

Google Maps holds business data, but extracting it at scale requires the right approach
There are two primary methods for Google Maps scraping:
- Code-based: Build a web scraper in Python or JavaScript using Playwright
- No-code: Use the ScrapeHero Cloud Google Maps Search Results Scraper
If you don’t want to write or maintain code, ScrapeHero Cloud is exactly what you need—download data in just a few clicks.

Scrape Google Maps: Code-Based Approach
This section discusses how to extract data from Google Maps using Python. The code uses browser automation framework Playwright to emulate browser behavior.
Advantages of this method include bypassing anti-scraping measures. However, you need to be familiar with Playwright API to use it effectively.
Install Necessary Libraries
Install the Playwright library.
pip install playwright
Install the Playwright browser.
playwright install
Write Your Scraping Code
First, import the necessary modules. Use asyncio for asynchronous programming, json to handle the final export, and async_playwright from the Playwright library to automate the browser interactions.
import asyncio
import json
from playwright.async_api import Playwright, async_playwright
from playwright.async_api import TimeoutError as PlaywrightTimeoutErrorSet up the extraction function extract_details(page) to pull the required information from the Google Maps results list.
async def extract_details(page):
Inside the function, define CSS selectors for the result container, title, rating, review count, and address.
result_container_selector = 'div[role="article"]'
title_selector = '.qBF1Pd'
rating_selector = '.MW4etd'
review_count_selector = '.ZkP5Je'
address_selector = '.W4Efsd'Initialize an empty list results_parsed to store the scraped dictionaries.
results_parsed = []
Use page.locator() with your result container selector to get a list of all loaded map results.
results = page.locator(result_container_selector)
Loop through the results using the total count.
for result_idx in range(await results.count()):
Within the loop:
- Use .inner_text() to extract the title and rating.
- For the review count, use .get_attribute(‘aria-label’) and extract the third word to isolate the numeric value.
- Extract the address by getting all inner texts from the address block.
- Take the second item, split it by the interpunct (·), isolate the third segment, split that by the newline character, and take the first line.
- Strip away any trailing whitespace.
try:
result_elem = results.nth(result_idx)
except Exception:
result_elem = None
try:
title = await result_elem.locator(title_selector).inner_text()
except Exception:
title = None
try:
rating = await result_elem.locator(rating_selector).inner_text()
except Exception:
rating = None
try:
review_count = await result_elem.locator(review_count_selector).get_attribute('aria-label')
review_count = review_count.split()[2] if review_count else None
except Exception:
review_count = None
try:
address = await result_elem.locator(address_selector).all_inner_texts()
address = address[1].split('·')[2].split('\n')[0].strip()
except Exception as e:
print(e)
address = None
This code wraps each extraction step (title, rating, review count, address) in a try-except block to prevent errors from crashing the script if a particular element is missing.
Next, check if the word “Opens” is in the address string. If it isn’t, build a dictionary containing the title, review count, rating, and address, then append it to your results_parsed list.
Note: This check ensures that listings without an address are not included.
if 'Opens' not in address:
data = {
'title': title,
'review_count': review_count,
'rating': rating,
'address': address,
# 'phone': phone
}
results_parsed.append(data)
Return the final list of parsed dictionaries.
return results_parsed
Next, create the core run(playwright) function.
async def run(playwright: Playwright) -> None:
Launch a Chromium browser instance. Set headless=False so you can watch the automation happen in real time.
browser = await playwright.chromium.launch(
headless=False,
)
Create a new browser context and set a default timeout of 5000 milliseconds to handle slow-loading elements.
context = await browser.new_context()
context.set_default_timeout(5000)
Define your search_term, such as “dentist in New York City, NY, USA”.
search_term = "dentist in New York City, NY, USA"
Open a new page and navigate to “https://www.google.com/maps/”. Locate the search input field by its name attribute (q) and fill it with your search term. Press the Enter key to submit the search.
page = await context.new_page()
await page.goto("https://www.google.com/maps/")
await page.locator('input[name="q"]').fill(search_term)
await page.keyboard.press('Enter')
Wait for the search results container to appear on the page, then pause for exactly 3 seconds to let everything settle.
await page.wait_for_selector('div[role="article"]')
await page.wait_for_timeout(3000)Hover your mouse over the very first result. This ensures a focused scroll targets the results pane rather than the main map view.
await page.locator('div[role="article"]').first.hover()
Create a loop to scroll down the results pane. Scroll the mouse wheel by 3000 pixels vertically, then wait 3000 milliseconds to let more results load. Repeat this action 3 times.
for _ in range(3):
await page.mouse.wheel(delta_x=0, delta_y=3000)
await page.wait_for_timeout(3000)
Call your extract_details(page) function and assign the returned data to results.
results = await extract_details(page)
Open a file named restaurant_data.json in write mode. Use json.dump() to save your parsed results, and include an indent of 2 for readability.
with open('restaurant_data.json', 'w') as f:
json.dump(results, f, indent=2)
Close the browser context and the browser itself.
await context.close()
await browser.close()
Finally, define the main() entrypoint. Wrap the run() execution inside an async_playwright() context manager, and then trigger the entire script using asyncio.run().
async def main() -> None:
async with async_playwright() as playwright:
await run(playwright)
asyncio.run(main())
How the Code Works
The scripts above have two core functions:
- run function: Launches a Chromium browser instance, navigates to Google Maps, fills in a search term, clicks the search button, and waits for results. It then calls extract_details and saves results to a JSON file.
- extract_details function: Takes a Playwright page object as input and returns a list of dictionaries containing the title, review count, rating, address, and phone number for each result.
Code Limitations
Although the code can work for scraping at a small scale, there are a couple of limitations:
Fragility of CSS Selectors
The script relies on hardcoded class names like .qBF1Pd, .MW4etd, and .ZkP5Je. Google frequently changes these obfuscated class names, meaning the scraper can break without warning and require constant maintenance.
No Rate Limiting or Stealth
The script makes no attempt to randomize delays, rotate user agents, or mimic human-like behavior beyond the basic hover. Google’s bot detection can still flag and block the session, especially if you attempt large-scale web scraping.
Using No-Code Google Maps Scraper by ScrapeHero Cloud
The Google Maps scraper by ScrapeHero Cloud is a convenient solution for scraping Google Maps search results. It provides an easy, no-code method for Google maps scraping, making it accessible for individuals with limited technical skills.
Steps to Use the ScrapeHero Google Maps Scraper
- Sign up or log in to your ScrapeHero Cloud account.
- Go to the ScrapeHero Google Maps Search Results Scraper.
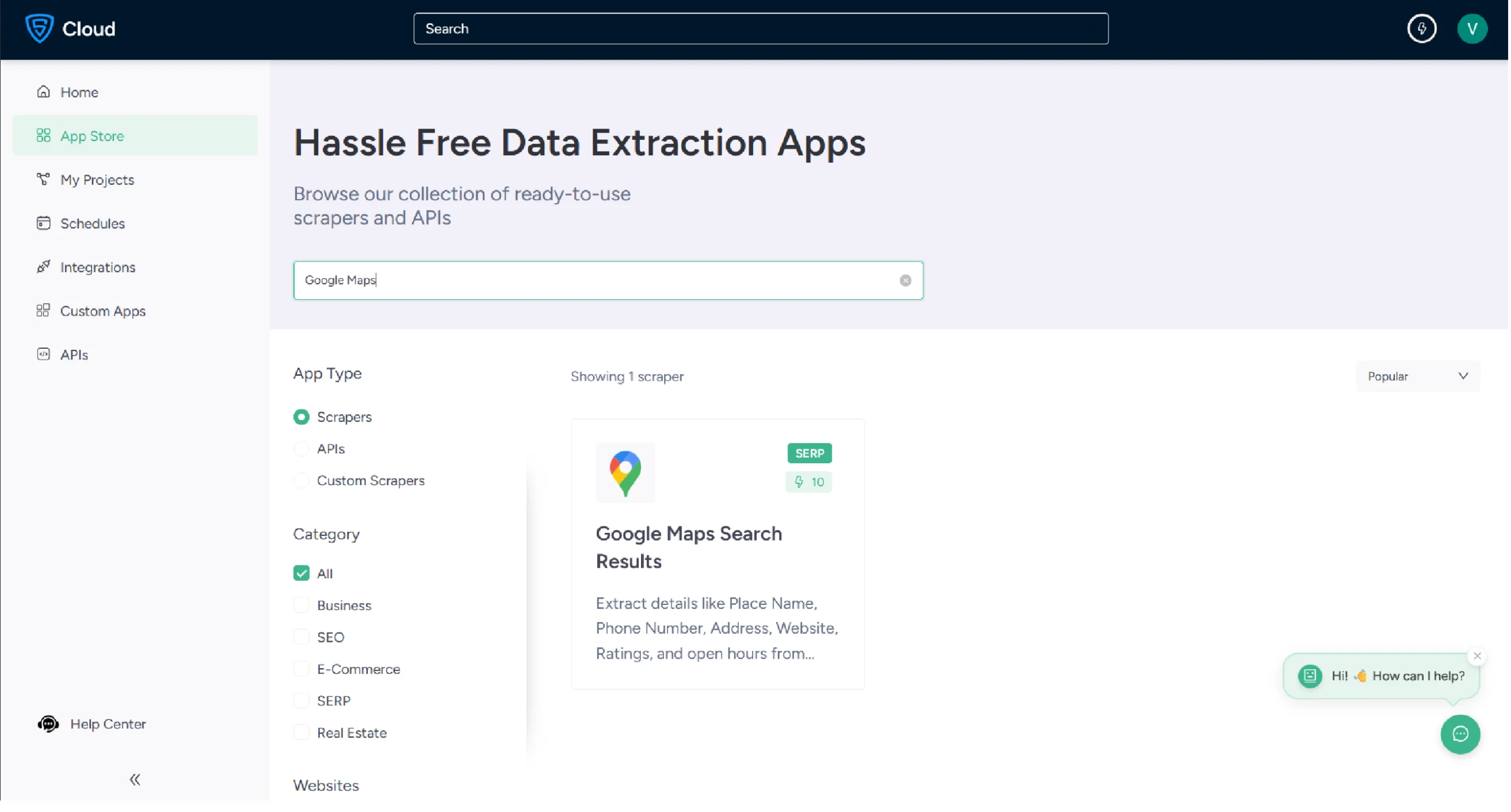
3. Click the Create New Project button.
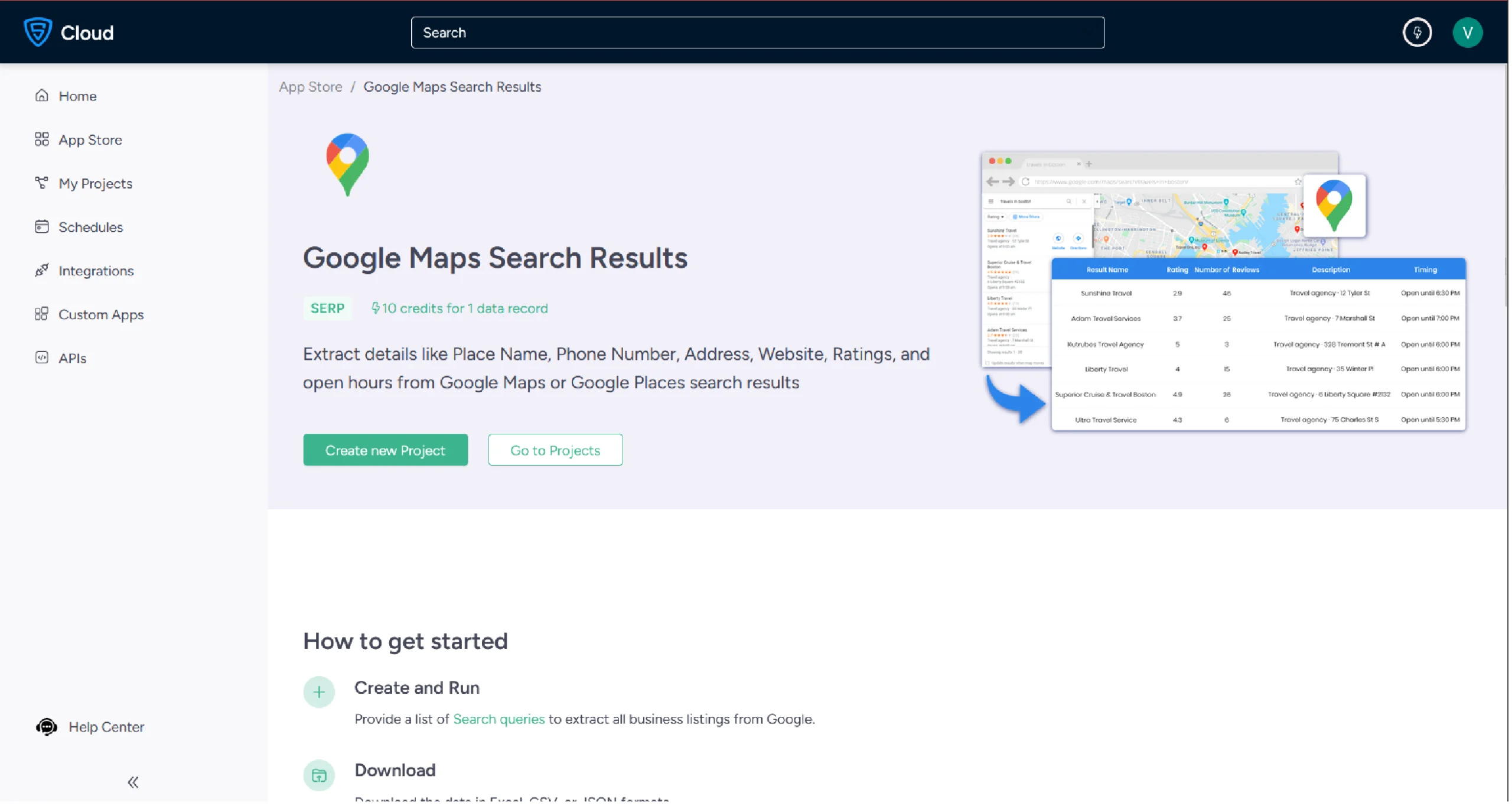
4. The scraper allows you to search with a query — for example, “McDonalds in Seattle.” You can verify your query directly in Google Maps first.
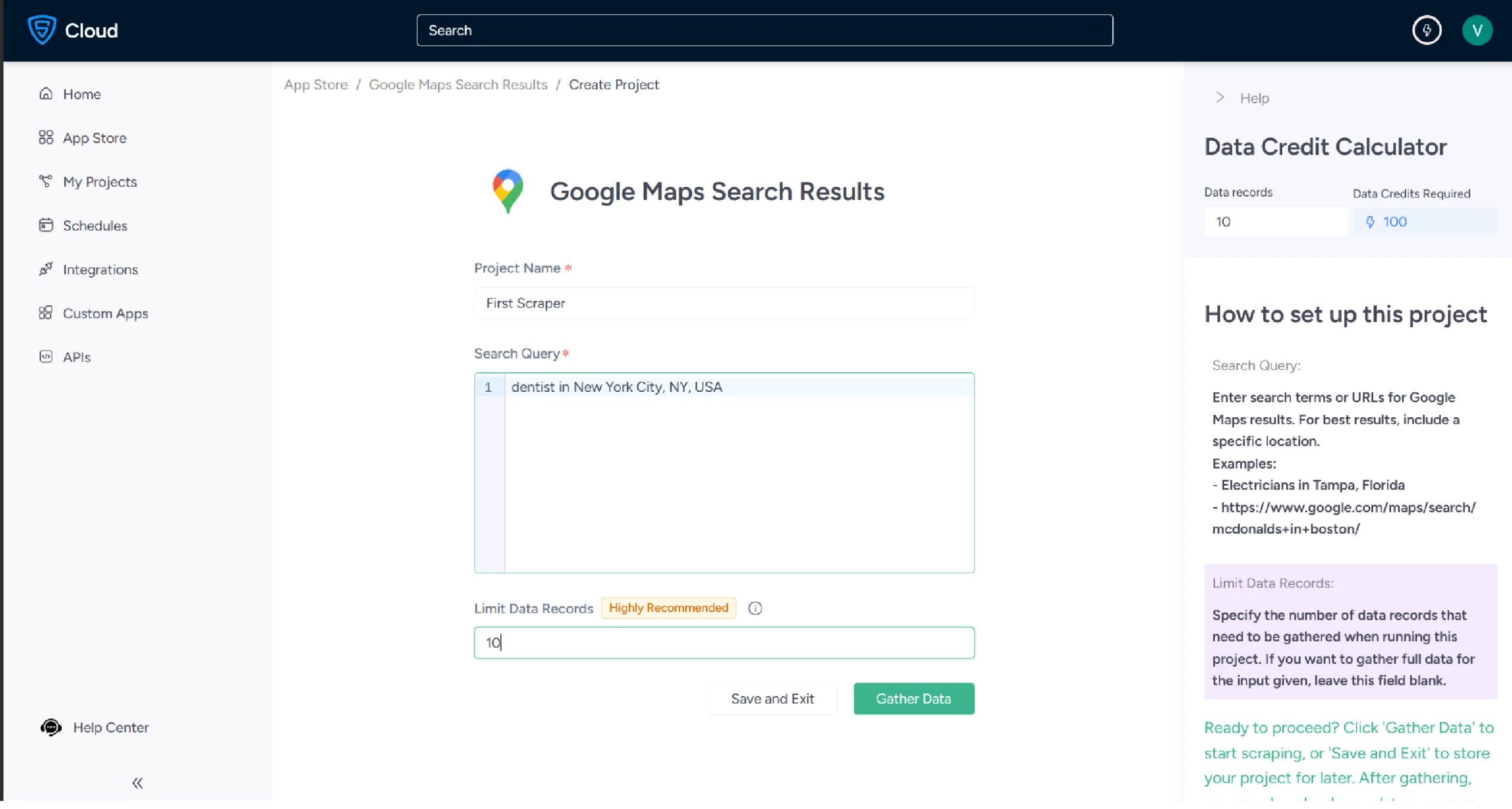
5. Enter a project name, search query, and the maximum number of records you want to gather. Click Gather Data to start the scraper.
6. Track the scraper’s progress under the Projects tab.
7. Once finished, click the project name and navigate to the Overview tab to view and download your data.
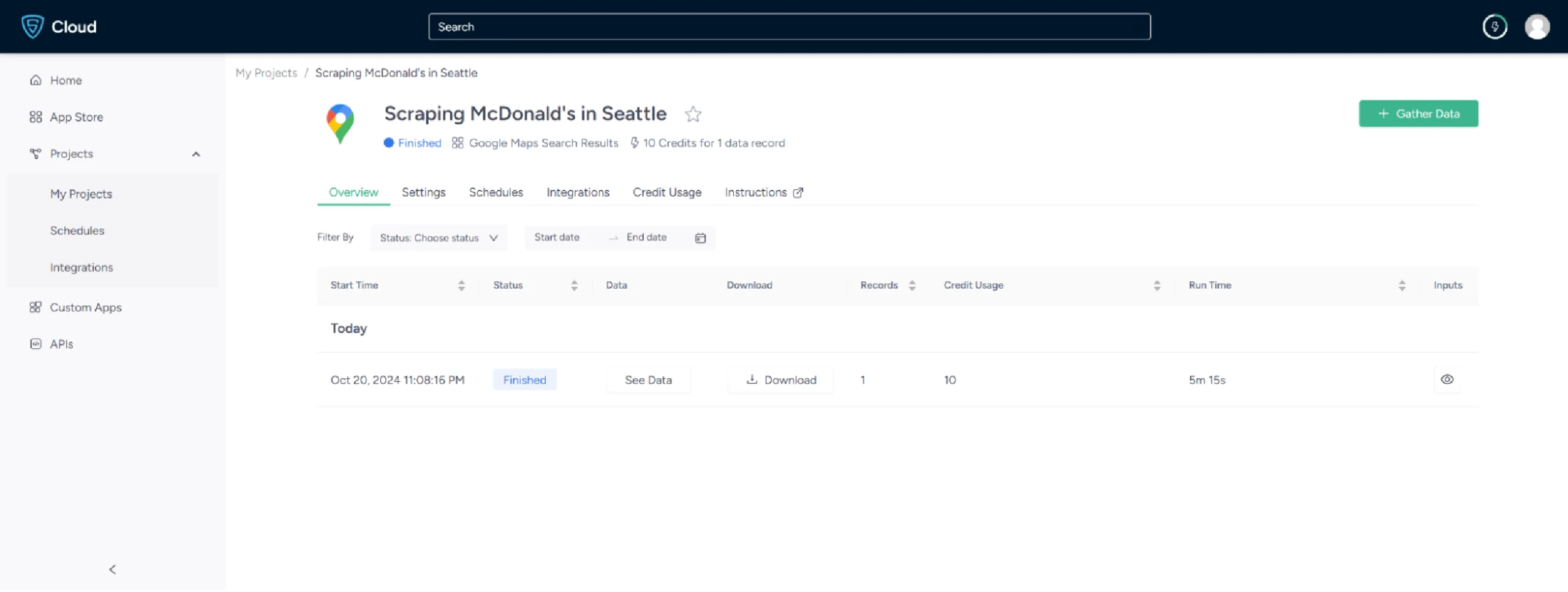
8. To pull Google Maps data into a spreadsheet, click Download Data, select Excel, and open the downloaded file in Microsoft Excel.
Use Cases of Google Maps Data
If you’re unsure why you should scrape Google Maps, here are some of the most valuable use cases for location data:
Location-Based Marketing
Knowing where your potential customers are concentrated helps focus advertising spend. Location data from Maps can inform decisions about where to run campaigns, where to open new locations, or which areas are underserved.
Lead Generation
Google Maps is a practical source for B2B prospecting. Business names, addresses, phone numbers, and categories can be compiled into targeted lead lists. This is particularly useful for reaching local businesses in a specific industry or region.
Brand Sentiment Analysis
Aggregating reviews across multiple locations over time reveals how customers perceive a brand at scale. It is something that’s difficult to gauge from individual listings. Shifts in average ratings or recurring complaints can surface issues before they become larger problems.
Competitor Analysis
Mapping competitor locations alongside their ratings and review activity gives you a clearer picture of how they’re positioned. You can track patterns such as which areas they’re expanding into, how customers respond to new locations, and where gaps in the market exist.
Google Maps Data Scraping Trends in 2026
Over the past year, scraping Google Maps has become noticeably more challenging due to a combination of platform-side changes and advances in the scraping ecosystem.
Google’s Evolving Anti-Bot Measures
In late 2024, Google rolled out more aggressive TLS fingerprinting checks on Maps endpoints, making standard requests-based scrapers increasingly unreliable.
Headless Playwright sessions are now more commonly flagged if they don’t replicate realistic scroll behavior and interaction timing. Adding randomized delays between scroll events (typically 800ms–2000ms) and simulating mouse movements may improve longevity.
Playwright + Stealth Mode
The playwright-stealth plugin (JavaScript) and its Python equivalent playwright-stealth have become near-essential for Maps scraping in 2025.
These patches mask common browser automation fingerprints (navigator.webdriver, missing Chrome plugins, inconsistent screen resolution) that Google’s bot detection now specifically targets.
Residential Proxies Are More Critical Than Ever
Datacenter proxies now get blocked almost immediately on Maps. Rotating residential proxies with geo-targeting (matching the locale you’re searching) have become the reliable baseline for any production-level scraping workflow.
Feeding Maps Data Into AI Pipelines
One emerging use case worth highlighting: teams are now piping scraped Maps data directly into RAG (Retrieval-Augmented Generation) pipelines.
For example, business names, reviews, and addresses extracted from Maps can be chunked, embedded with a model like text-embedding-3-small, and stored in a vector database (Pinecone, Weaviate) to power local business intelligence chatbots. This is a natural downstream extension of the CSV/JSON export workflows described in this article.
Wrapping Up
Scraping Google Maps comes down to a simple trade-off: code gives you flexibility and control, but requires ongoing maintenance; no-code tools are faster to set up but less customizable.
For small-scale or one-off projects, the Playwright approach works well. For anything larger or more frequent, a managed solution saves considerable time.
If you’d rather skip the setup entirely, ScrapeHero Cloud’s Google Maps scraper gets you the same data in just a few clicks. And if your requirements go beyond what the scraper offers, ScrapeHero’s full scraping service can handle it.
ScrapeHero is a leading web scraping service in the world. Our self-healing web scraping architecture can tackle any website. Contact ScrapeHero now so that your dev teams can focus more on your core business operations.
Frequently Asked Questions
The Google Maps API is costly and can be challenging to configure for large-scale data collection. ScrapeHero Cloud offers a more affordable, ready-to-use alternative with no setup required.
ScrapeHero provides comprehensive pricing plans for both scrapers and APIs. Visit the ScrapeHero pricing page for current details.
The best tool depends on your technical skills and scale. For developers, Playwright-based scrapers with residential proxies offer the most flexibility. For non-technical users, the ScrapeHero Cloud Google Maps Scraper or the ScrapeHero Google Reviews Scraper are reliable, maintained options.


