
Faking and rotating user-agents in Python is a common practice that helps avoid detection by mimicking different users in web scraping.
You can bypass rate limits, access different websites, and improve the quality of the extracted data when you fake user-agents.
This article discusses how to fake and rotate user-agents in Python using different methods depending on your blocking level.
What Is a User-Agent?
A User-Agent is a string that a browser or application sends to each website you visit.
A typical User-Agent string contains details like – the application type, operating system, software vendor, or software version of the requesting software User-Agent.
Web servers use this data to assess your computer’s capabilities and optimize a page’s performance and display.
User-agents are sent as a Request header called “User-Agent.”
User-Agent: Mozilla/<version> (<system-information>) <platform> (<platform-details>) <extensions>
The User-Agent string for Chrome 83 on Mac OS 10.15 is: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36
Why Should You Use a User-Agent?
Most websites block requests without a valid browser as a User-Agent.
For example, here are the User-Agent and other headers sent by default when making a simple Python request.
import requests
from pprint import pprint
#Lets test what headers are sent by sending a request to HTTPBin
r = requests.get('http://httpbin.org/headers')
pprint(r.json())
{'headers': {'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate',
'Host': 'httpbin.org',
'User-Agent': 'python-requests/2.23.0',
'X-Amzn-Trace-Id': 'Root=1-5ee7a417-97501ac8e10eb62866e09b9c'}}
Note: Ignore the X-Amzn-Trace-Id as it is not sent by Python requests but generated by the Amazon Load Balancer used by HTTPBin.
Any website could identify that this came from Python requests and may already have measures to block such user-agents.
User-Agent spoofing is when you replace the User-Agent string your browser sends as an HTTP header with another character string.
Major browsers have extensions that enable users to change their User-Agent, a feature used for User-Agent spoofing.
You can fake user-agents in Python and rotate them by changing the request’s User-Agent header and bypassing website User-Agent-based blocking scripts.
How To Change User-Agent Requests in Python
To change the User-Agent requests in Python, you can pass a dictionary with a key ‘User-Agent’ with the value as the User-Agent string of a real browser.
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36See the code:
headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36"}
#Lets test what headers are sent by sending a request to HTTPBin
r = requests.get('http://httpbin.org/headers',headers=headers)
pprint(r.json())
1. {'headers': {'Accept': '*/*',
2. 'Accept-Encoding': 'gzip, deflate',
3. 'Host': 'httpbin.org',
4. 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) '
5. 'AppleWebKit/537.36 (KHTML, like Gecko) '
6. 'Chrome/83.0.4103.97 Safari/537.36',
7. 'X-Amzn-Trace-Id': 'Root=1-5ee7b614-d1d9a6e8106184eb3d66b108'}}
Let’s ignore the headers that start with X- as they are generated by Amazon Load Balancer used by HTTPBin and not from what you sent to the server.
However, websites that use more sophisticated anti-scraping tools can identify this request did not come from Chrome.
Why Send a Complete Set of Headers?
Simply sending a User-Agent is not enough. You must also send a complete set of headers because the other headers you send may differ from those typically sent by a real Chrome browser.
Here is what Chrome would have sent:
8. {
9. "headers": {
10. "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
11. "Accept-Encoding": "gzip, deflate",
12. "Accept-Language": "en-GB,en-US;q=0.9,en;q=0.8",
13. "Dnt": "1",
14. "Host": "httpbin.org",
15. "Upgrade-Insecure-Requests": "1",
16. "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36",
17. "X-Amzn-Trace-Id": "Root=1-5ee7bae0-82260c065baf5ad7f0b3a3e3"
18. }
19. } It is clear that some headers are missing or have the wrong values:
- Accept (had */*, instead of text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9) – Lines 1 & 10
- Accept-Language – Line 12
- Dnt – Line 13
- Upgrade-Insecure-Requests – Line 15
Anti-scraping tools can easily detect this request as a bot, so sending a User-Agent wouldn’t be good enough to bypass the latest anti-scraping tools and services.
Let’s add these missing headers and make the request look like it came from a real Chrome browser.
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "en-GB,en-US;q=0.9,en;q=0.8",
"Dnt": "1",
"Host": "httpbin.org",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36",
}
r = requests.get("http://httpbin.org/headers",headers=headers)
pprint(r.json())
{'headers': {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'en-GB,en-US;q=0.9,en;q=0.8',
'Dnt': '1',
'Host': 'httpbin.org',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/83.0.4103.97 Safari/537.36',
'X-Amzn-Trace-Id': 'Root=1-5ee7bbec-779382315873aa33227a5df6'}}
Now, this request looks more like it came from Chrome 83 and should get you past most anti-scraping tools—if you are not overloading the website with requests.
Why Should You Rotate User-Agents in Python
Randomize the requests if you are making a large number of requests for scraping a website.
Change the exit IP address of the request using rotating proxies and send a different set of HTTP headers to make it look like the request is coming from other computers.
How To Rotate User-Agents in Python
To fake user-agents in Python and rotate them, you need to do:
- Collect a list of User-Agent strings of some recent real browsers from WhatIsMyBrowser.com
- Put them in a Python List
- Make each request pick a random string from this list and send the request with the ‘User-Agent’ header as this string
Rotate User-Agents in Python Using Requests
import requests
import random
user_agent_list = [
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.1.1 Safari/605.1.15',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:77.0) Gecko/20100101 Firefox/77.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:77.0) Gecko/20100101 Firefox/77.0',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36',
]
url = 'https://httpbin.org/headers'
for i in range(1,4):
#Pick a random User-Agent
user_agent = random.choice(user_agent_list)
#Set the headers
headers = {'User-Agent': user_agent}
#Make the request
response = requests.get(url,headers=headers)
print("Request #%d\nUser-Agent Sent:%s\n\nHeaders Received by HTTPBin:"%(i,user_agent))
print(response.json())
print("-------------------")
Request #1
User-Agent Sent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.1.1 Safari/605.1.15
Headers Received by HTTPBin:
{'headers': {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'Host': 'httpbin.org', 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.1.1 Safari/605.1.15', 'X-Amzn-Trace-Id': 'Root=1-5ee7c263-b009c26abdfd7cb2c05e06ee'}}
-------------------
Request #2
User-Agent Sent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.1.1 Safari/605.1.15
Headers Received by HTTPBin:
{'headers': {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'Host': 'httpbin.org', 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.1.1 Safari/605.1.15', 'X-Amzn-Trace-Id': 'Root=1-5ee7c264-975128287d5b3fa1fc9d0f8d'}}
-------------------
Request #3
User-Agent Sent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:77.0) Gecko/20100101 Firefox/77.0
Headers Received by HTTPBin:
{'headers': {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'Host': 'httpbin.org', 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:77.0) Gecko/20100101 Firefox/77.0', 'X-Amzn-Trace-Id': 'Root=1-5ee7c266-8d04316e70f56abd1ec7beee'}}
-------------------
The Right Way To Rotate User-Agents in Python
It is easier for bot detection tools to block you when you are not sending the other correct headers for the User-Agent you are using.
To get better results and less blocking, rotate the complete set of headers associated with each User-Agent you use.
You can prepare a list by taking a few browsers, visiting
HTTPBin headers, and copying each User-Agent’s header.
Note: Remove the headers that start with X- in HTTPBin
Browsers may behave differently to different websites based on the features and compression methods each website supports. So,
1. Open an incognito or a private tab in a browser, go to the Network tab of each browser’s developer tools, and visit the link you are trying to scrape directly in the browser.
Copy the curl command to that request –
curl 'https://www.amazon.com/' -H 'User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:77.0) Gecko/20100101 Firefox/77.0' -H 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8' -H 'Accept-Language: en-US,en;q=0.5' --compressed -H 'DNT: 1' -H 'Connection: keep-alive' -H 'Upgrade-Insecure-Requests: 1'
2. Paste into curlconverter and just take the value of the variable headers and paste into a list.
{
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:77.0) Gecko/20100101 Firefox/77.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'en-US,en;q=0.5',
'DNT': '1',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
}
Essential Tips to Rotate User-Agents and Corresponding Headers
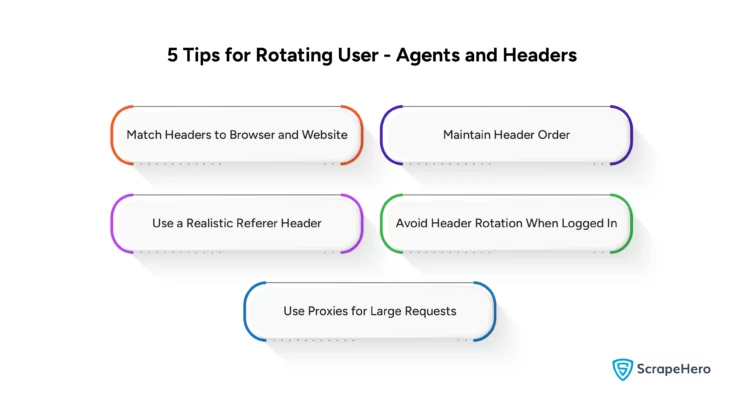
To make your requests from web scrapers look as if they came from a real browser, you need to:
-
Match Headers to Browser and Website
Ensure your headers are the right for the browser and website you’re scraping to mimic actual browser behavior. -
Maintain Header Order
Send headers in the correct order as a real browser would. Although HTTP specs say that the order of the HTTP headers does not matter, some bot detection tools check that. -
Use a Realistic Referer Header
Include a Referer header with the previous page you visited or Google to make it look natural. -
Avoid Header Rotation When Logged In
There is no point rotating the headers if you log in to a website or keep session cookies, as the site can identify you regardless. -
Use Proxies for Large Requests
For large-scale web scraping, use proxy servers and assign different IPs for each browser session.
The Complete Code
import requests
import random
from collections import OrderedDict
# This data was created by using the curl method explained above
headers_list = [
# Firefox 77 Mac
{
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:77.0) Gecko/20100101 Firefox/77.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.5",
"Referer": "https://www.google.com/",
"DNT": "1",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1"
},
# Firefox 77 Windows
{
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:77.0) Gecko/20100101 Firefox/77.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.5",
"Accept-Encoding": "gzip, deflate, br",
"Referer": "https://www.google.com/",
"DNT": "1",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1"
},
# Chrome 83 Mac
{
"Connection": "keep-alive",
"DNT": "1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Sec-Fetch-Site": "none",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Dest": "document",
"Referer": "https://www.google.com/",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "en-GB,en-US;q=0.9,en;q=0.8"
},
# Chrome 83 Windows
{
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Sec-Fetch-Site": "same-origin",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-User": "?1",
"Sec-Fetch-Dest": "document",
"Referer": "https://www.google.com/",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "en-US,en;q=0.9"
}
]
# Create ordered dict from Headers above
ordered_headers_list = []
for headers in headers_list:
h = OrderedDict()
for header,value in headers.items():
h[header]=value
ordered_headers_list.append(h)
url = 'https://httpbin.org/headers'
for i in range(1,4):
#Pick a random browser headers
headers = random.choice(headers_list)
#Create a request session
r = requests.Session()
r.headers = headers
response = r.get(url)
print("Request #%d\nUser-Agent Sent:%s\n\nHeaders Recevied by HTTPBin:"%(i,headers['User-Agent']))
print(response.json())
print("-------------------")
Request #1
User-Agent Sent:Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:77.0) Gecko/20100101 Firefox/77.0
Headers Received by HTTPBin:
{'headers': {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'en-US,en;q=0.5', 'Dnt': '1', 'Host': 'httpbin.org', 'Referer': 'https://www.google.com/', 'Upgrade-Insecure-Requests': '1', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:77.0) Gecko/20100101 Firefox/77.0', 'X-Amzn-Trace-Id': 'Root=1-5ee83553-d3b3cfdd774dec24971af289'}}
-------------------
Request #2
User-Agent Sent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:77.0) Gecko/20100101 Firefox/77.0
Headers Received by HTTPBin:
{'headers': {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', 'Accept-Encoding': 'identity', 'Accept-Language': 'en-US,en;q=0.5', 'Dnt': '1', 'Host': 'httpbin.org', 'Referer': 'https://www.google.com/', 'Upgrade-Insecure-Requests': '1', 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:77.0) Gecko/20100101 Firefox/77.0', 'X-Amzn-Trace-Id': 'Root=1-5ee83555-2b6fa55c3f38ba905eeb3a9e'}}
-------------------
Request #3
User-Agent Sent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:77.0) Gecko/20100101 Firefox/77.0
Headers Received by HTTPBin:
{'headers': {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', 'Accept-Encoding': 'identity', 'Accept-Language': 'en-US,en;q=0.5', 'Dnt': '1', 'Host': 'httpbin.org', 'Referer': 'https://www.google.com/', 'Upgrade-Insecure-Requests': '1', 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:77.0) Gecko/20100101 Firefox/77.0', 'X-Amzn-Trace-Id': 'Root=1-5ee83556-58ee2480f33e0b00f02ff320'}}
-------------------
Note: HTTPBin does not show the order in which the requests were sent; it orders them alphabetically.
Wrapping Up
By faking and rotating user-agents, you can prevent websites from blocking web scraping to some extent, but advanced anti-scraping technologies can detect more than just User Agents and IP addresses.
Techniques such as SSL/TLS fingerprinting can expose web scraping. If proxies are already flagged, rotating headers may be ineffective. Also, the complexity of bypassing such methods may exceed simple solutions.
In such situations, you can depend on a fully managed enterprise-grade web scraping service provider like ScrapeHero.
With a global infrastructure, ScrapeHero web scraping services make large-scale data extraction effortless. We can handle complex JavaScript/AJAX sites, CAPTCHA, and IP blacklisting transparently, fulfilling your data needs.
Frequently Asked Questions
In Python, you can use the fake_useragent library to generate a random User-Agent.
To set user-agents in Python, import requests. Then, use the headers parameter in your request like:
response = requests.get('https://example.com', headers={'User-Agent': 'Your User-Agent String'}).
To change User-Agent requests in Python first, import requests and then pass a custom User-Agent string in the headers of your request.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



