Web scraping is widely used for collecting data across the internet. As the demand for data increases, its importance also increases. In web scraping, headers play a crucial role, and this article deals with the essential HTTP headers for web scraping that you should be aware of.
The vast amount of data that is extracted through web scraping can be used for business intelligence, market research, decision-making, etc. You would already know that while creating a web scraper, factors such as headers, proxy, request parameters, request type, etc. must be considered.
Now let’s get a bit deeper into the topic of some of the necessary headers for web scraping and the tips for using these headers.
What Are HTTP Headers?
HTTP headers are some set of information transferred between a website and a client while retrieving web pages. The information sent from the client to the website server is called a Request header. It contains information about the browser and the operating system.
The server can easily identify the request’s source by looking at these headers. Similarly, when the server returns some additional information along with the response, it is called a Response header. Here is the list of essential headers for web scraping:
- Request Headers
- Referer
- User-Agent
- Accept
- Accept-Language
- Cookie Header
- Response Headers
- Content Type
- Location Header
Request Headers
One of the key HTTP headers for web scraping include Request headers. When a computer connects with a server to ask for a webpage or any other resource, it sends a set of key-value pairs called “Request headers” to provide the server with additional information.
Request headers are a crucial part of HTTP requests, and understanding them is essential for web scraping as it can reduce the chance of getting blocked.
-
Referer
The Referer is the partial or full domain address from which the request has been initiated. Let’s take the example of scraping an e-commerce website by navigating through listing pages and product pages. In this case, the Referer to the product page is the respective listing page.
From the following flow diagram the flow of the Referer during the website navigation can be understood clearly.
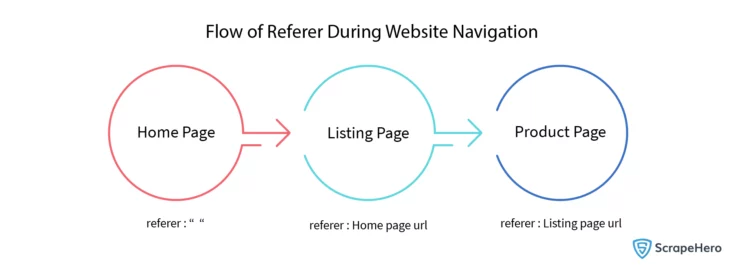
Here, the navigation starts from the home page, with no Referer. Then, from the home page, we navigate to the listing page. Here, the Referer is the home page URL. From the listing page, we navigate to the product page; here, the Referer will be the listing page URL.
A web server can easily identify a scraper by looking at the Referer of that request. It is crucial to use a proper Referer to ensure that the request is from a valid source.
-
User-Agent
The User-Agent is a string containing information about the name and versions of the operating system and browser (or tool) used to send the request. An example of a typical User-Agent string is shown below.
Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36When we send a request to a web page, the website server can identify the client details, such as browser, OS version, etc., using a User-Agent. Using this information, the websites can block the scrapers thus making them one of the essential HTTP headers for web scraping.
The User-Agent string of a normal Python request and a browser request (normal browsing) is different. You can find examples below:
Python Request Module
'User-Agent': 'python-requests/2.28.1'Linux + Firefox
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:109.0) Gecko/20100101 Firefox/112.0'Web scrapers can avoid blocking by using the User-Agent of a browser (Chrome, Safari, Firefox, etc.). If you inspect the browser’s network tab, you can find the User-Agent string.
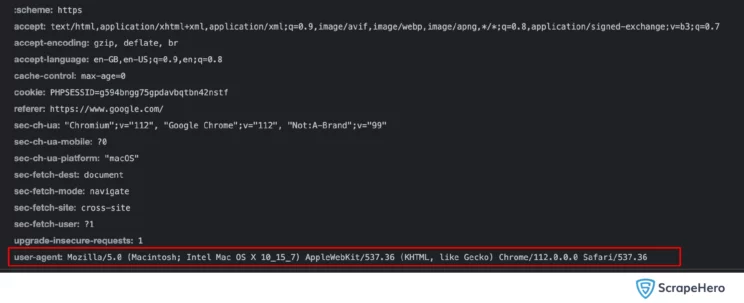
We can bypass the blocking when we use this User-Agent in our scraper. It is always good to use the same browser headers in our scraper.
-
Accept Header
An Accept header indicates the type of response the client expects to receive from the server. These are called MIME types. An Accept header can have one or more MIME types. For example, text/html, image/jpeg, and application/json.
If we use application/json in the Accept header, the server may send the response in JSON format instead of HTML. This helps with further parsing and operations.
On the other hand, invalid Accept headers might lead to the server retrieving invalid data or restricting the request. An example of an invalid Accept header affecting the retrieved data is as follows:
import requests
url = 'https://api.github.com/user'
headers = {
'Accept': 'application/pdf',
}
response = requests.get(url, headers=headers)
print("Status code:", response.status_code)
print("Response text:", response.text)Output:
Status code: 415
Response text: {"message":"Unsupported 'Accept' header: 'application/pdf'. Must accept 'application/json'.","documentation_url":"https://docs.github.com/v3/media"}Here, the response of the endpoint https://api.github.com/user is in JSON format, and we are trying to fetch a PDF document from that endpoint that the server couldn’t handle. The server returned a 415 status code in the output with the messageUnsupported Accept header.
-
Accept-Language
An Accept-Language header indicates the preferred natural languages of the response contents the client expects to receive from the server. The Accept-Language header can have one or more languages in order of priority. An example of an Accept-Language header is as follows:
accept-language: en-GB,en-US;q=0.9,en;q=0.8This header can be considered as one of the essential HTTP headers for web scraping for scraping language-specific websites. If we want to scrape a website whose content is in a specific language, it is essential to use a proper Accept-Language header, or else the server may return a response in a different language.
The Accept-Language header is essential for mimicking real user behavior in scrapers while scraping language-specific websites. Most real users will use that website in the default language.
-
Cookie Header
The HTTP Cookie header is a small set of data that is separated by a semi-colon (;). It can be generated on the client side or sent by the web server and stored in the browser’s local storage.
The primary intention of an HTTP Cookie header is to track human interactions with the website, including login information, preference data, browsing patterns, etc. The general syntax of a Cookie is as follows:
cookie: <cookie1_name>=<cookie1_value>; <cookie2_name>=<cookie2_value>; ...The major advantages of using an HTTP Cookie header in web scraping are listed below:
Session Management
The Cookies keep track of the session state during the data extraction process that requires authentication. If some websites demand basic authentication with bearer tokens or with CSRF(Cross-Site Request Forgery) tokens for validation, then adding relevant Cookies with appropriate authentic tokens is necessary to scrape data accurately.
Scraping Dynamic Websites
Dynamic websites often utilize Cookies as a means of efficiently storing and retrieving data. However, if we fail to implement proper Cookies, it can lead to complications when accessing dynamic content through scraping.
To Bypass Anti-Scraping Systems
Websites use various anti-scraping methods, including Cookie-based security measures. Handling and sending Cookies to the server while scraping can reduce Cookie-based bot detection.
Response Headers
Response headers are key-value pairs that a server sends back after receiving an HTTP request. They provide additional information about the resource you’ve requested. Businesses can use this information to optimize website performance and enhance the user experience.
Understanding response headers is useful, as they are the common HTTP headers for web scraping services. They determine whether a resource is successfully accessed or not.
Content-Type
The “Content-Type” header indicates the preferred format of response that the client expects to receive from the server. This header ensures that the content received from the server is in the desired format.
Sometimes, the “Content-Type” header may give information about potential flaws or errors. For example, if the intended Content-Type is not found or the response displays an unsupported Content-Type, that seems like there is an issue with the server side or the request we sent during the scraping.
Here are some examples of Content-Types:
Content-Type: application/xmlContent-Type: text/htmlContent-Type: image/jpegLocation Header
The Location header is significant since it informs the scraper about the new URL to which it should redirect. This enables the scraper to handle URL changes or redirections, collect the required data, and ensure .
Let’s look at some examples:
Location: https://www.websitedomain.com/another-pageIn this example, the requested contents are moved permanently to a new endpoint. The scraper should follow the new URL to gather the required content.
Location: /loginHere, the request redirects to a login page on the same domain. The scraper should handle this redirection to continue further scraping.
Location: /error404Here, the requested page is not found. It’s redirecting to an error page.
Tips for Using Headers in Web Scraping
The use of HTTP headers for web scraping can make your scraping process successful. Listed below are two important tips that can help you with your web scraping.
User-Agent Rotation
Using multiple User-Agents and rotating them for each request is a good practice in web scraping. This helps the scraper avoid blocking to some extent. An example of User-Agent rotation is given here.
import requests
import itertools
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"
]
ua_cycle = itertools.cycle(user_agents)
for i in range(10):
headers = {"User-Agent": next(ua_cycle)}
response = requests.get("https://httpbin.org/headers", headers=headers)
print(response.json()["headers"]["User-Agent"])A good practice is to test whether your user-agent rotation is working properly before deploying your scraper. You can do this using an HTTP Server Header Checker. The tool should display a different user agent after each rotation.
Adding Sec-CH-UA
Sec-CH-UA contains detailed information about the device from which the request has been sent. The mismatch of versions and names of the devices in the Sec-CH-UA and User-Agent might lead to blocking. An example of Sec-CH-UA with its User-Agent is as follows:
sec-ch-ua: "Chromium";v="112", "Google Chrome";v="112", "Not:A-Brand";v="99"
sec-ch-ua-arch: "x86"
sec-ch-ua-bitness: "64"
sec-ch-ua-full-version: "112.0.5615.165"
sec-ch-ua-full-version-list: "Chromium";v="112.0.5615.165", "Google Chrome";v="112.0.5615.165", "Not:A-Brand";v="99.0.0.0"
sec-ch-ua-mobile: ?0
sec-ch-ua-model: ""
sec-ch-ua-platform: "Linux"
sec-ch-ua-platform-version: "5.14.0"
sec-ch-ua-wow64: ?0
sec-fetch-dest: document
sec-fetch-mode: navigate
sec-fetch-site: none
sec-fetch-user: ?1
user-agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36Wrapping Up
HTTP headers are the information shared between clients and servers. There are a lot of headers available. Here we have discussed some HTTP headers that are essential for web scraping. It is important to use the correct headers in web scraping to avoid getting blocked.
HTTP headers can help you surpass anti-scraping mechanisms at times, but they are not enough at an enterprise scale for collecting large amounts of data from hard-to-scrape websites.
In such scenarios, what you require is an expert enterprise-grade web scraping service provider like ScrapeHero. Let’s connect to meet your custom web scraping, APIs, alternative data, POI location data, and RPA needs.
Frequently Asked Questions
- What are the most important HTTP headers for web scraping ?
HTTP headers are essential for both web scraping and web development. Some of the most important HTTP headers for web scraping include User-Agent, Accept, Authorization, Cache-Control, Cookie, Content-Type, Host, Referer, Connection, Accept-Encoding, etc. - How do I find headers for scraping?
You can find the correct HTTP headers for web scraping using Developer Tools, Command-Line tools like Curl, or applications like Postman. In Python, you can use libraries like Requests to print out the headers after making a request. - What should HTTP headers include?
HTTP headers should include common Request headers like User-Agent, common Response headers like Content-Type, and some optional headers like connection. - Are HTTP headers necessary?
HTTP headers are not always necessary for every single HTTP request, but they are practically mandatory for responsible web scraping. These headers can avoid blocking by mimicking browser behavior and ensuring the data you retrieve is in a format your scraper can handle. - What are Request headers ?
A Request header is an HTTP header that contains information about the resource or the client who is requesting the resource. They can be considered as one of the essential HTTP headers for web scraping. - How can you use Python requests with headers?
Using Python’s Requests library with headers is beneficial for web scraping tasks. To add headers to the request, use the headers parameter in requests.get() or any other method like requests.post().



