
Web scraping is the easiest way to automate the process of extracting data from any website. Puppeteer scrapers can be used when a normal request module based scraper is unable to extract data from a website.
What is Puppeteer?
Puppeteer is a node.js library that provides a powerful but simple API that allows you to control Google’s Chrome or Chromium browser. It also allows you to run Chromium in headless mode (useful for running browsers in servers) and can send and receive requests without the need for a user interface. It works in the background, performing actions as instructed by the API. The developer community for puppeteer is very active and new updates are rolled out regularly. With its full-fledged API, it covers most actions that can be done with a Chrome browser. As of now, it is one of the best options to scrape JavaScript-heavy websites.
What can you do with Puppeteer?
Puppeteer can do almost everything Google Chrome or Chromium can do.
- Click elements such as buttons, links, and images.
- Type like a user in input boxes and automate form submissions
- Navigate pages, click on links, and follow them, go back and forward.
- Take a timeline trace to find out where the issues are in a website.
- Carry out automated testing for user interfaces and various front-end apps, directly in a browser.
- Take screenshots and convert web pages to pdf’s.
Update: (October 2022)
Building webscrapers using Playwright is faster and easier than Puppeteer. Here is a tutorial to help
Web Scraping using Puppeteer
In this tutorial, we’ll show you how to create a web scraper for Booking.com to scrape the details of hotel listings in a particular city from the first page of results. We will scrape the hotel name, rating, number of reviews, and price for each hotel listing.
Required Tools
To install Puppeteer you need to first install node.js and write the code to control the browser a.k.a scraper in JavaScript. Node.js runs the script and lets you control the Chrome browser using the puppeteer library. Puppeteer requires at least Node v7.6.0 or greater but for this tutorial, we will go with Node v9.0.0.
Installing Node.js
Linux
You can head over to Nodesource and choose the distribution you want. Here are the steps to install node.js in Ubuntu 16.04 :
1. Open a terminal run – sudo apt install curl in case it’s not installed.
2. Then run – curl -sL https://deb.nodesource.com/setup_8.x | sudo -E bash -
3. Once that’s done, install node.js by running, sudo apt install nodejs. This will automatically install npm.
Windows and Mac
To install node.js in Windows or Mac, download the package for your OS from Nodes JS’s website https://nodejs.org/en/download/
Obtaining the URL
Let’s start by obtaining the booking URL. Go to booking.com and search for a city with the inputs for check-in and check-out dates. Click the search button and copy the URL that has been generated. This will be your booking URL.
The gif below shows how to obtain the booking URL for hotels available in Singapore.
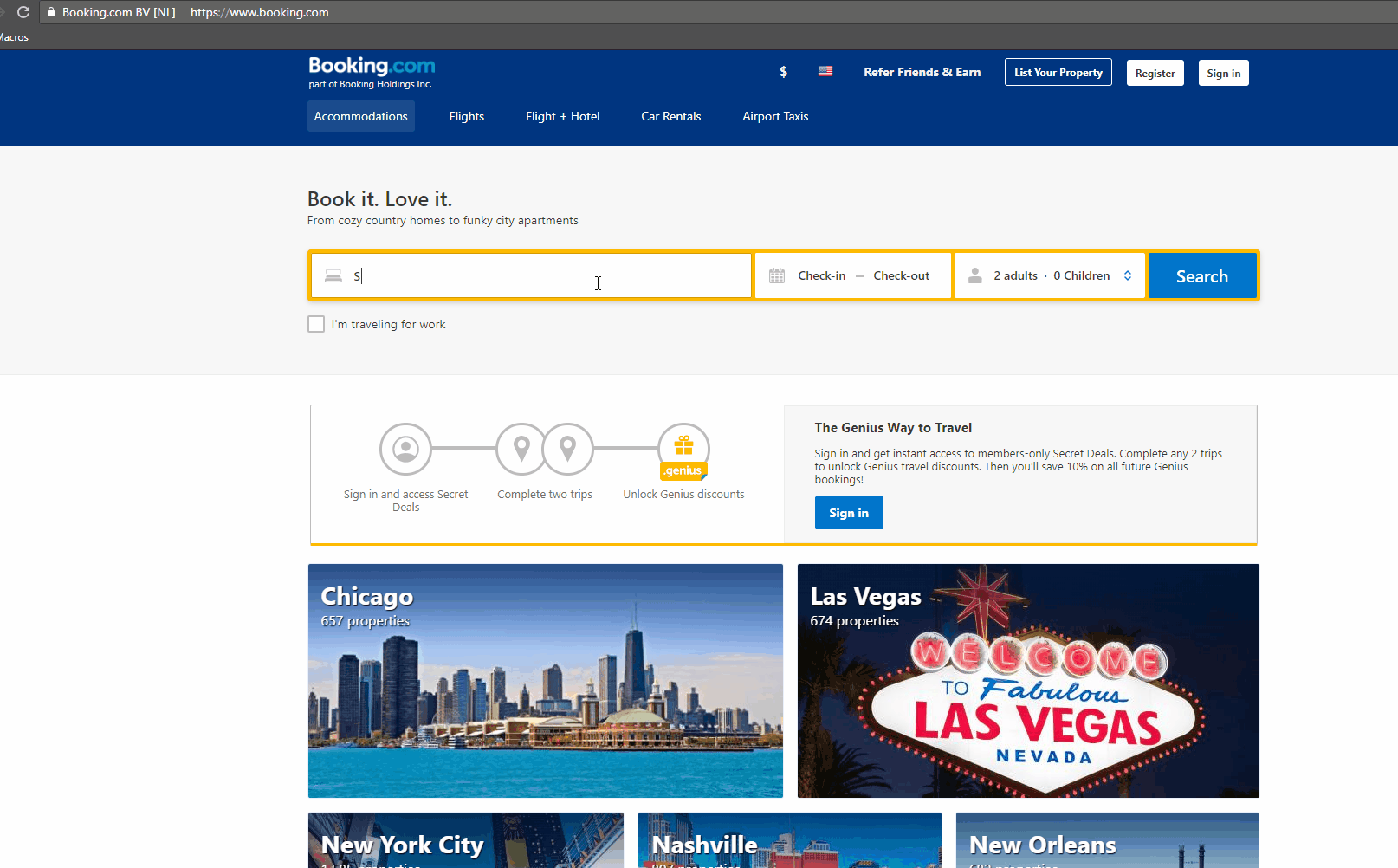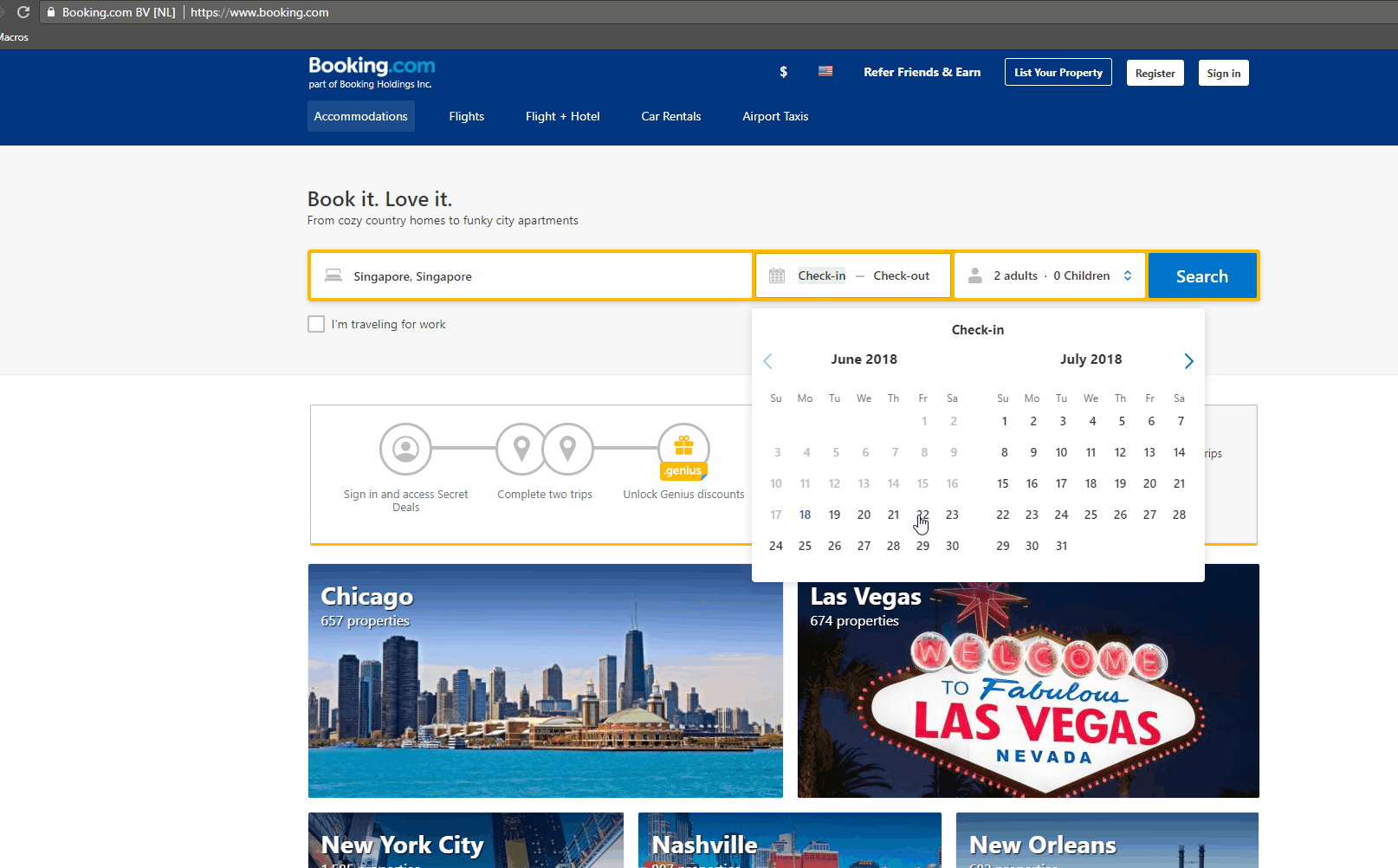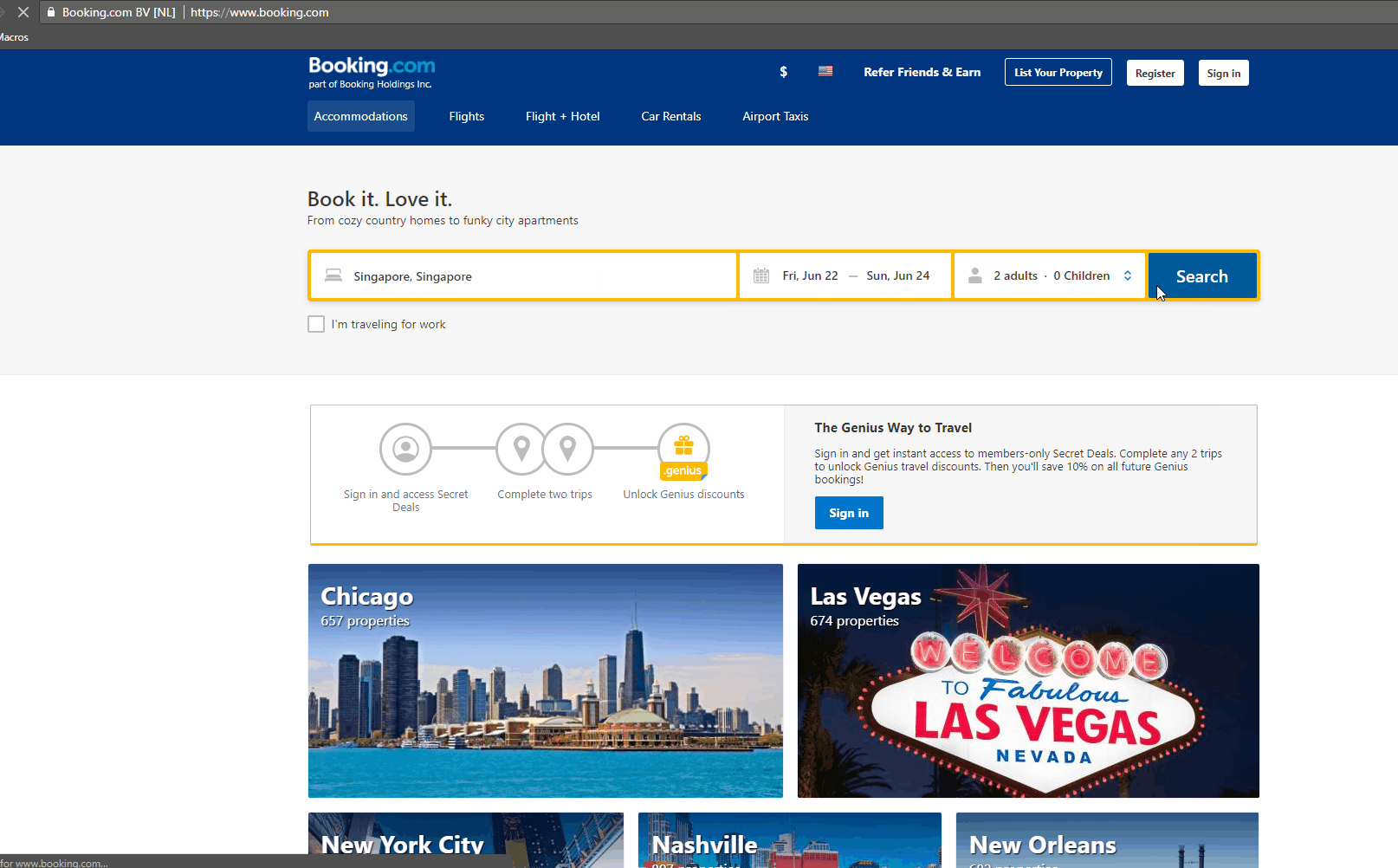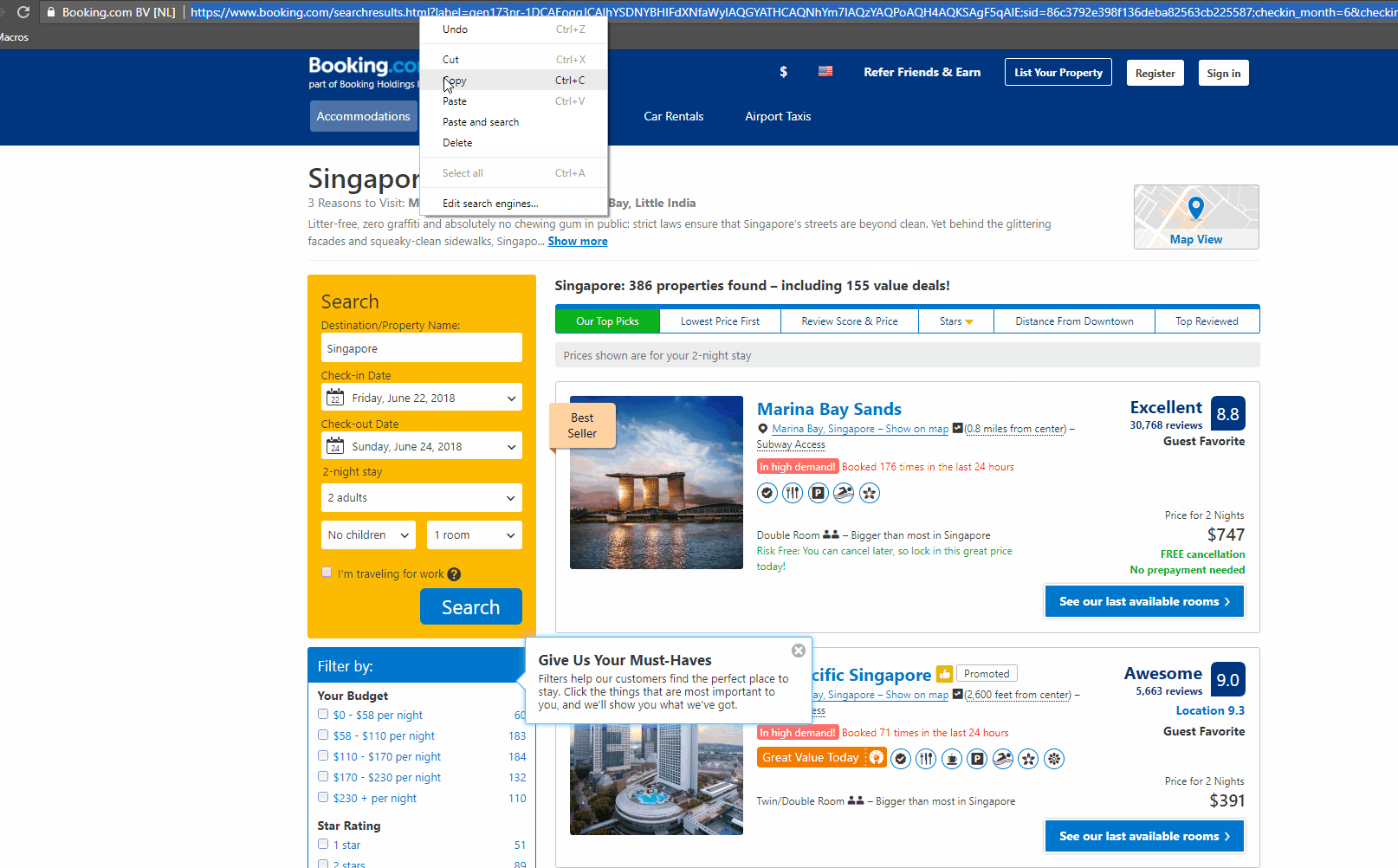
After you have completed the installation of node.js we will install the project requirements, which will also download the puppeteer library that will be used in the scraper. Download both the files app.js and package.json from below and place it inside a folder. We have named our folder booking_scraper.
The script below is the scraper. We have named it app.js. This script will scrape the results for a single listing page:
const puppeteer = require('puppeteer');
let bookingUrl = 'insert booking URL';
(async () => {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
await page.setViewport({ width: 1920, height: 926 });
await page.goto(bookingUrl);
// get hotel details
let hotelData = await page.evaluate(() => {
let hotels = [];
// get the hotel elements
let hotelsElms = document.querySelectorAll('div.sr_property_block[data-hotelid]');
// get the hotel data
hotelsElms.forEach((hotelelement) => {
let hotelJson = {};
try {
hotelJson.name = hotelelement.querySelector('span.sr-hotel__name').innerText;
hotelJson.reviews = hotelelement.querySelector('span.review-score-widget__subtext').innerText;
hotelJson.rating = hotelelement.querySelector('span.review-score-badge').innerText;
if(hotelelement.querySelector('strong.price')){
hotelJson.price = hotelelement.querySelector('strong.price').innerText;
}
}
catch (exception){
}
hotels.push(hotelJson);
});
return hotels;
});
console.dir(hotelData);
})();
The script below is package.json which contains the libraries needed to run the scraper
{
"name": "booking-scraper",
"version": "0.0.1",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC",
"dependencies": {
"puppeteer": "^1.3.0"
}
}
Installing the project dependencies, which will also install Puppeteer.
- Install the project directory and make sure it has the
package.jsonfile inside it. - Use
npm installto install the dependencies. This will also install puppeteer and download the Chromium browser to run the puppeteer code. By default, puppeteer works with the Chromium browser but you can also use Chrome.
Now copy the URL that was generated from booking.com and paste it in the bookingUrl variable in the provided space (line 3 in app.js). You should make sure the URL is inserted within quotes otherwise, the script will not work.
let bookingUrl= 'insert url here'
Running the Puppeteer Scraper
To run a node.js program you need to type:
node filename.js
For this script, it will be:
node app.js
Turning off Headless Mode
The script above runs the browser in headless mode. To turn the headless mode off, just modify this line
const browser = await puppeteer.launch({ headless: true }); to const browser = await puppeteer.launch({ headless: false});
You should then be able to see what is going on.
The program will run and fetch all the hotel details and display it in the terminal. If you want to scrape another page you can change the URL in the bookingUrl variable and run the program again.
Here is how the output for hotels in Singapore will look like:
[ { name: 'Marina Bay Sands',
reviews: '30,768 reviews',
rating: '8.8',
price: 'US$747' },
{ name: 'Pan Pacific Singapore',
reviews: '5,663 reviews',
rating: '9.0',
price: 'US$391' },
{ name: 'Shangri-La Apartments',
reviews: '579 reviews',
rating: '8.2' },
{ name: 'PARKROYAL on Beach Road',
reviews: '4,045 reviews',
rating: '8.4',
price: 'US$240' },
{ name: 'Rendezvous Hotel Singapore by Far East Hospitality',
reviews: '2,356 reviews',
rating: '8.6',
price: 'US$261' },
{ name: 'Royal Plaza on Scotts',
reviews: '5,280 reviews',
rating: '8.5',
price: 'US$299' },
{ name: 'Swissotel Merchant Court Singapore',
reviews: '5,058 reviews',
rating: '8.8',
price: 'US$278' },
{ name: 'Mercure Singapore Bugis',
reviews: '2,015 reviews',
rating: '8.0',
price: 'US$249' },
{ name: 'Swissotel The Stamford',
reviews: '3,650 reviews',
rating: '8.6',
price: 'US$422' },
{ name: 'Orchard Grand Court',
reviews: '781 reviews',
rating: '8.5' },
{ name: 'Ascott Orchard Singapore',
reviews: '648 reviews',
rating: '8.6',
price: 'US$414' },
{ name: 'Holiday Inn Singapore Orchard City Centre',
reviews: '3,107 reviews',
rating: '8.6',
price: 'US$323' },
{ name: 'Carlton Hotel Singapore',
reviews: '6,810 reviews',
rating: '8.8',
price: 'US$274' },
{ name: 'Holiday Inn Express Singapore Orchard Road',
reviews: '2,025 reviews',
rating: '8.4',
price: 'US$319' },
{ name: 'Holiday Inn Express Singapore Katong',
reviews: '2,495 reviews',
rating: '8.3',
price: 'US$230' },
{ name: 'Parkroyal on Pickering',
reviews: '4,531 reviews',
rating: '9.1',
price: 'US$415' },
{ name: 'Holiday Inn Express Singapore Clarke Quay',
reviews: '5,026 reviews',
rating: '8.6',
price: 'US$237' } ]
Debug Using Screenshots
In case you are stuck, you could always try taking a screenshot of the webpage and see if you are being blocked or if the structure of the website has changed. Here is something to get started
Speed Up Puppeteer Web Scraping
Loading a web page with images could slow down web scraping due to reduced page speed. To speed up browsing and data scraping, disabling CSS and images could help with that while also reducing bandwidth consumption.
Known Limitations
When using Puppeteer you should keep some things in mind. Since Puppeteer opens up a browser it takes a lot of memory and CPU to run in comparison to script-based approaches like Selenium for JavaScript.
If you want to scrape a simple website that does not use JavaScript-heavy frontends, use a simple Python Scraper. There are plenty of open source javascript web scraping tools you can try such as Apidfy SDK, Nodecrawler, Playwright, and more.
You will find Puppeteer to be a bit slow as it only opens one page at a time and starts scraping a page once it has been fully loaded. Pupetteer scripts can only be written in JavaScript and do not support any other language.
If you need professional help with scraping complex websites, contact us by filling up the form below.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data
Disclaimer: Any code provided in our tutorials is for illustration and learning purposes only. We are not responsible for how it is used and assume no liability for any detrimental usage of the source code. The mere presence of this code on our site does not imply that we encourage scraping or scrape the websites referenced in the code and accompanying tutorial. The tutorials only help illustrate the technique of programming web scrapers for popular internet websites. We are not obligated to provide any support for the code, however, if you add your questions in the comments section, we may periodically address them.


