

Do you know that Requests is one of the most popular libraries used while web scraping with Python? That’s because it provides intuitive methods to handle HTTP requests—a popular way to access websites. Want to know more? Here’s an in-depth tutorial showing how to scrape websites with the Python requests library.
Scrape Websites with the Python Requests Library: An Overview
While you can’t scrape websites with the Python request library alone, you can get the HTML source code of web pages using it. Web scraping with Python requests includes two core steps:
- Sending GET requests
- Parsing the response text
After extracting the response text—which contains the HTML source code—you’ll need to use parsing libraries, like lxml, to pull the data points you need.
Setting Up The Environment
Since the requests library is external, you need to install it using Python’s package manager pip. You also need a parsing library; here, the code uses lxml, which is also an external library and is installable with pip.
pip install requests lxml
Writing the Code
This tutorial scrapes the website scrapeme.live, which is a mock website used for scraping experiments. Here’s the workflow to extract data with Python:
- Navigate to the website
- Locate the URLs of all the products by navigating through the listing pages
- Extract these details from each product page:
- Name
- Description
- Price
- Stock
- Image URL
- Product URL
- Save the collected data to a CSV file
Now, let’s implement this workflow.

Import the Required Packages
Start by importing the required packages. Apart from requests and lxml mentioned above, this code also imports the csv module. This module saves the extracted data to a CSV file.
import requests
from lxml import html
import csvSend a Request to the Website
Send an HTTP request to https://scrapeme.live/shop using the get() method. Use appropriate headers while sending the request to pose as a request originating from a user.
headers = {
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Sa"
"fari/537.36",
"Accept-Language": "en-US,en;q=0.5"
}
response = requests.get(url, headers=headers)Check the Response Status Code
Even with headers, the target server may detect your scraper and send an error message. You can check whether or not the request was successful by checking if the status code is 200.
def verify_response(response):
return True if response.status_code == 200 else FalseaIf the status code is not 200, you may retry; use a loop to retry multiple times.
max_retry = 3
while max_retry >= 1:
response = requests.get(url, headers=headers)
if verify_response(response):
return response
else:
max_retry -= max_retry
Get the Product URLs
If the response is valid, move on to extracting the data points.
First, get URLs from the target page; you need to parse the response to do so.
The code uses lxml to parse the response text and uses XPaths to locate the data points. You can figure out which XPaths to use by looking at the HTML code of the page.
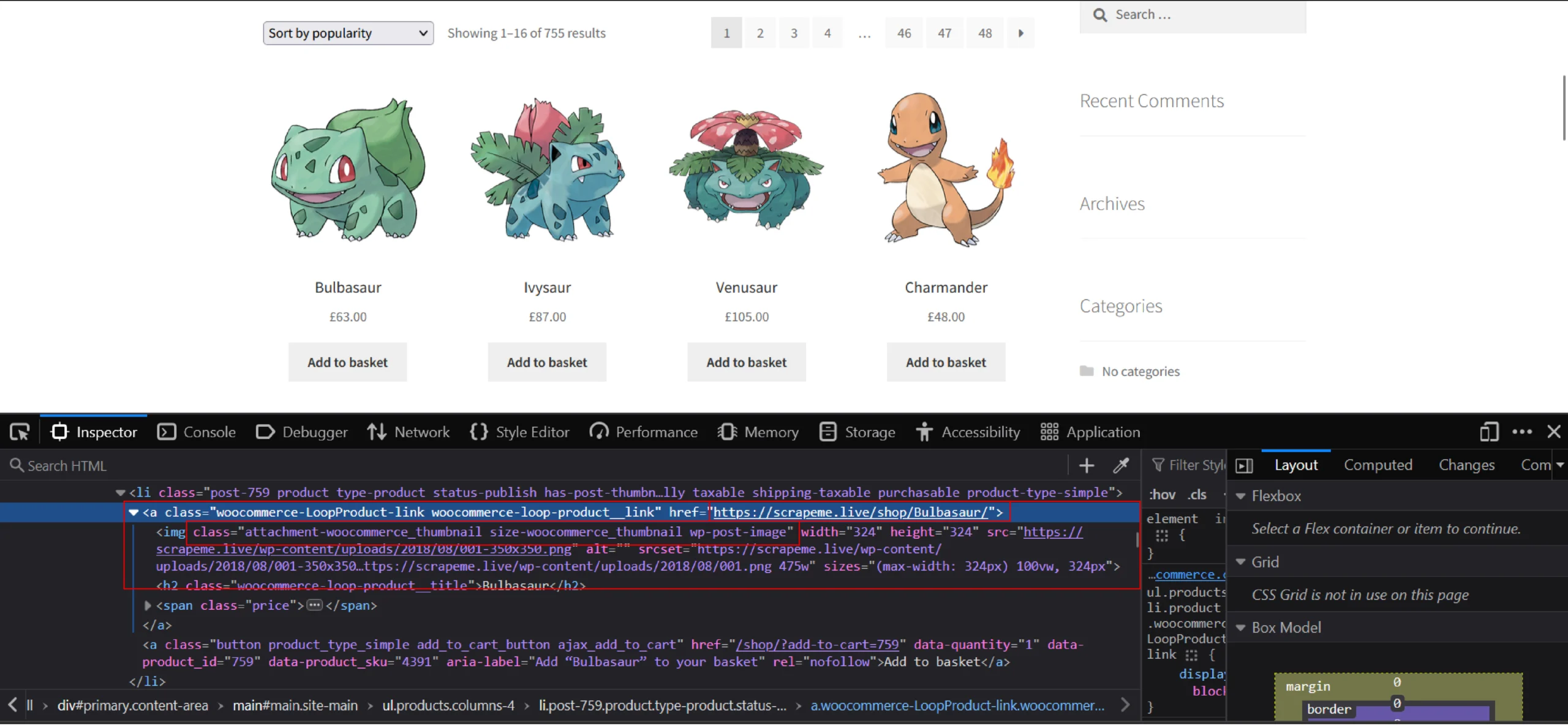
From the screenshot, it is clear that node ‘a’, which has the class name class=”woocommerce-LoopProduct-link woocommerce-loop-product__link,” contains the URL to the product page.
Since node “a” comes under node ‘li,’ its XPATH is “//li/a[contains(@class, “product__link”)].” You can then get the URL from the “href” attribute of that node:
from lxml import html
parser = html.fromstring(response.text)
product_urls = parser.xpath('//li/a[contains(@class, "product__link")]/@href')Get the Next-Page URL
The scraper extracts the product URLs from multiple pages, so the workflow becomes:
- Get the URL of the next-page link
- Make a request to the URL
- Extract all the product links and store them in a list
- Repeat the process
To get the next-page URL, analyze the HTML code and figure out the XPath of the next-page link.
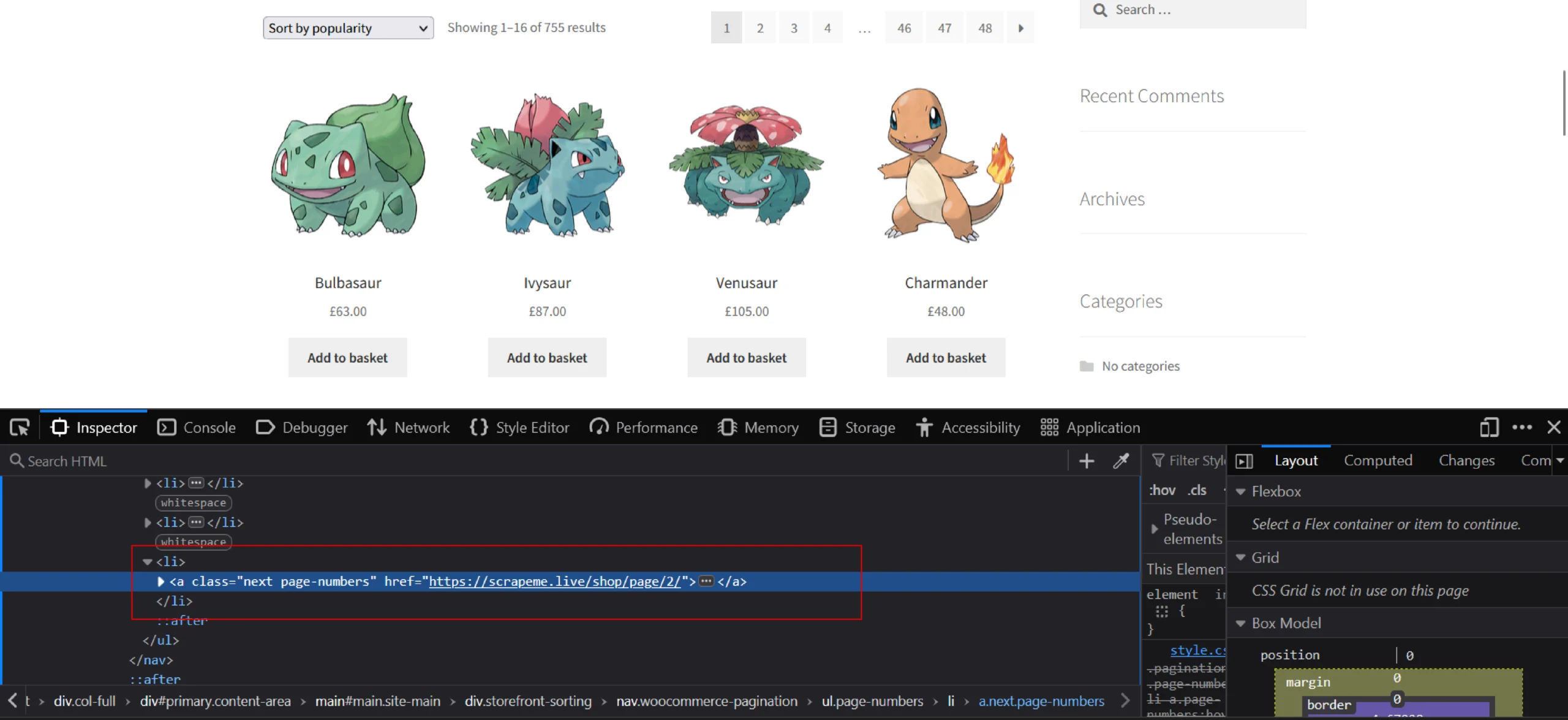
from lxml import html
parser = html.fromstring(response.text)
next_page_url = parser.xpath('(//a[@class="next page-numbers"])[1]/@href')[0]You can now make a request to this next page URL, get the product-page links, and repeat the process with other pages.
After getting all the product URLs, you can start pulling the name, description, price, stock, and image URLs from the product pages.
Name
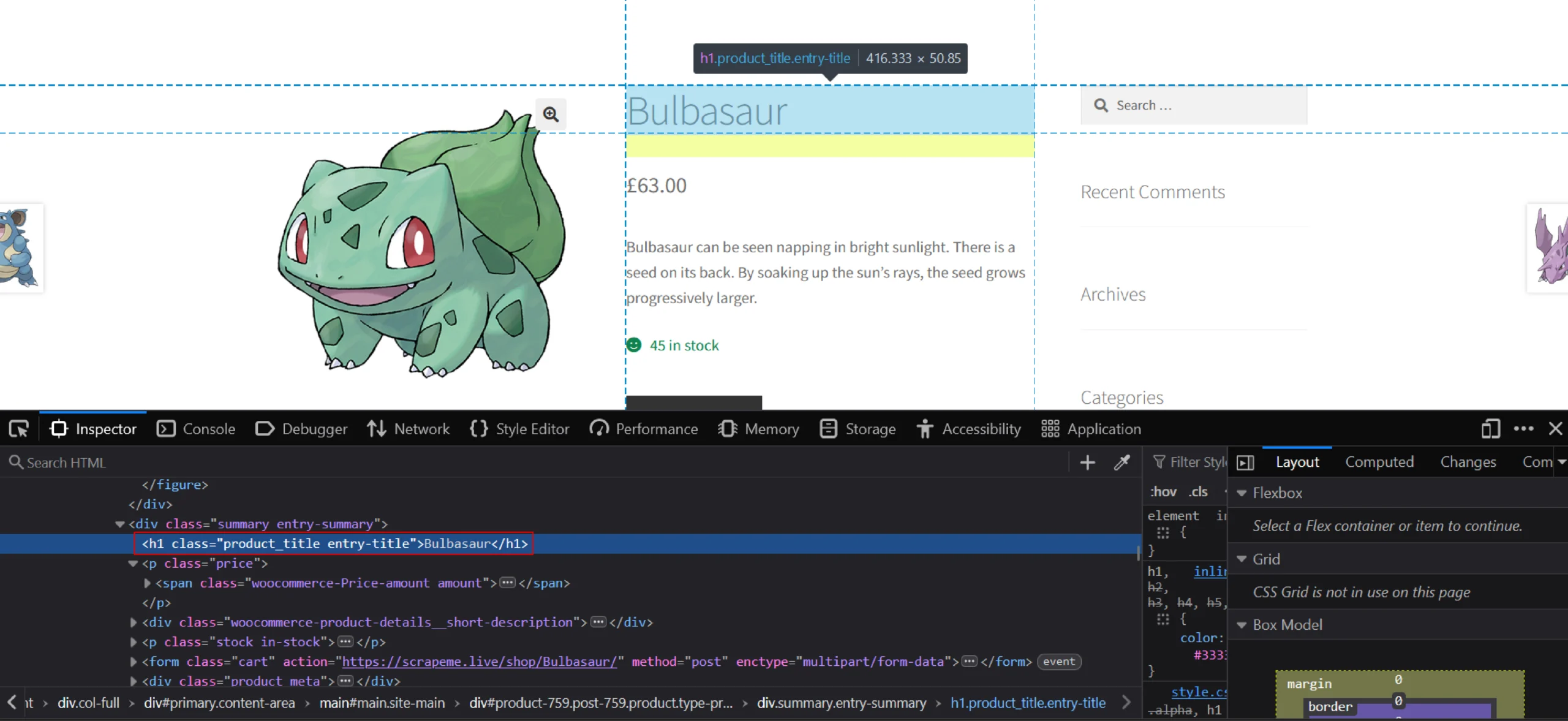
From the image, it is clear that node h1 contains the name of the product. You can see that the product page does not have any other h1 node. Simply call the XPath //h1 to select that particular node.
Use the following code since the text is inside the node:
title = parser.xpath('//h1[contains(@class, "product_title")]/text()')Description
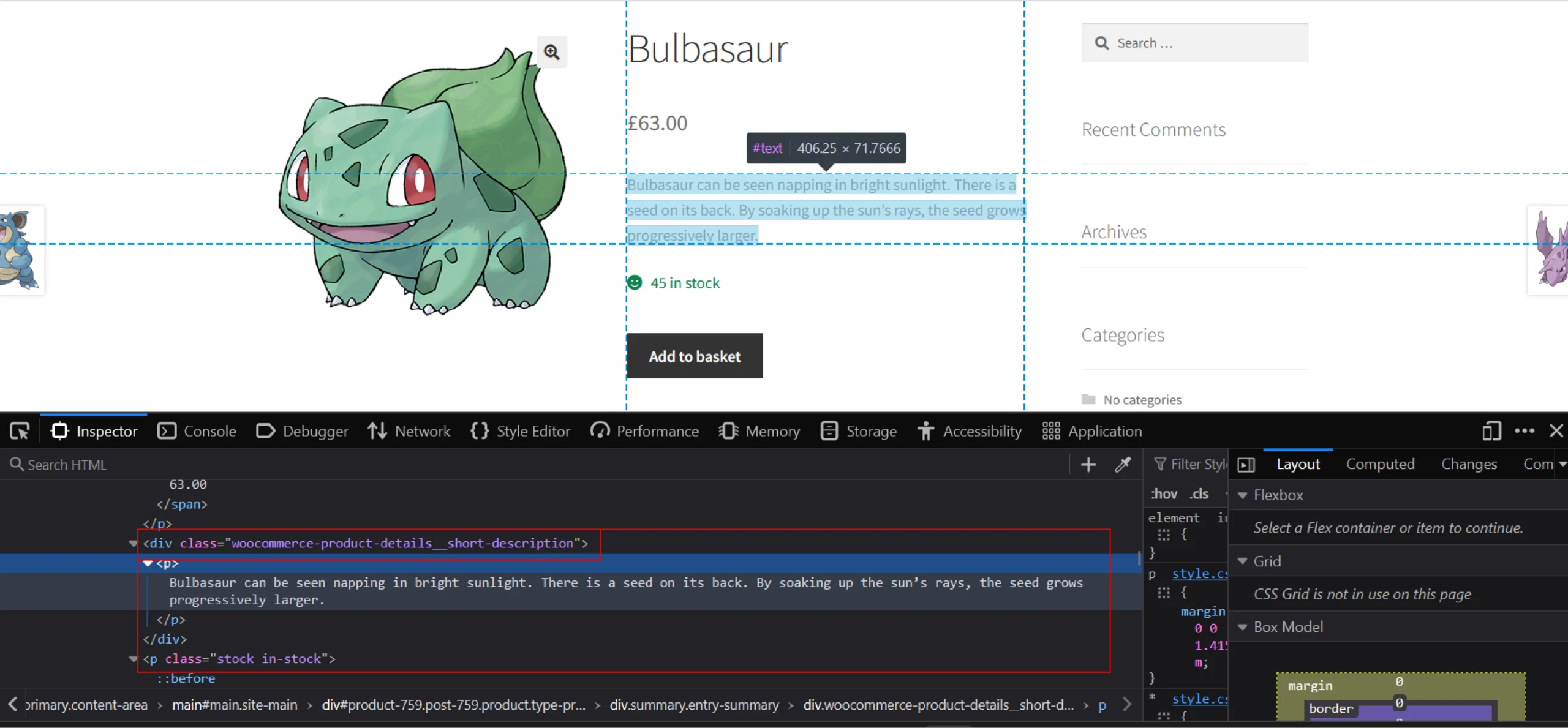
Here, the product description is inside the node p. You can also see that it is inside the div with the class name substring ‘product-details__short-description’. Collect the text inside it as follows:
description = parser.xpath('//div[contains(@class,"product-details__short-description")]//text()')Stock
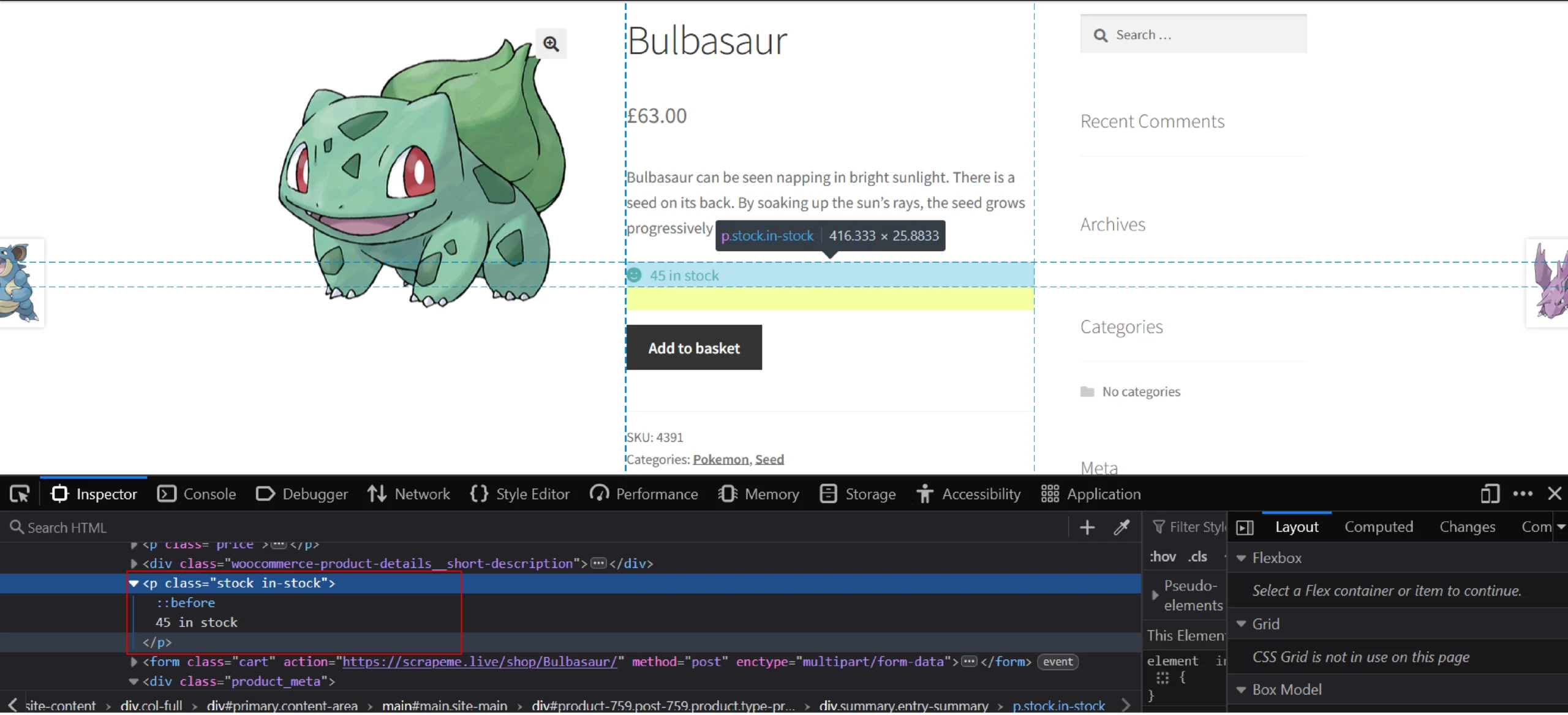
From the image, it is evident that stock is directly present inside the node p, whose class contains the string ‘in-stock.’ Use this code to collect data from it:
stock = parser.xpath('//p[contains(@class, "in-stock")]/text()')Price
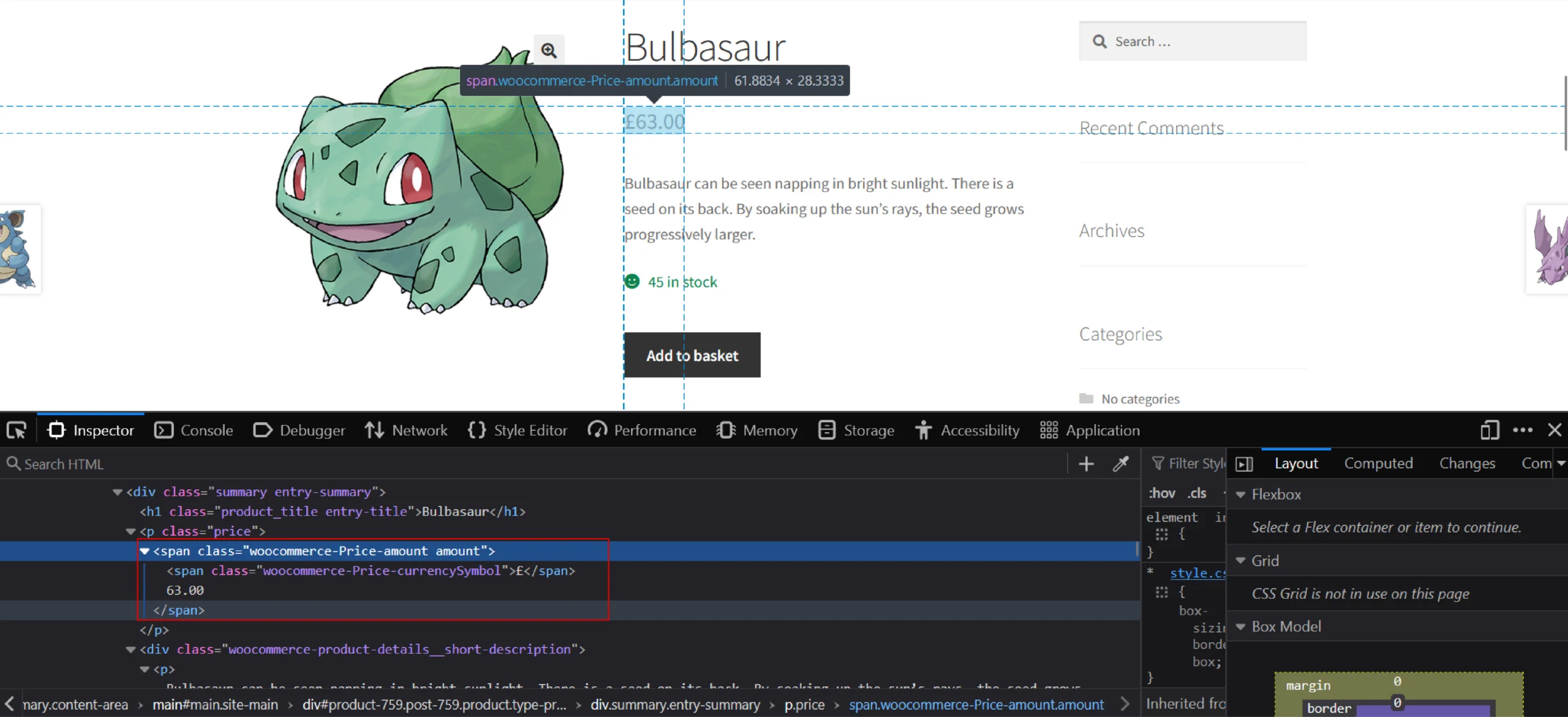
Here, the price can be directly seen in the node p having class price. So, use the code to get the actual price value of the product:
price = parser.xpath('//p[@class="price"]//text()')
price = clean_string(price)Image URL
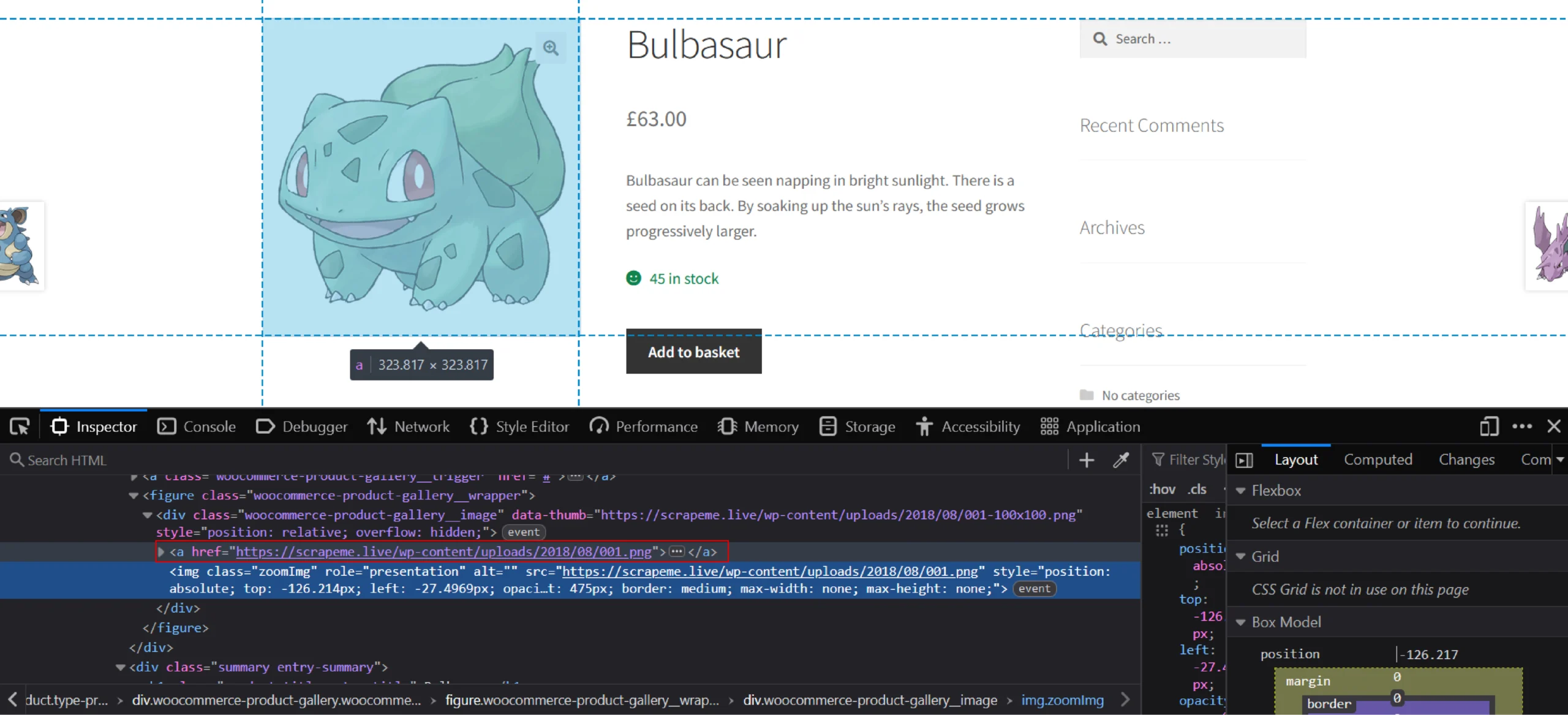
In the screenshot, the attribute href of the node ‘a’ is highlighted. It is from this href attribute that you will get the image URL.
image_url = parser.xpath('//div[contains(@class, "woocommerce-product-gallery__image")]/a/@href')
Image_url = clean_string(list_or_txt=image_url, connector=' | ')Clean the Data
In all the above code snippets, parser.xpath() returns a list of string elements. This string may have extra spaces, so create a function to remove them.
def clean_string(list_or_txt, connector=' '):
if not list_or_txt:
return None
return ' '.join(connector.join(list_or_txt).split())Additionally, create a function to remove the text ‘ in stock’ that you’ll get when extracting the stock number.
def clean_stock(stock):
stock = clean_string(stock)
if stock:
stock = stock.replace(' in stock', '')
return stock
else:
return NoneHere’s the complete code that uses everything you’ve read so far.
import csv
from lxml import html
import requests
def verify_response(response):
"""
Verify if we received a valid response or not
"""
return True if response.status_code == 200 else False
def send_request(url):
"""
Send request and handle retries.
:param url:
:return: Response we received after sending a request to the URL.
"""
headers = {
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Sa"
"fari/537.36",
"Accept-Language": "en-US,en;q=0.5"
}
max_retry = 3
while max_retry >= 1:
response = requests.get(url, headers=headers)
if verify_response(response):
return response
else:
max_retry -= max_retry
print("Invalid response received even after retrying. URL with the issue is:", url)
raise Exception("Stopping the code execution as invalid response received.")
def get_next_page_url(response):
"""
Collect pagination URL.
:param response:
:return: next listing page URL
"""
parser = html.fromstring(response.text)
next_page_url = parser.xpath('(//a[@class="next page-numbers"])[1]/@href')[0]
return next_page_url
def get_product_urls(response):
"""
Collects all product URLs from a listing page response.
:param response:
:return: list of URLs. List of product page URLs returned.
"""
parser = html.fromstring(response.text)
product_urls = parser.xpath('//li/a[contains(@class, "product__link")]/@href')
return product_urls
def clean_stock(stock):
"""
Clean the data stock by removing unwanted text present in it.
:param stock:
:return: Stock data. The stock number will be returned by removing the extra string.
"""
stock = clean_string(stock)
if stock:
stock = stock.replace(' in stock', '')
return stock
else:
return None
def clean_string(list_or_txt, connector=' '):
"""
Clean and fix the list of objects received. We are also removing unwanted white spaces.
:param list_or_txt:
:param connector:
:return: Cleaned string.
"""
if not list_or_txt:
return None
return ' '.join(connector.join(list_or_txt).split())
def get_product_data(url):
"""
Collect all details of a product.
:param url:
:return: All data of a product.
"""
response = send_request(url)
parser = html.fromstring(response.text)
title = parser.xpath('//h1[contains(@class, "product_title")]/text()')
price = parser.xpath('//p[@class="price"]//text()')
stock = parser.xpath('//p[contains(@class, "in-stock")]/text()')
description = parser.xpath('//div[contains(@class,"product-details__short-description")]//text()')
image_url = parser.xpath('//div[contains(@class, "woocommerce-product-gallery__image")]/a/@href')
product_data = {
'Title': clean_string(title), 'Price': clean_string(price), 'Stock': clean_stock(stock),
'Description': clean_string(description), 'Image_URL': clean_string(list_or_txt=image_url, connector=' | '),
'Product_URL': url}
return product_data
def save_data_to_csv(data, filename):
"""
Save a list of dicts to CSV.
:param data: Data to be saved to CSV
:param filename: Filename of csv
"""
keys = data[0].keys()
with open(filename, 'w', newline='') as csv_file:
writer = csv.DictWriter(csv_file, fieldnames=keys)
writer.writeheader()
writer.writerows(data)
def start_scraping():
"""
Starting function.
"""
listing_page_url = 'https://scrapeme.live/shop/'
product_urls = list()
for listing_page_number in range(1, 6):
response = send_request(listing_page_url)
listing_page_url = get_next_page_url(response)
products_from_current_page = get_product_urls(response)
product_urls.extend(products_from_current_page)
results = []
for url in product_urls:
results.append(get_product_data(url))
save_data_to_csv(data=results, filename='scrapeme_live_Python_data.csv')
print('Data saved as CSV)
if __name__ == "__main__":
start_scraping()Sending GET Requests Using Cookies
Sometimes, you might need to use cookies to avoid being blocked by the server. Define cookies in a dict and use it while making the request.
headers = {
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Sa"
"fari/537.36",
"Accept-Language": "en-US,en;q=0.5"
}
#define cookies
cookies = {'location': 'New York'}
url = "https://scrapeme.live/shop/"
response = requests.get(url, headers=headers, cookies=cookies)Sending POST Requests
Sometimes, you need to make a POST request to a specific URL to get the data. You can do that using the post() method.
#define payload as a dict
payload = {“key1”: “value1”, “key2”: “value2”}
headers = {
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Sa"
"fari/537.36",
"Accept-Language": "en-US,en;q=0.5"
}
url = "https://scrapeme.live/shop/"
response =requests.post(url, headers=headers, json=payload)Why Use a Web Scraping Service
While you can use the techniques shown in the tutorial to scrape websites with the Python requests library at a small scale, for larger projects, it’s better to use a web scraping service.
Otherwise, you have to take care of all the technicalities, including monitoring the website for changes and bypassing anti-scraping measures. Additionally, requests can’t handle dynamic websites, requiring you to use other libraries like Selenium.
If you use a web scraping service like ScrapeHero, you don’t need to worry about all this.
ScrapeHero is a fully-managed web scraping service. We can build enterprise-grade web scrapers, and crawlers customized to your data needs. Not only that! We can take care of your entire data pipeline, from extraction to building custom AI solutions.



