
Have you ever encountered the term “browser fingerprinting” while surfing the internet?
Browser fingerprinting is the process of collecting information by the server about the client, such as browser information, time zones, default language, operating system, and more. These data can be collected using specific JS scripts.
The data collected serves as a ‘fingerprint’ that can uniquely identify the client, enabling the server to monitor the client’s activities
Browser fingerprinting is among the most effective methods to detect a scraper. If a client generates any malicious requests, the server might flag the client as a bot and potentially block subsequent requests.
How Browser Fingerprinting Works
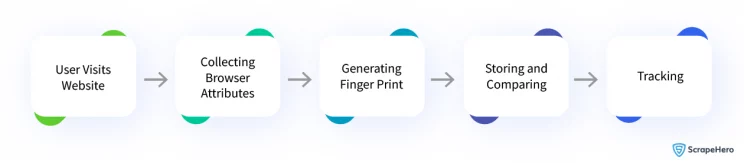
Browser fingerprinting collects various attributes of a user’s web browser and device to create a unique identifier known as a fingerprint.
- These attributes include
- user-agent string
- default language
- screen resolutions
- browser plugins
- HTTP headers
and more.
By combining these attributes and hashing, it can generate a fingerprint value. These fingerprint values can be used to distinguish one browser instance from another.
For browser fingerprinting, modern websites use JavaScript code or server-side analysis to gather these attributes and compare them with a database of known fingerprints to identify and differentiate between the human user and automated scraping scripts.
Common Techniques Used in Browser Fingerprinting
User-Agent Tracking
The User-agent header is essential in browser fingerprinting for detecting bots(automated scraping scripts). It helps the web server to uniquely identify the scraping tool by analyzing its user-agent strings. Suspicious or unrecognized user-agents can flag the client as a bot and block further scraping activities.
Web Scrapers can mimic genuine browsers’ behavior by setting their user-agent string to match any popular browser. We can reduce detection by rotating the user-agents as shown below. But also other fingerprints can be used to detect the scraping activity.
import requests
import random
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36",
# Add more user-agents here
]
def get_random_user_agent():
return random.choice(user_agents)
url = "https://www.example.com"
headers = {'User-Agent': get_random_user_agent()}
response = requests.get(url, headers=headers)
In summary, the User-Agent plays a crucial role in browser fingerprinting for web scraping detection and other fingerprinting techniques websites use.
Canvas Fingerprinting
Canvas fingerprinting is a technique used by websites to uniquely identify and track users by exploiting the HTML5 canvas element. It works by leveraging the fact that different computer systems and browsers render graphics slightly differently, resulting in variations in how the canvas is drawn.
In web scraping, canvas fingerprinting can pose challenges because it can be used as a countermeasure to detect and prevent scraping activities. Here’s how it works:
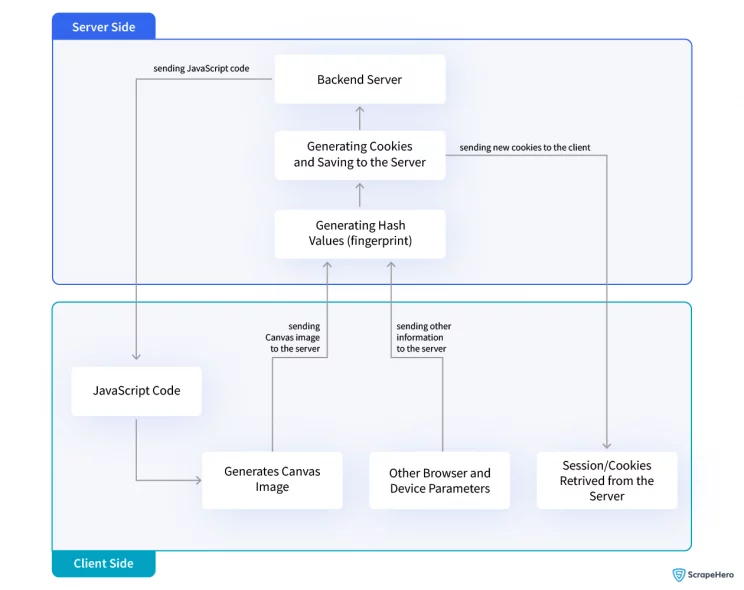
- When a user visits a website, the website generates a canvas image containing text or graphics using JavaScript code.
- The user’s browser then renders the canvas image.
- The website retrieves the rendered canvas image data and performs calculations or applies algorithms to generate a unique identifier, known as the fingerprint.
- The fingerprint is sent back to the server, where it can be associated with the user’s session or stored for tracking purposes.
Canvas fingerprinting can make it more difficult to scrape websites without detection. Since each user or scraping bot will have a unique fingerprint, websites can use this information to identify and block scraping activities.
To mitigate canvas fingerprinting, web scrapers can employ various techniques:
- Disable canvas rendering: Some scraping tools or libraries provide options to disable canvas rendering. By doing so, the fingerprinting techniques relying on canvas data become ineffective.
- User-agent rotation: Rotating user agents or using user-agent strings commonly associated with popular web browsers can help mask the identity of the scraping bot and reduce the likelihood of being detected through fingerprinting techniques.
- IP rotation: Rotating IP addresses can help avoid detection, as fingerprinting may be tied to a specific IP address.
- JavaScript manipulation: Manipulating or patching JavaScript code related to canvas fingerprinting techniques can disrupt fingerprint generation.
It’s worth noting that canvas fingerprinting is just one of many techniques employed by websites to detect and prevent web scraping.
Scraping techniques and countermeasures are continually evolving, so staying updated with the latest advancements in web scraping and adapting your scraping strategies accordingly is essential.
WebGL
WebGL fingerprinting is a method used to create a unique identifier for web browsers based on their WebGL capabilities. It is a JavaScript API that enables browsers to render 2D and 3D graphics without additional plugins.
Different browsers and devices have varying levels of WebGL support and features, making their implementations distinct. By analyzing these differences, WebGL fingerprinting generates a unique profile for each browser. This technique is employed for tracking and analytics purposes, allowing websites to identify and differentiate individual browsers even if cookies are disabled or cleared.
WebGL fingerprinting collects information about a browser’s WebGL implementation, including supported graphics features, available extensions, and rendering performance. This information is combined to create a fingerprint that serves as a browser identifier. WebGL fingerprinting assists websites in tracking user behavior, delivering targeted content, and recognizing returning users.
However, it also raises privacy concerns as it enables cross-site tracking without explicit user consent. WebGL fingerprinting is just one component of browser fingerprinting and can be combined with other techniques like canvas fingerprinting and user agent analysis to create a comprehensive browser fingerprint.
CSS Properties
CSS properties fingerprinting identifies and tracks users based on their browser’s supported CSS properties. It helps detect and prevent scraping by generating a unique fingerprint. Websites collect CSS properties data to create the fingerprint.
Each user has a unique fingerprint that can be associated with their session. Scrapers can rotate user agents and IP addresses to mitigate CSS properties fingerprinting. Using popular user agent strings masks the scraper’s identity. Rotating IP addresses avoids detection linked to a specific IP.
Scrapers can also normalize CSS properties and manipulate JavaScript code. Normalizing properties reduces fingerprint variations, and JavaScript manipulation disrupts fingerprint generation. CSS properties fingerprinting is one technique among many used to detect scraping. Staying updated with scraping advancements is essential to overcome countermeasures.
TLS Fingerprinting
TLS fingerprinting identifies and tracks users based on their TLS connection characteristics. It helps detect and prevent scraping by generating a unique fingerprint. TLS parameters observed during the handshake, such as version, cipher suites, and extensions, are used to create the fingerprint.
Each user has a unique fingerprint associated with their session. To mitigate TLS fingerprinting, scrapers can rotate user agents and IP addresses. Using popular user agent strings masks the scraper’s identity. Rotating IP addresses avoids detection tied to a specific IP. Scrapers can also use a common TLS configuration and implement TLS session resumption.
A common TLS configuration makes the fingerprint less distinguishable. TLS session resumption maintains the same session, reducing fingerprint generation. TLS fingerprinting is one technique among many used to detect scraping. Staying updated with scraping advancements is crucial to overcome countermeasures.
What are Browser Leaks?
Browser leaks refer to unintentional disclosures of sensitive information or identifiable data that can occur when using a web browser. These leaks can inadvertently reveal details about the user’s system, browsing habits, or even personally identifiable information (PII). Here are a few common types of browser leaks:
- IP Address Leak: The IP address assigned to a user’s device can be exposed, potentially revealing their approximate physical location and enabling tracking.
- DNS Leak: DNS (Domain Name System) translates domain names into IP addresses. If the browser fails to route DNS queries through the intended channels, the DNS requests may be exposed, leaking the websites being accessed.
- WebRTC Leak: WebRTC (Web Real-Time Communication) allows direct communication between browsers. However, it can inadvertently disclose the user’s true IP address, even if a VPN or proxy is used.
- Geolocation Leak: Websites may request access to the user’s geolocation for legitimate purposes. However, a browser leak can expose this information without explicit user consent.
- Plugin or Extension Leak: Outdated or vulnerable browser plugins or extensions can potentially leak sensitive information or grant unauthorized access to user data.
- Referrer Leak: When navigating from one website to another, the previous website’s URL, known as the referrer, is typically sent in the HTTP headers. This can inadvertently disclose browsing history.
- Cache and History Leaks: Browser caching and history mechanisms can inadvertently expose previously visited websites or sensitive data, leading to privacy risks.
- User Agent Leak: The user agent string, which includes details about the browser and operating system, can be exposed, potentially aiding in device fingerprinting.
Browser leaks can have privacy and security implications, as they may allow malicious actors or unauthorized entities to track users, collect sensitive information, or exploit vulnerabilities.
It’s vital to stay updated with browser security settings, use reputable plugins/extensions, and employ appropriate privacy measures, such as VPNs, to mitigate potential leaks and protect personal information.
Best Practices to Bypass Browser Fingerprinting in Web Scraping
- User Agent Rotation: Rotate the user agent string of your scraping tool or library to simulate different browsers and devices. This helps prevent consistent identification based on a specific user agent.
- IP Rotation: Utilize proxy servers or VPNs to rotate your IP address and prevent tracking based on a single IP. This makes it harder to link scraping activity to a specific user.
- Disable JavaScript: Consider disabling JavaScript during scraping, as JavaScript can provide additional information contributing to fingerprinting. However, be mindful of the impact on scraping functionality, as some websites heavily rely on JavaScript.
- Limit Canvas Fingerprinting: Modify or block the HTML5 canvas API to disrupt canvas fingerprinting techniques, which rely on extracting unique graphics rendering data. Tools like CanvasBlocker can help in this regard.
- Adjust Time zone and Language Settings: Set your time zone and language settings to match those commonly used by regular users to reduce distinguishable fingerprint attributes.
- Handle WebRTC Leaks: WebRTC leaks can expose your real IP address. Disable WebRTC functionality or use browser extensions like WebRTC Leak Prevent to mitigate this risk.
- Manage Cookies: Control and manage cookies effectively by selectively accepting or blocking them. Clear cookies regularly to prevent tracking through cookie-based fingerprinting.
- Avoid Plugins and Extensions: Reduce the use of browser plugins and extensions, as they can contribute to a unique fingerprint. Stick to essential and reputable ones when scraping.
- Emulate Human Behavior: Mimic human behavior by adding delays between requests, interacting with web elements (clicks, scrolls), and navigating through the website in a human way. This helps avoid patterns that can be associated with automated scraping.
Wrapping Up
Browser fingerprinting is a complex and evolving technology, and it’s challenging to eliminate fingerprinting risks completely. Implementing a combination of these best practices will help minimize the likelihood of being identified and tracked while web scraping.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



