
This article continues ”Scrape a Website Using Python: A Beginners Guide.” There, you familiarize yourselves with the web scraping process, libraries used, and anti-scraping measures. Here, you will apply that knowledge for web scraping Reddit post titles and URLs for free.
The tutorial teaches you how to scrape Reddit by building a very basic web scraper using Python and BeautifulSoup. It scrapes the top links from old.reddit.com. However, you can also scrape a subreddit using BeautifulSoup by tweaking the code in this tutorial.
Steps for Web Scraping Reddit Post Titles and URLs
Here are the steps for scraping Reddit post titles using Python:
- Send an HTTP request to https://old.reddit.com/top/ and download the HTML content of the page. This scraper does not need a web crawling component, as you will only extract data from a single link. You will be web scraping using Urllib (Python’s built-in URL handling library).
- Parse the downloaded data using an HTML parser and extract data. For parsing the HTML, you will use BeautifulSoup 4, a library that can extract data from HTML and XML files. It works with external HTML parsers to provide intuitive ways for navigating, searching, and modifying the parse tree.
You can use your preferred parser with BeautifulSoup. In this tutorial, you will be web scraping using BeautifulSoup4 with html.parser, which is an inbuilt Python parser. - Save the extracted data to a JSON file. You will use Python’s built-in JSON module to serialize the data into JSON and write it into a file.
This tutorial uses Reddit (old.reddit.com) to illustrate web scraping.
Setup the Environment
The tutorial uses Python 3 to show how to scrape Reddit, and the code will not run on lesser versions of Python. Therefore, you need a computer with Python 3 and pip for scraping post titles and URLs from Reddit.
Most UNIX operating systems, like Linux and Mac OS, come with Python pre-installed, but not all. It is better to check your Python version before you try to run the code.
You can check the Python version on a terminal ( in Linux and Mac OS ) or Command Prompt ( on Windows ) by entering
python --versionIf the output looks something like Python 3.x.x, you have Python 3, and you are ready to move on to the next step in this tutorial. Otherwise, you can install it by downloading the package from their official website.
Install Packages
You can check for the required Python packages for web scraping once you ensure you have Python and pip on your system.
JSON and Urllib come in-built with Python, so you don’t need to install them. You only have to install BeautifulSoup since you will be web scraping Reddit using BeautifulSoup.
In Linux and Mac OS, open a terminal and run
sudo pip install beautifulsoup4 In Windows, open Command Prompt or PowerShell and run
pip install beautifulsoup4Data Extracted From Reddit
- Title of the link
- The URL where it points to
Finding the Data
Before you start building the scraper, you must find where the data is in the web page’s HTML code. To do that, you can use your browser’s developer options to inspect the web page. You need to
- Find the tag that encloses the list of links
- Get links from it and extract data
Inspect the HTML
To use the developer options of your browser:
- Open a browser ( you will use Chrome here )
- go to https://old.reddit.com/top/
- Right-click anywhere on the page and choose Inspect Element
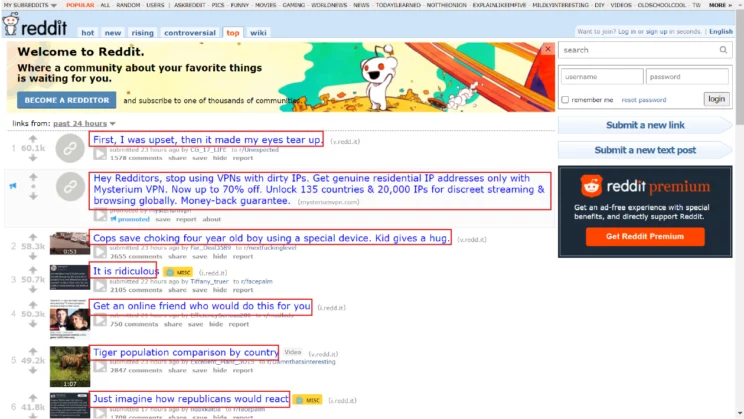
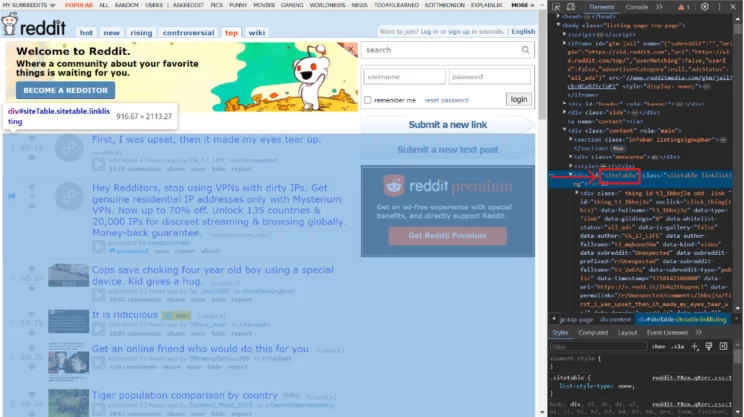
The browser will open a toolbar with the HTML code of the web page. If you look closely, there is a div tag, with its attribute called ‘id’ as ‘siteTable.’ This div encloses the data you need to extract.
Now find the HTML tag(s) with the links you need to extract. You can right-click on the link title in the browser. It will open a right pane as before with the HTML code of the element you clicked.
The data inside a link is present in anchor tags. If you inspect the other links, you will see they are also in a similar anchor tag. BeautifulSoup has a function that finds all tags with specific attributes. In this case, you are looking for all tags inside the div called siteTable with the class title.
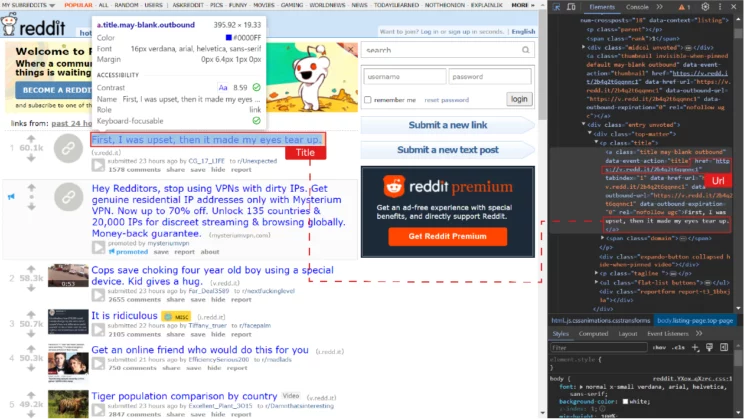
Now that you know where the data is in the HTML code, you can extract it.
Web Scraping Reddit Post Titles and URLs: The Code
Every code’s first section has import statements that allow you to use the libraries and modules.
Import Urllib, BeautifulSoup, and JSON in this Python code for Reddit web scraping.
import urllib.request
from bs4 import BeautifulSoup
import json
Now, send an HTTP request and parse the response containing the HTML data.
The request will also have headers telling reddit.com that the HTTP request is from a legitimate user.
url = "https://old.reddit.com/top/"
headers = {'user-agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.3'}
request = urllib.request.Request(url,headers=headers)
html = urllib.request.urlopen(request).read()
The HTML of the URL is in the variable html. Let’s pass the HTML content to BeautifulSoup and construct a tree for us to parse.
Next, isolate the div element siteTable into a variable main_table because you only need links within siteTable. You can now isolate all the links inside the siteTable with the class title.
soup = BeautifulSoup(html,'html.parser')
main_table = soup.find("div",attrs={'id':'siteTable'})
links = main_table.find_all("a",class_="title")
Afterward, iterate through each link and extract the text and the URL.
extracted_records = []
for link in links:
title = link.text
url = link['href']
if not url.startswith('http'):
url = "https://reddit.com"+url
record = {
'title':title,
'url':url
}
extracted_records.append(record)You must have noticed the if block with startswith() method; this snippet ensures that all the URLs are absolute. Otherwise, some URL entries will be relative; they won’t start with ‘https://.’ Therefore, the if block checks whether the URL is absolute and prepends ‘https://’ if it isn’t.
Then, the code appends the title and the URL to the object extracted_records.
Finally, you can save this data into a JSON file using a JSON serializer.
with open('posts.json', 'w') as outfile:
json.dump(extracted_records, outfile, indent=4)The above code creates and opens a file called data.json and writes the data into it.
Here is the complete code of the scraper.
import urllib.request
from bs4 import BeautifulSoup
import json
url = "https://old.reddit.com/top/"
headers = {'user-agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.3'}
request = urllib.request.Request(url,headers=headers)
html = urllib.request.urlopen(request).read()
soup = BeautifulSoup(html,'html.parser')
#First lets get the HTML of the table called site Table where all the links are displayed
main_table = soup.find("div",attrs={'id':'siteTable'})
#Now we go into main_table and get every anchor element in it that has a class "title."
links = main_table.find_all("a",class_="title")
#List to store a dict of the data we extracted
extracted_records = []
for link in links:
title = link.text
url = link['href']
#There are better ways to check if a URL is absolute in Python. For the sake of simplicity we'll just stick to .startwith method of a string
if not url.startswith('http'):
url = "https://reddit.com"+url
# You can join urls better using the urlparsearse library of python.
}
extracted_records.append(record)
#Let's write these to a JSON file for now.
with open('posts.json', 'w') as outfile:
json.dump(extracted_records, outfile, indent=4)You can save this code in a file named ‘reddit_scraper.py’ and then execute it from a command-line interface.
There will be a file called posts.json in the same folder as the code with the extracted data. The extracted records should look like this.
[
{
"title": "It is ridiculous",
"url": "https://i.redd.it/sn1e301r6pnc1.jpeg"
},
{
"title": "Get an online friend who would do this for you",
"url": "https://i.redd.it/0hzd8wajgpnc1.jpeg"
},
{
"title": "Boeing whistleblower found dead in US in apparent suicide",
"url": "https://www.bbc.com/news/business-68534703"
},
{
"title": "Just imagine how republicans would react",
"url": "https://i.redd.it/ln1ta39ppqnc1.jpeg"
},
{
"title": "Messi the dog and his clapping paws at the Academy Awards",
"url": "https://i.redd.it/3swl6e9c8rnc1.jpeg"
},
{
"title": "Unbelievable!",
"url": "https://i.redd.it/r83syau94tnc1.jpeg"
},
{
"title": "Well",
"url": "https://i.redd.it/oxu7d71zopnc1.jpeg"
},
{
"title": "When United Airlines refused to pay for his broken guitar, Dave Carroll released a complaint diss track. This resulted in the Airline's stock to go down 10%, about 180 Million, and the incident is a Harvard case study.",
"url": "https://v.redd.it/nx1b2r8u6qnc1"
},
{
"title": "Joe Biden suddenly leads Donald Trump in multiple polls",
"url": "https://www.newsweek.com/presidential-election-latest-polls-biden-trump-1877928"
},
{
"title": "How movie characters die in different countries",
"url": "https://v.redd.it/dbn48b65prnc1"
},
{
"title": "Finally got married on my wife's 50th birthday after almost 20 years together",
"url": "https://www.reddit.com/gallery/1bccsho"
},
{
"title": "Meirl",
"url": "https://i.redd.it/zjosjjm3xpnc1.jpeg"
},
{
"title": "Throwing Meat from an offshore oilrig",
"url": "https://v.redd.it/olxdxmhx8qnc1"
},
{
"title": "What's your guilty pleasure movie?",
"url": "https://v.redd.it/fcqiqkxl3pnc1"
},
{
"title": "Too sweet for words",
"url": "https://v.redd.it/oqpps5pi8tnc1"
},
{
"title": "Bleed him dry",
"url": "https://i.redd.it/iyr4jzb0eqnc1.jpeg"
},
{
"title": "Boeing whistleblower found dead in US",
"url": "https://www.bbc.com/news/business-68534703"
},
{
"title": "An abandoned shrine in japan that I\u2019m trying to fix",
"url": "https://i.redd.it/s3gx70iy0pnc1.jpeg"
},
{
"title": "meirl",
"url": "https://i.redd.it/tgftr652jsnc1.jpeg"
},
{
"title": "America: Debt Free by 2013",
"url": "https://i.redd.it/jri6jd7jopnc1.jpeg"
},
{
"title": "Stand up to criminals, to pat them in the back and welcome them to the team.",
"url": "https://i.redd.it/mj7eu6ni6snc1.jpeg"
},
{
"title": "Amazing aiming skills at a fun fair game",
"url": "https://v.redd.it/ptqn7lartpnc1"
},
{
"title": "TIL Spike Lee negotiated with a Brazilian drug lord to allow him to film Michael Jackson's 96 music video 'They Don\u2019t Care About Us' in a Rio de Janeiro slum. The drug kingpin replied \u201cWith Michael Jackson here, this will be the safest place in the world.\u201d",
"url": "https://www.starsinsider.com/celebrity/269688/spike-lee-negotiated-with-a-brazilian-drug-lord-for-michael-jackson-video"
}
]Scraping post titles and URLs from Reddit: Code Limitations
The above code will execute properly if Reddit doesn’t change the site structure. Once the HTML structure of reddit.com changes, you must find the new XPaths and update the code. That means you need to analyze the HTML page again.
Moreover, large-scale data extraction requires more code to bypass anti-scraping measures and avoid getting caught while web scraping.
For example, Reddit does allow scraping but can block your IP if you make a large number of requests. You then need to change your IP address via a proxy, which you may need to keep changing after a certain number of requests. You call this proxy rotation, which this code doesn’t do.
Wrapping Up
Urllib and BeautifulSoup allow you to send HTTP requests and parse the response. You can use this method to extract data from various websites, including Reddit. However, you must consider the anti-scraping measures employed.
Moreover, you’ll have to monitor Reddit for any changes in their HTML structure so that you can update the code accordingly.
You can avoid learning how to scrape Reddit by choosing ScrapeHero Services. ScrapeHero is a fully managed web scraping service provider. We can create enterprise-grade web scrapers according to your requirements; ScrapeHero services range from large-scale web crawling to custom robotic process automation.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



