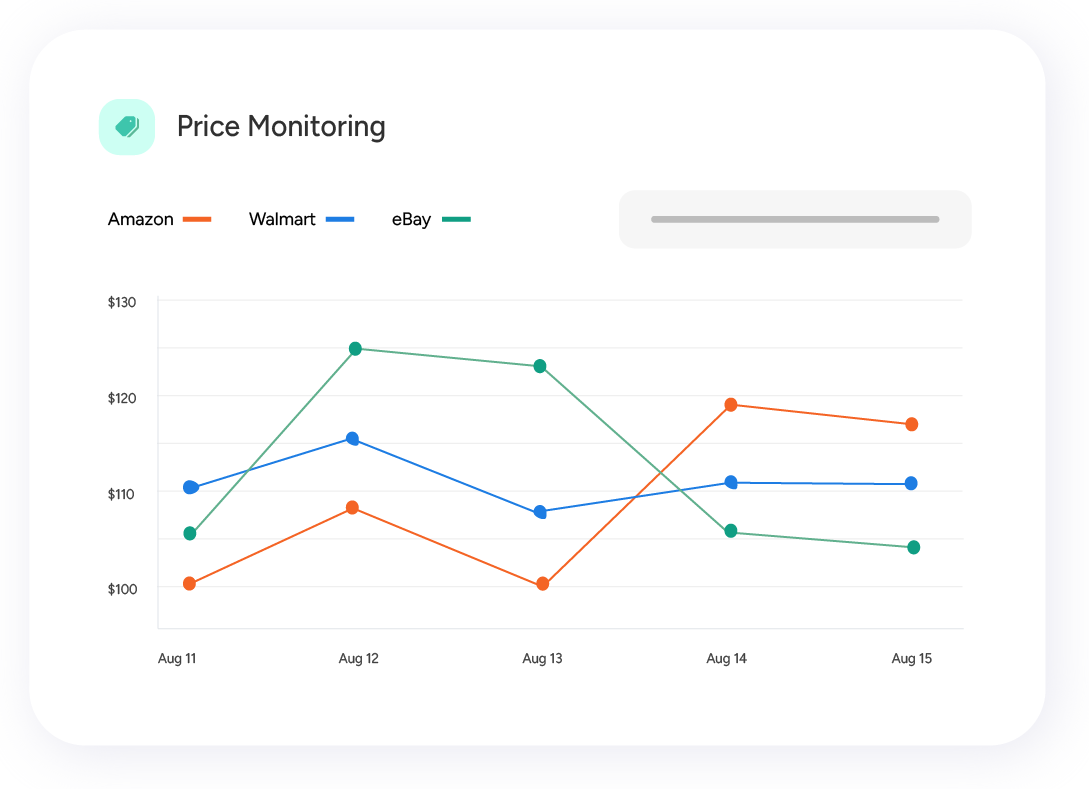
Product Price Comparison
Get real-time updates on pricing, product availability, and other details of products across e-commerce websites. Make smarter and real-time decisions to stay price-competitive.
ScrapeHero’s Process
Requirements
Tell us which websites to crawl and which data points to collect
Crawling
We crawl the data using our highly distributed web crawling software
Data Delivery
We deliver clean usable data in your preferred format and destination
Why ScrapeHero
ScrapeHero is synonymous with data reliability
We’re one of the best data providers for a reason.
We are Customer-Focused
Our goal is customer happiness, not just satisfaction. We have a 98% retention rate and experts available to help you within minutes of your requests.
Data Quality is Paramount
We use AI and machine learning to identify data quality issues. Both automated and manual methods are used to ensure high-quality data delivery at no extra cost.
We are Built for Scale
Our platform can crawl thousands of pages per second, extract data from millions of web pages daily, and handle complex JS sites, CAPTCHA, and IP blacklisting transparently.
We Value Your Privacy
Our customers span from startups to Fortune 50 companies. We prioritize our customers’ privacy and do not publicly disclose customer names or logos.
Ready to turn the internet into meaningful and usable data?
Contact us to schedule a brief, introductory call with our experts and learn how we can assist your needs.
Additional Resources


Data Extraction Services – an essential guide and checklist
Data is everywhere but most of it is unusable because
Frequently asked questions (FAQs)
What is web crawling?
Web crawling is an automated method of gathering content from publicly available websites, utilized by search engines like Google. It involves bots navigating sites, collecting text, images, and videos to create an index. This process mimics human browsing but is executed faster and on a larger scale. It’s an essential technology for companies, saving billions in lost productivity by automating data extraction. Web crawling enhances data accuracy and volume, benefiting businesses and research endeavors globally.
What is the difference between Web Crawling and Web Scraping?
Web scraping and web crawling are related concepts. Web scraping is the process of automatically requesting a web document or page and extracting data from it. On the other hand, web crawling is the process of locating information on the web, indexing all the words in a document, adding them to a database and then following all hyperlinks and indexes and then adding this information to a database.
Can you crawl password-protected areas or behind login forms?
We only collect data from publicly available websites and do not crawl websites that require login credentials.
What if the websites have anti-scraping measures in place?
Our global infrastructure makes large-scale data crawling easy and painless by handling complex JavaScript/AJAX sites, CAPTCHA, and IP blacklisting transparently. We have self-healing tech to tackle website changes and massive browser farms to handle complex websites.
Is web crawling legal?
Please refer to this page for consolidated and updated information about legal topics.
Can you scrape personal or sensitive and confidential information?
No, we do NOT gather or store such data.
What are your pricing plans, and how are they structured?
For pricing-related information, please refer to Pricing.
How do you ensure data quality?
We create tests for validating each record, perform spot checks on the dataset, and set up QA checks to monitor the scraper’s metadata such as the number of pages it crawls, response codes, etc. We invest heavily in Machine Learning and Artificial Intelligence to improve problem detection and provide tremendous value for no additional cost.
Can you schedule crawls and automate data collection?
If you need the data on a recurring basis, we create one or more schedules in our advanced fault-tolerant scheduler, that ensures the data is gathered reliably.
Why should I choose ScrapeHero for crawling?
We are a leader in web crawling services globally and crawl publicly available data at very high speeds and with high accuracy. Combine the data we gather with your private data to propel your enterprise forward. You don’t have to worry about setting up servers and web crawling tools or software. We provide the best web scraping service and do everything for you. Just tell us what data you need, and we will manage the data crawling for you.
What level of customer support do you provide?
We provide ongoing support, quality assurance, and maintenance as a part of our subscription plans. Websites change their structure periodically, and they also block automated access. As a result, maintenance is also an integral part of our subscription service. We have built-in health checks that alert us as a website’s structure changes so that we can make the changes and minimize the disruption to the data delivery. Also included are our automated and manual data quality checks.