
Web scraping is the best method to gather data from websites. Scraping tools such as FMiner help users to scrape websites easily. FMiner is a visual web data extraction tool for web scraping and web screen scraping. We’ll show you how to extract a table from Wikipedia using FMiner. We are going to scrape data from Wikipedia. First, download the application at the link http://www.fminer.com/download/.
When you open the application, enter the URL and press the button ‘Record’ to record your actions. What we need to extract is the table of Olympic players from this link – https://en.wikipedia.org/wiki/List_of_National_Football_League_Olympians.
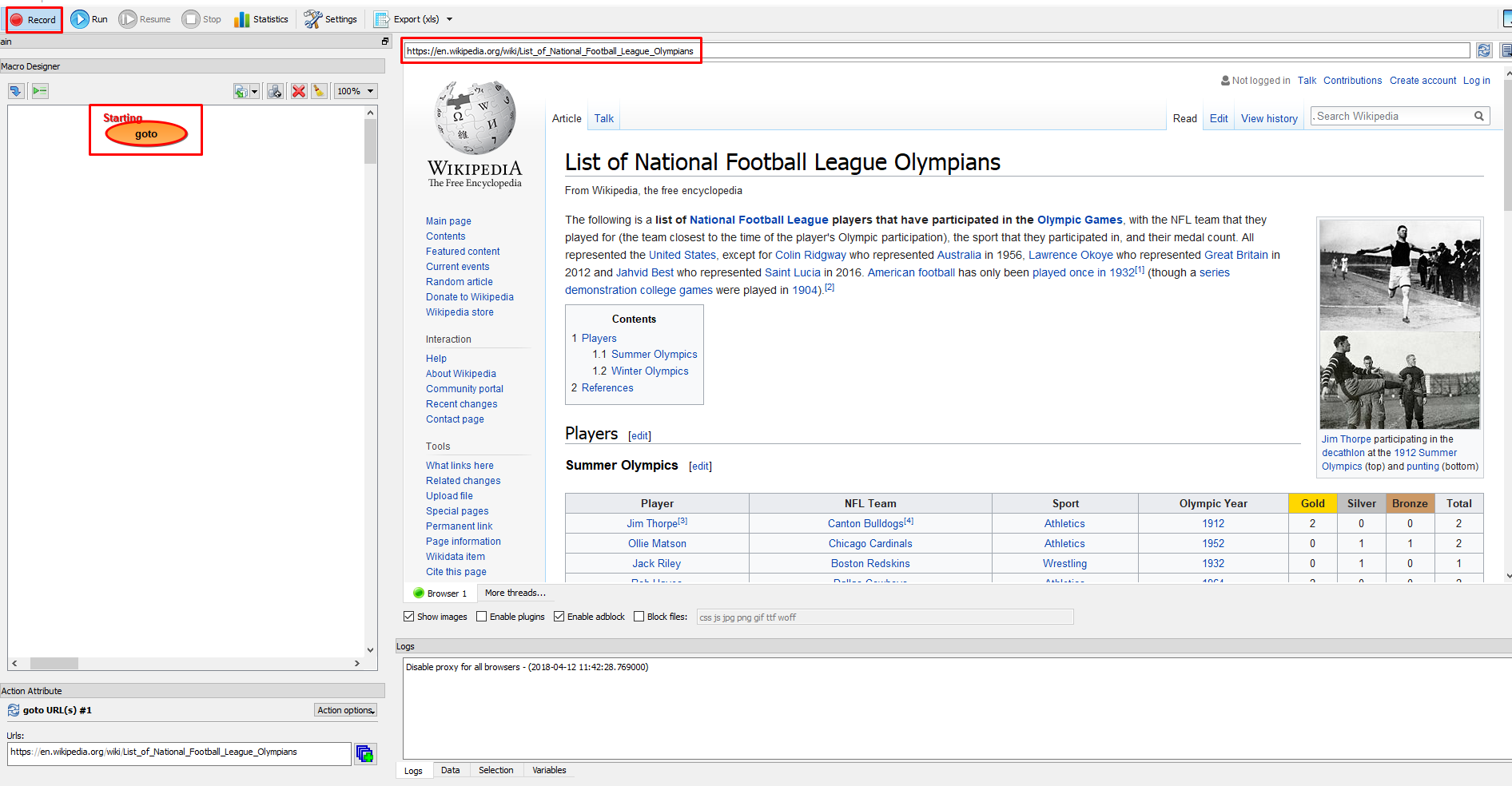
Creating a Table
To create the table, click on the ‘+’ sign that says table. Then select each row by clicking on the option ‘ Target Select’, you’ll see one whole row selected from the table. In order to expand the whole table, click on the option ‘Multiple Targets’ – this will select the whole table. Once the whole table is highlighted you can now enter your new fields by clicking on ‘+’ sign (shown in the image below).
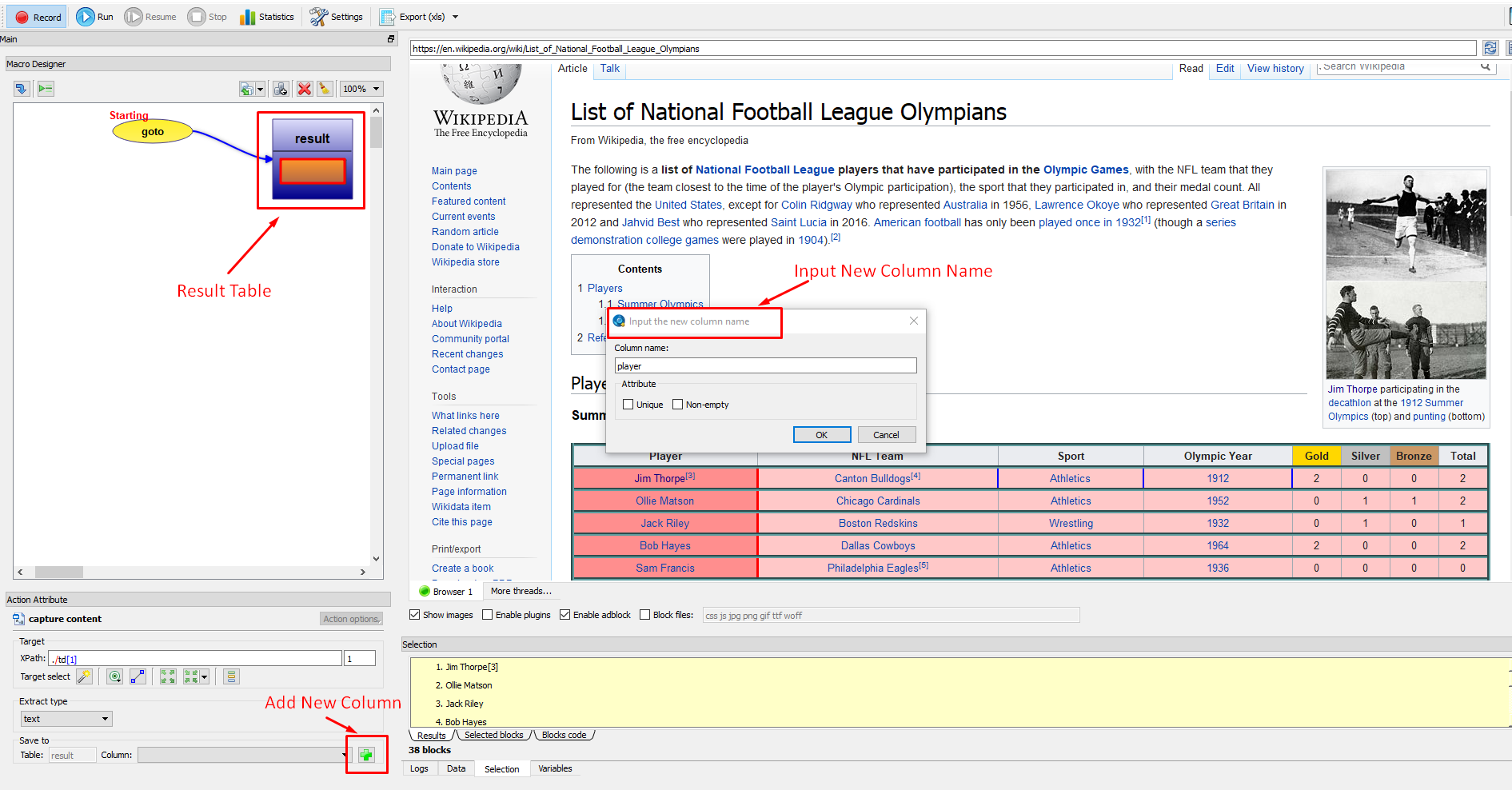
Extracting the Data
After you have created the table click on ‘Scrape’. You’ll receive a notification that the scrape has finished. Just click on ‘Export’ to save the data as a CSV or XLS file.
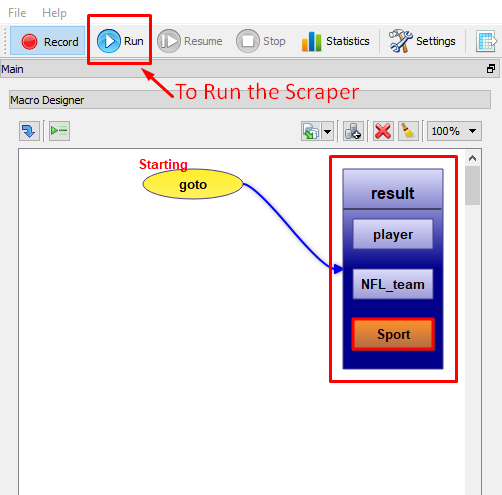
If the websites to scrape are complex or you need a lot of data from one or more sites, this tool may not scale well. You can consider using open source web scraping tools to build your own scraper, to crawl the web and extract data. To create a custom web scraper for a particular website you can check out our tutorial section: Web Scraping Tutorials
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



