
XPath (XML Path Language) is a syntax for defining parts of an XML document. We will explain the relevance of Xpath in web scraping.
XPath is a query language for identifying and selecting nodes or elements in an XML document using a tree like representation of the document. XPath was defined by the World Wide Web Consortium (W3C).
XPaths are one of the few ways in which you can select some content from a big blob of XML or HTML (properly structured HTML is similarly structured as an XML document) content. An Xpath tells you the location of an element, just like a catalog card does for books.

For a web scraper, a web page is the “library” and the element you are looking for (say Best Books of The Month is what you are looking for) is the “Book” and the “Catalog card” is your Xpath.
In the web scraping world, Xpath is a selector – something that is used to “select” an element or a bunch of elements in an HTML or XML page for scraping.
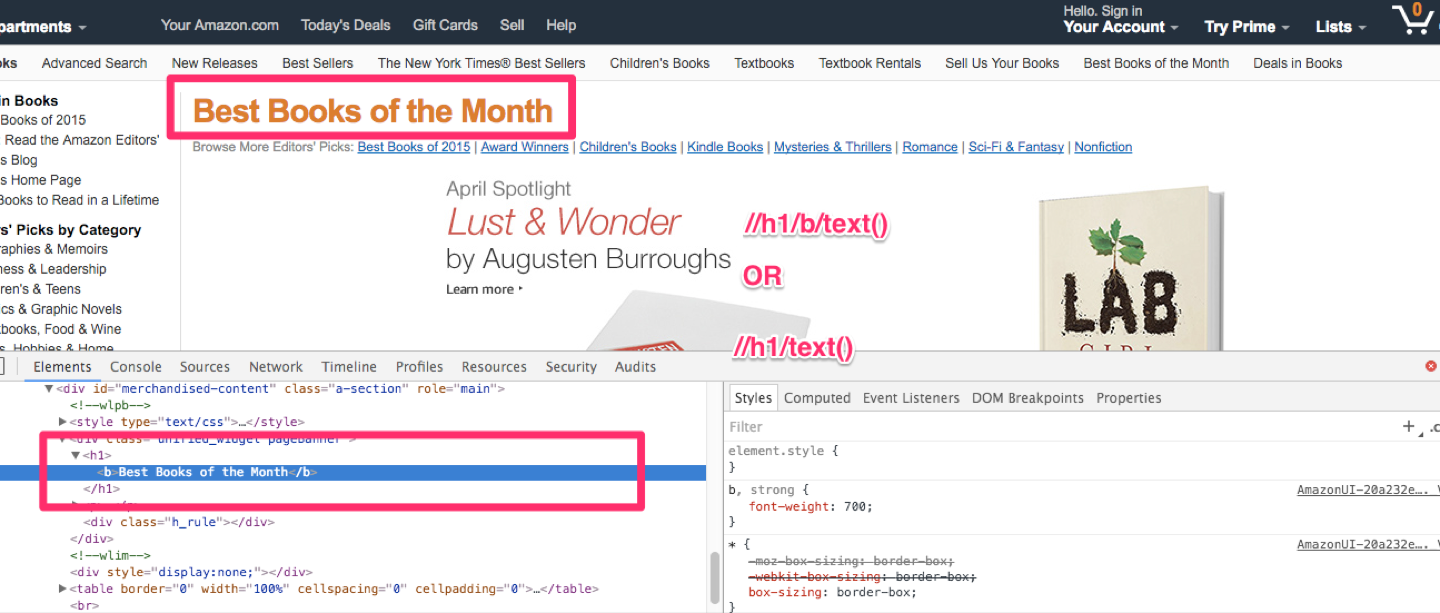
For example, in the image above, if we wanted to find out the heading of an Amazon best seller list. The xpath for the heading would be something like
//h1/text() OR //h1/b/text() Both of the above works. //h1/text() just says, go to the H1 tag where ever you can find it, get the text inside it. //h1/b/text() say, go to the H1 tag where ever you find it, go to the <b> tag in it and get the text inside it.
In both cases the text is – Best Book of the Month
Another simple example is //title/text() which give you the Title tag of an HTML Page
How can you select the XPath in Google Chrome
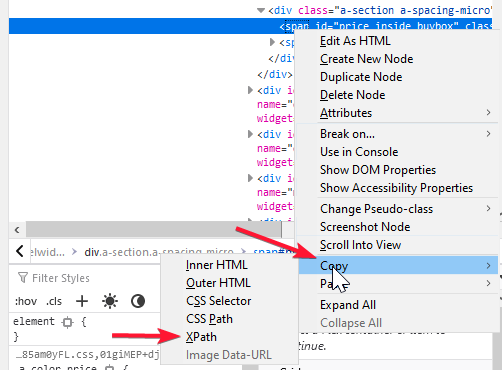
In Chrome, you can “Right click” on any page and click “Inspect” or Press Ctlr+Shift+I on the keyboard at the same time
Then you can check Copy -> Copy Xpath as shown below
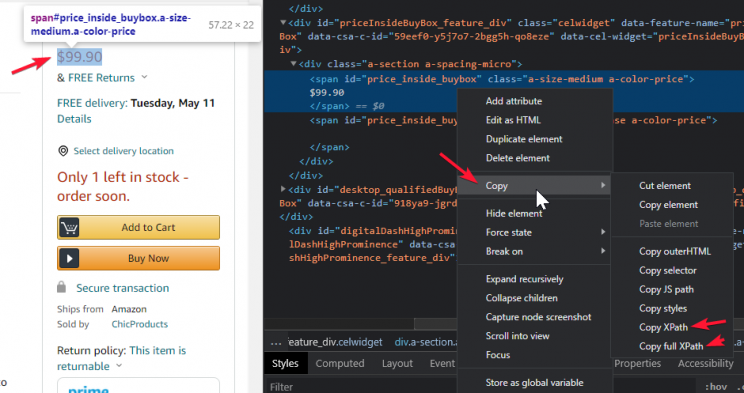
This copies the Xpath for Amazon’s Buy Box price for a product
How can you select the XPath in Firefox
The Firefox process is also similar to Chrome
Then Copy
XPath vs CSS Selectors
Another alternative selector used in Web scraping is called the “CSS Selector”, it is a selector similar to the XPath, but used by web developers or designers in the CSS styles of the web pages. Xpaths are far more powerful compared to CSS Selectors because you can put a lot of logic into a single Xpath statement to precisely identify the right element on a web page.
How can you select the CSS Selectors in Google Chrome or Firefox
The process is similar to the one described above – instead of copying the Xpath, you copy the CSS Selector.
Website Changes, XPaths and Scraper Maintenance
If you have worked with scrapers or web scraping services, you might already know about the “maintenance” for scrapers. You may already have heard developers complaining –
“The website changed their design and the Xpaths have changed”.
Xpaths in web scraping change when a website changes the way the HTML is structured. It is just like rearranging a library. Every time a library has rearranged the location of a book might change. So they have to update the change in location inside the catalog / card or else no one will be able to find the book.
Similarly, the web scraper code has to be updated every time a website changes its structure. It is also possible the structure of the website stay the same but the visual design changes. In that case the XPaths may not change and the scraper code may still work as before.
The scope of this article is limited to explaining what Xpaths are and why they are relevant in web scraping. We will be covering CSS Selectors and other scraping relevant terms in the future.
To learn more about XPaths please visit some of these pages:
- W3Schools Xpath Tutorial http://www.w3schools.com/xsl/xpath_intro.asp
- ZVON Xpath Tutorial http://zvon.org/xxl/XPathTutorial/General/examples.html
- W3Schools CSS Selector Reference http://www.w3schools.com/cssref/css_selectors.asp



