

Web scraping, when not done ethically, can negatively affect the performance of websites. In such situations, site owners restrict open data access by implementing anti-scraping mechanisms. So what are some methods that can be used to scrape without getting banned?
In this article, you will learn how to scrape without getting blocked by anti-scraping or bot detection tools by following some practices.
Why Do Site Administrators Block Web Crawlers?
Before getting started and learning how to scrape without getting blocked you should understand why site administrators block web crawlers/scrapers/spiders. If a crawler performs multiple requests per second and downloads large files, an underpowered server cannot handle these multiple incoming requests.
Also, web crawlers don’t really drive human website traffic and they seemingly affect the performance of the site. Hence, site administrators do not promote web crawling and try to block the spiders.
Best Practices to Follow for Web Scraping Without Getting Blocked
To bypass the anti-scraping mechanisms set by target websites, it is essential to follow some techniques. Here are some to consider:
- Respect Robots.txt
- Make the crawling slower, do not slam the server, treat websites nicely
- Do not follow the same crawling pattern
- Make requests through Proxies and rotate them as needed
- Rotate User-Agents and corresponding HTTP Request Headers between requests
- Use a headless browser like Puppeteer, Selenium or Playwright
- Beware of Honeypot Traps
- Check if website is changing layouts
- Avoid scraping data behind a login
- Use CAPTCHA Solving Services
1. Respect Robots.txt
Web spiders should ideally follow the robots.txt file while web scraping. It has specific rules like how frequently you should scrape, which pages allow scraping, and which ones you can’t. Some websites allow Google to scrape theirs while blocking others. Even though it’s against the open nature of the Internet, the owners of the website are within their rights to resort to such behavior.
You can find the robots.txt file on websites. It is usually the root directory of a website: http://example.com/robots.txt.
If it contains lines like the ones shown, it means the site does not want to scrape.
User-agent: *
Disallow:/
However, since most sites want to be on Google, they allow access to bots and spiders.
1.1 What if You Need Some Data That is Forbidden by Robots.txt?
You could still bypass anti-scraping measures on websites and scrape them. Most anti-scraping tools block web scraping when you are scraping pages that are not allowed by robots.txt.
These tools can identify whether the client is a bot or a real user. For this, the tools look for a few indicators that real users do and bots don’t. As it is clear, humans are random and bots are not. Also, humans are not predictable, but bots are.
The tools can determine if it’s a bot/scraper/crawler if any combinations of these are right:
- Scraping too fast and too many pages, faster than a human ever can.
- Following the same pattern while crawling. For example, going through all pages of search results and going to each result only after grabbing links to them, which a human never does.
- Too many requests from the same IP address in a very short time span.
- Not identifying as a popular browser.
- Using the User-Agent string of a very old browser.
2. Make the Crawling Slower, Do Not Slam the Server, Treat Websites Nicely
Web scraping bots fetch data very fast, but it is easy for a site to detect your scraper, as humans cannot browse that fast. If a website gets more requests than it can handle, it might become unresponsive.
Make your spider look real by mimicking human actions so that you can easily bypass anti-scraping measures on websites. Put some random programmatic sleep calls in between requests, or add some delays after crawling a small number of pages.
You can also choose the lowest number of concurrent requests possible. Ideally you should have a delay of 10–20 seconds between clicks and treat the website nicely by not putting much load on the website.
Use auto-throttling mechanisms, which will automatically throttle the crawling speed based on the load on both the spider and the website that you are crawling. Adjust the spider to an optimum crawling speed after a few trial runs. Do this periodically because the environment does change over time.
3. Do Not Follow the Same Crawling Pattern
Humans generally will not perform repetitive tasks while they browse through a website. Web scraping bots tend to have the same crawling pattern because they are programmed that way unless specified.
Sites that have intelligent anti-crawling mechanisms can easily detect spiders by finding patterns in their actions, which can lead to web scraping getting blocked.
In order to bypass anti-scraping, you can incorporate some random clicks on the page, mouse movements, and random actions that will make a spider look like a human.
4. Make Requests Through Proxies and Rotate Them as Needed
When web scraping, your IP address can be seen. A site will know what you are doing and if you are collecting data. The site could collect data such as user patterns or experiences, even if you are a first-time user.
Multiple requests coming from the same IP will lead you to get blocked, which is why we need to use multiple addresses. When we send requests from a proxy machine, the target website will not know where the original IP is from, making the detection harder.
Create a pool of IPs that you can use and use random ones for each request. Along with this, you have to spread a handful of requests across multiple IPs.
4.1 Different Methods That Can Change Your Outgoing IP
Changing your outgoing IP address can help bypass anti-scraping measures on websites. Here are several methods to achieve this:
- TOR (The Onion Router) – TOR routes your internet traffic through multiple layers of encryption across a global network of relays, effectively masking your IP address.
- VPNs (Virtual Private Network) – A VPN encrypts your internet connection and routes it through a server in a location of your choice, masking your real IP address with one from the VPN server.
- Free Proxies – Free proxies can change your outgoing IP address and are often used for bypassing geographical restrictions or simple web browsing anonymity.
- Shared Proxies – Shared proxies are the least expensive proxies shared by many users. The chances of getting blocked are high.
- Private Proxies – Private proxies are usually used only by you, and there are lower chances of getting blocked if you keep the frequency low.
- Residential Proxies – Choose residential proxies if you are making a huge number of requests to websites that block actively. These are very expensive (and could be slower, as they are real devices). Try everything else before getting a residential proxy.
- Data Center Proxies – Use data center proxies if you need a large number of IP addresses, faster proxies, or larger pools of IPs. They are cheaper than residential proxies and can be detected easily.
In addition, various commercial providers also provide services for automatic IP rotation. Even though Residential IPs make scraping easier, most are expensive.
5. Rotate User-Agents and Corresponding HTTP Request Headers Between Requests
User-Agent indicates the web browser used by a server, preventing websites from displaying content if it’s not set. You can get your User-Agent by typing ‘what is my user agent’ in Google’s search bar. Faking the User-Agent can bypass detection, as most web scrapers don’t have one by default.
Just sending User-Agents alone would get you past most basic bot detection scripts and tools. If you find your bots getting blocked even after putting in a recent User-Agent string, add more request headers.
Most browsers send more headers to websites than just the User-Agent. For example, here is a set of headers a browser sent to ScrapeMe. It would be ideal to send these common request headers too.
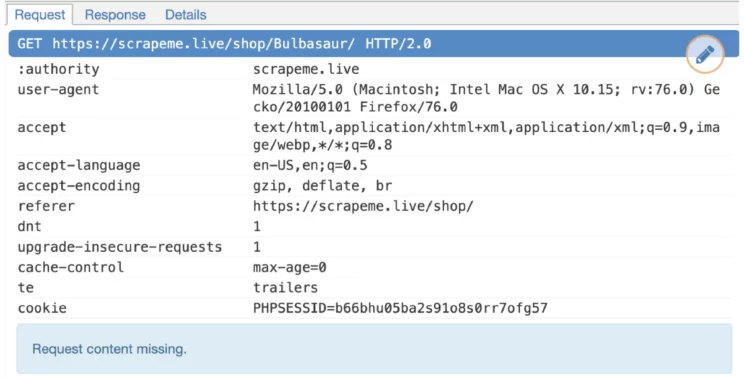
The most basic headers are:
- User-Agent
- Accept
- Accept-Language
- Referer
- Upgrade-Insecure-Requests
- Cache-Control
Note: Do not send cookies unless your scraper depends on cookies for functionality.
You can find the right values for these by inspecting your web traffic using Chrome Developer Tools, or a tool like MitmProxy or Wireshark. You can also copy a cURL command to your request from them.
For example:
curl 'https://scrapeme.live/shop/Ivysaur/' \
-H 'authority: scrapeme.live' \
-H 'dnt: 1' \
-H 'upgrade-insecure-requests: 1' \
-H 'user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36' \
-H 'accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9' \
-H 'sec-fetch-site: none' \
-H 'sec-fetch-mode: navigate' \
-H 'sec-fetch-user: ?1' \
-H 'sec-fetch-dest: document' \
-H 'accept-language: en-GB,en-US;q=0.9,en;q=0.8' \
--compressed
You can get this converted to any language using a tool like curlconverter.
Here is how this was converted to Python:
import requests
headers = {
'authority': 'scrapeme.live',
'dnt': '1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'sec-fetch-site': 'none',
'sec-fetch-mode': 'navigate',
'sec-fetch-user': '?1',
'sec-fetch-dest': 'document',
'accept-language': 'en-GB,en-US;q=0.9,en;q=0.8',
}
response = requests.get('https://scrapeme.live/shop/Ivysaur/', headers=headers)
You can create similar header combinations for multiple browsers and start rotating those headers between each request to reduce the chances of getting your web scraping blocked.
6. Use a Headless Browser Like Puppeteer, Selenium or Playwright
If none of the methods work, the website checks if the visitor is a real browser and if they can render JavaScript. Most websites have JavaScript enabled, so a real browser is needed to scrape data. There are libraries to automatically control browsers, such as:
Anti-scraping tools are getting smarter daily as bots feed a lot of data to their AIs to detect them. Most advanced bot mitigation services use browser-side fingerprinting.
An automation library is used to control a browser, and bot detection tools search for flags indicating this activity.
- Presence of bot-specific signatures
- Support for nonstandard browser features
- Presence of common automation tools such as Selenium, Puppeteer, Playwright, etc.
- Human-generated events such as randomized mouse movement, clicks, scrolls, tab changes, etc.
All this information is combined to construct a unique client-side fingerprint that can tag one as a bot or a human.
Here are a few workarounds or tools that could keep your headless browser-based scrapers from getting banned.
But, as you might have guessed, just like bots, bot detection companies are getting smarter. They have been improving their AI models and looking for variables, actions, events, etc. that can still give away the presence of an automation library, leading to web scraping getting blocked.
7. Beware of Honeypot Traps
Honeypots are systems set up to lure hackers and detect any hacking attempts that try to gain information. It is usually an application that imitates the behavior of a real system. Some websites install honeypots, which are links invisible to normal users, but web scrapers can see them.
When following links, always ensure the link has proper visibility with no nofollow tag. Some honeypot links to detect spiders will have the CSS style display:none or will be color-disguised to blend in with the page’s background color. Even disabling CSS and images won’t help in such cases.
Also, this detection is obviously not easy and requires a significant amount of programming work to accomplish properly. As a result, this technique is not widely used on either side—the server side or the scraper side.
8. Check if Website is Changing Layouts
Websites may change their layouts or implement anti-scraping measures for a variety of reasons, including improving the user experience or protecting their data.
Detecting and adapting to layout changes is crucial for maintaining the effectiveness of web scraping. Some websites make it tricky for scrapers, serving slightly different layouts.
For example, on a website, pages 1–20 will display a layout, and the rest of the pages may display something else. To prevent this, check if you are getting data scraped using XPaths or CSS selectors. If not, check how the layout is different and add a condition in your code to scrape those pages differently.
9. Avoid Scraping Data Behind a Login
Login is basically permission to get access to web pages. The scraper must send some information or cookies along with each request to view a protected page. This makes it easy for the target website to see requests coming from the same address.
They could also take away your credentials or block your account, which can, in turn, lead to web scraping being blocked.
It’s generally preferred to avoid scraping websites that have a login, as it is difficult to bypass anti-scraping measures on websites, and you will also get blocked easily. But one thing you can do is imitate human browsers whenever authentication is required to get the target data you need.
10. Use CAPTCHA Solving Services
Many websites use anti-web scraping measures. If you are scraping a website on a large scale, the website will eventually block you. You will start seeing CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) pages instead of web pages.
If you need to bypass anti-scraping and scrape websites that use CAPTCHA, it is better to resort to CAPTCHA services, which are relatively cheap and useful when performing large-scale scraping.
For effective and ethical web scraping, it’s essential to adhere to legal standards and maintain positive relations with site owners. Investing time to understand and navigate a site’s anti-scraping measures can prevent blocks, ensuring your scraping efforts are not only successful but also sustainable and respectful of web resources.
How Do You Find Out if a Website Has Blocked or Banned You?
If any of the mentioned signs appear on the site that you are crawling, it is usually a sign of being blocked or banned.
- CAPTCHA pages
- Unusual content delivery delays
- Frequent response with HTTP 404, 301, or 50x errors
The frequent appearance of these HTTP status codes is also an indication of blocking.
- 301 Moved Temporarily
- 401 Unauthorized
- 403 Forbidden
- 404 Not Found
- 408 Request Timeout
- 429 Too Many Requests
- 503 Service Unavailable
Examples of Various Types of Blocking by Websites
-
SORRY Something Went Wrong on Our End
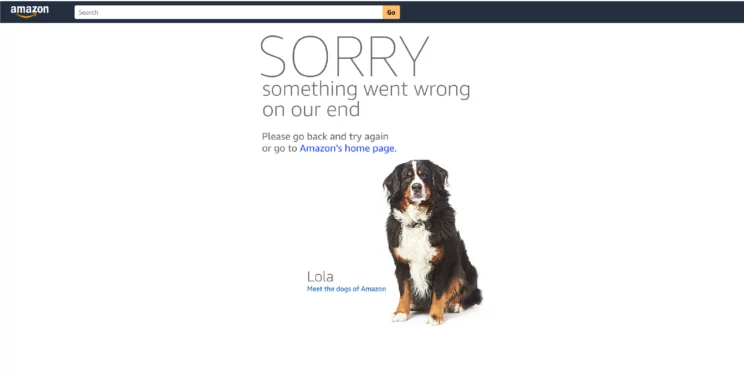 Error type: Either 503 Service Unavailable or Frequent response with HTTP 404, 301, or 50x errors.
Error type: Either 503 Service Unavailable or Frequent response with HTTP 404, 301, or 50x errors.
Here is what Amazon.com tells you with a picture of a cute dog when you are blocked.
SORRY something went wrong on our end
Please go back and try again or go to Amazon's home page.
Lola Meet the dogs of Amazon -
I’m Not a Robot

Error type: CAPTCHA
Here is the message that appears to verify you are not a robot.
I'm not a robot
About this page
Our systems have detected unusual traffic from your computer network. This page checks to see if it's really you sending the requests, and not a robot. Why did this happen?
IP address: 80.67.167.81
Time: 2024-02-05T06:21:32Z
URL: https://www.google.com/search?q=google+translate&oq=goog&gs_lcrp=EgZjaHJvbWUqBwgBEAAYjwlyBggAEEUYOTIHCAEQABIPAJIHCAIQABIPAJIHCAMQABIPAtIBCDU2MTJqMGoxqAIASAIA&sourceid=chrome&ie=UTF- -
Verify You Are Human by Completing the Action Below
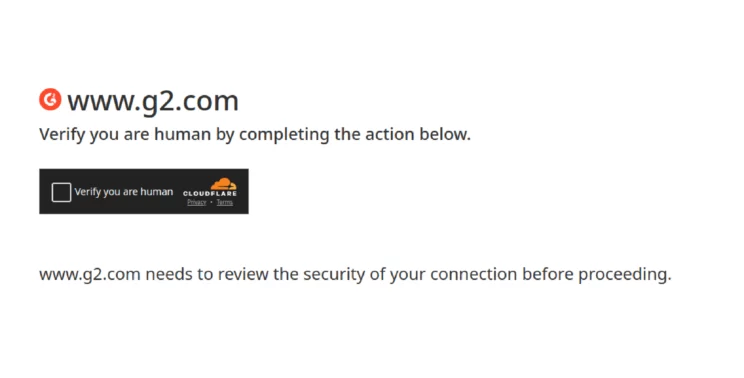
Error type: CAPTCHA
Here’s the text that appears when g2 blocks you and needs to verify that you are human.
Verify you are human by completing the action below.
Verify you are human
www.g2.com needs to review the security of your connection before proceeding. -
Enter the Characters You See Below
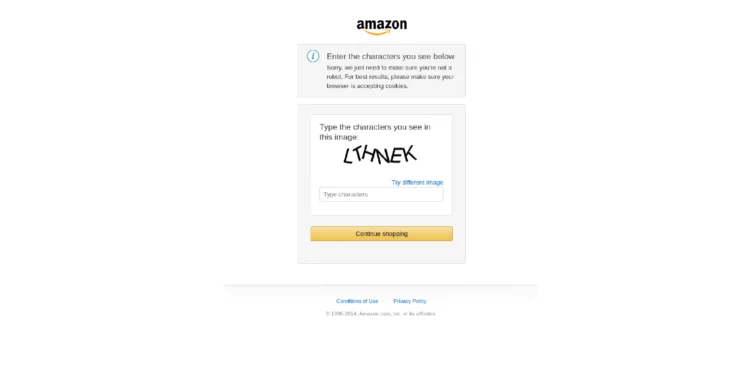
Error type: CAPTCHA
Here’s what you see when Amazon blocks you and makes you enter characters.
Enter the characters you see below
Sorry, we just need to make sure you're not a robot. For best results, please make sure your browser is accepting cookies.
Type the characters you see in this image:
LTHNEK
Type characters
Try different image
Continue shopping
Wrapping Up
Websites are using more advanced anti-bot solutions to safeguard their resources. These can range from straightforward IP address identification to intricate JavaScript validation.
At times, you may face challenges during web scraping, and you may be unable to solve them manually or programmatically. So you can contact ScrapeHero to solve them more effectively. For scalable web scraping and to bypass anti-scraping measures, we recommend our services.
ScrapeHero web scraping services can provide a safer, more efficient, and legally compliant way to collect data. With our professional expertise, we could meet your data collection needs while minimizing risks and ethical concerns. Also, we ensure compliance, efficiency, and high-quality data collection, saving you time and resources and offering a higher return on investment.
Frequently Asked Questions
-
How to scrape without getting blocked?
In a nutshell, you can say that using several ways, like respecting robots.txt, using a scraping framework or library, rotating IP addresses and User-Agents and handling errors effectively, you can bypass anti-scraping measures on websites.
-
How do I hide my IP address when scraping a website?
For web scraping without getting blocked, you can use methods such as rotating proxy servers or a Virtual Private Network (VPN) to mask and change your IP address frequently while scraping.
-
How do I bypass anti-scraping measures in Chrome?
To bypass anti-scraping measures on websites, you require a combination of techniques, such as using a headless browser configuration with tools like Puppeteer or Selenium to mimic human-like interactions and rotating User-Agents and IP addresses using proxies to avoid detection.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data


