

One of the ways a website detects bots is by noticing the frequency of the requests per IP address. If an IP address makes many requests in a short span, more than possible by a user, the website may ban the IP address. That is why you need to use a proxy for web scraping.
In this article, you can read about proxies, their types, and how to use a proxy for web scraping in Python.
What is a Proxy Server?
Proxy servers are third-party servers you use as intermediaries between yourself and a website. These servers can be anywhere, and your communication passes through these proxy servers after you connect to them. Therefore, a proxy server becomes your gateway to the internet.
What Are the Benefits of Using Proxies?
There are several benefits to having a proxy:
- You can remain anonymous while browsing with a proxy. That is because all your data passes through the server when you connect. The websites you visit will see the proxy server’s IP address, not yours.
However, some proxies, known as transparent proxies, don’t hide your IP address. You will read about them shortly. - Proxies can also bypass geo-restrictions. For example, your target website may not serve its content in your country. You can access that content by using a proxy server.
- Proxies also enhance security by encrypting your data. As all your data goes through the proxy, a proxy server can encrypt it and make it unreadable to any snooper. That way, even if someone steals your data, the person won’t understand it.
- Your ISPs can identify which websites you have visited. If you use a proxy, they can only see that you visited the proxy server. Your visits to any web page will remain invisible.
What Are the Benefits of Using a Proxy in Web Scraping?
The points mentioned above also benefit web scraping.
When scraping large data sets, your target website might block your IP because their policies may prohibit accessing their site at more than a specific rate; this is rate-limiting.
A proxy will let you bypass rate limiting as you can switch it. You can change the IP address whenever the current one reaches the limit or the target website blocks you.
This process of frequently switching proxies is known as IP rotation.
Proxies also enable you to scrape websites in other countries where the content is inaccessible. You need a proxy located in that country to scrape those sites.
How Many Different Proxies Are There?
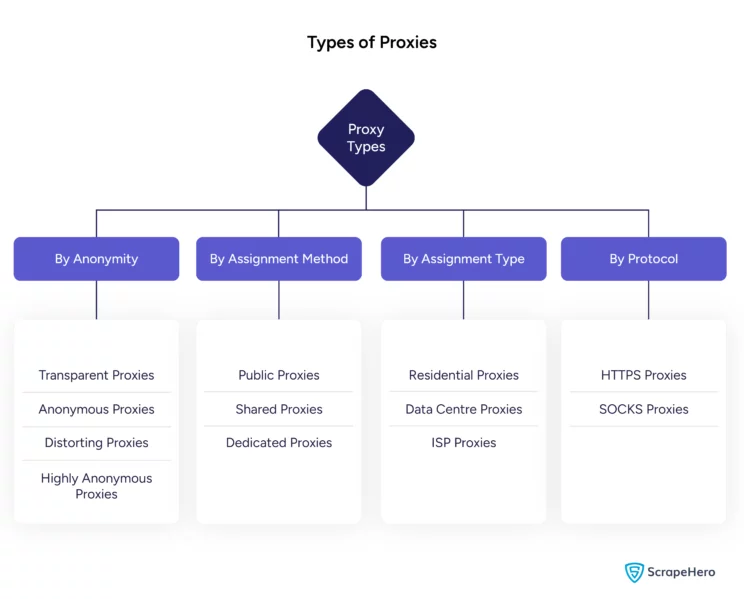
There are several types of proxies. You can categorize them according to various parameters.
Proxies Differ in Their Assignment Method
- You can have free public proxies. However, these free proxies may be unfit for web scraping. Your target website may have already blocked them.
- There are shared proxies where several clients share one IP address. These IP addresses are not usually free, but they are cheap proxies for web scraping. However, you have a better chance of not getting blocked.
- Finally, you have dedicated proxies, which your target website most likely won’t block. These proxies are unique to a client.
Proxies Differ in Their Assignment Type
- Residential proxies are very expensive; they represent the IPs of individual residences. Therefore, they are high-quality proxies for web scraping. You will likely avoid IP blocking with these.
- Data Center Proxies are less expensive than residential proxies but are unreliable. These proxies reside in a data center, and websites may have already blocked them.
- ISP proxies are part data center and part residential proxies. They are data center proxies posing as residential ones. They are more reliable than data center proxies; however, they get blocked more than a residential proxy.
Proxies Differ in Their Anonymity Level
- Transparent proxies do not hide your IP address; therefore, they are not beneficial for web scraping. You use them mostly for monitoring. For example, you can use it for your employees and know the sites they visit.
- Anonymous proxies hide your IP addresses. However, they do not hide the fact that they are a proxy. That means some websites may block your IP address.
- Distorting proxies provide a fake IP address to the target website. These are highly beneficial for web scraping, as you will most likely bypass the anti-scraping measures. However, these proxies are more expensive.
- Highly anonymous proxies keep rotating the IP address they use. That means you will likely succeed in scraping data from the website.
Proxies Differ in Their Protocols
- HTTP proxies use the standard Hypertext Transfer Protocol to communicate. They can interpret the data, allowing data filtration while web scraping. Moreover, they can use TLS (Transport Layer Security) to encrypt data, making it more secure.
- SOCKS protocols reroute the traffic via a third-party server using a TCP protocol. It cannot interpret data as an HTTP protocol; however, it passes through communication irrespective of the protocol.
How to Use a Proxy for Web Scraping
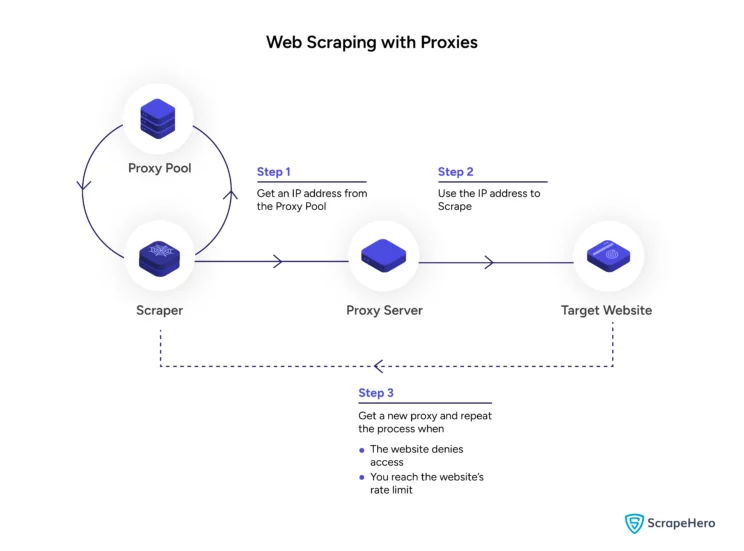
You can use proxies while web scraping in Python; some libraries allow you to make requests with a proxy.
For example, you can use proxies with both Selenium and requests in Python. In requests, you send the proxies as an argument along with the URL.
import requests
proxies = {
'http': 'http://196.223.129.21:80',
'https': 'http://196.223.129.21:80’,
}
requests.get('http://example.org', proxies=proxies)In Selenium, you can use the add_argument() method to set the proxy URL.
chrome_options = WebDriver.ChromeOptions()
chrome_options.add_argument('--proxy-server=%s' % PROXY)
chrome = webdriver.Chrome(chrome_options=chrome_options)
In the above code, the PROXY variable contains the proxy IP address.
The above methods are for using free proxies. Free proxies don’t need authorization, but paid proxies do. The authorization method depends on the proxy service and the technique used for web scraping.
For proxy rotation, you can use a loop and itertools module to keep changing proxies.
import requests
from itertools import cycle
proxy-pool = [ ]
proxies = cycle(proxy-pool)
for i in range(10):
newProxy = next(proxies)
proxies = {
'http': newProxy,
'https': newProxy,
}
try:
response = requests.get('http://example.org', proxies=proxies)
except:
print("request failed, trying a new proxy")How Do You Choose a Proxy for Web Scraping?
Choosing a proxy requires you to understand
- Your purpose: The proxy type depends on the website you wish to scrape and the number of requests you will make. These two parameters dictate the most appropriate type for your web scraping project.
For example, a strict website that easily detects bots may require a highly anonymous residential proxy. On the other hand, you can get away with a distorting data center proxy if the website lacks strict anti-scraping measures. - Your budget: The higher the quality of your proxy, the more you need to pay for it. Therefore, after shortlisting proxies based on your purpose, choose those that fit within your budget.
- Your location: If you want to bypass geo-restrictions, you also need to consider the proxy server’s location. It must be in a country that your target website allows.
Wrapping Up
Proxies are third-party servers that may help you remain anonymous and let you bypass geo-restrictions. Proxies also allow you to bypass anti-scraping measures by allowing you to send requests from a different IP every time.
However, choosing a proxy for web scraping can be challenging. You must consider various factors, including purpose, budget, and location. You must also pay separately for a proxy service and the resources required for web scraping.
Try ScrapeHero services, and you can avoid all these challenges. ScrapeHero is a full-service enterprise-grade web scraping provider. Our services include large-scale scraping and crawling; we also provide monitoring services, including product monitoring and brand monitoring.
Frequently Asked Questions
-
What is the difference between a proxy and a VPN?
The main difference between a proxy and a VPN is encryption. VPNs provide end-to-end encryption. HTTPS proxies can provide encryption; however, the encryption is only between you and the proxy. Proxy servers don’t encrypt the communication between themselves and the target website.
-
Is a VPN better than a proxy for web scraping?
A VPN is less ideal than a proxy for web scraping. VPNs are expensive and reroute all the communication from your computer. However, proxies are cheaper and only reroute the communication from your specific application. Therefore, proxies are better for web scraping as they provide more granular control.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data


