
This tutorial is the third part of “Scrape a Website Using Python: A Beginners Guide,” and it will show how to scrape Reddit comments. The previous part was about extracting Reddit post lists. Here, the code is for web scraping Reddit comments and other details of a post.
As before, the tutorial will extract details from https://old.reddit.com.
Below, you can read step-by-step instructions for web scraping Reddit comments using Python. The steps show scraping Reddit comments using BeautifulSoup and Urllib.
Data Extracted from Reddit
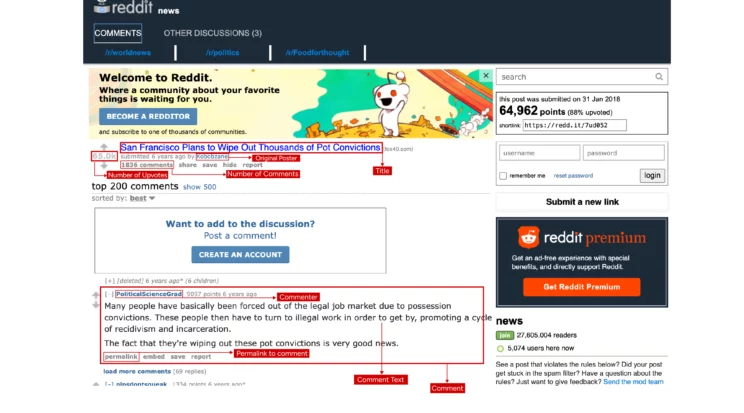
The code will extract these details from each post page.
- Title
- Permalink
- Original Poster
- Number of Upvotes
- Number of Comments
- Comments ( all visible ones )
- commenter
- comment text
- permalink to comment
Web Scraping Reddit Comments: The Code
Extract the Links of the Comments Page
A link to the comments page is necessary for web scraping user comments from Reddit. Here too, use the developer options to find the attributes required to locate the HTML elements.
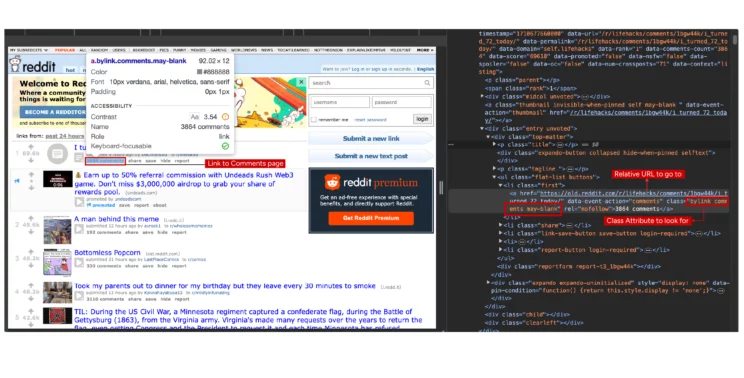
The link will be inside an anchor tag, and the anchor tag will have the class ‘bylink comments may-blank’. However, ensure that all the comment links have the same class attribute. Otherwise, the code won’t select all of them programmatically.
Fortunately, all the comment links here have the same class: bylink comments may-blank.
The code from the previous tutorial can work until the part where you extract the div element with the id siteTable.
import urllib.request
from bs4 import BeautifulSoup
import json
from time import sleep
url = "https://old.reddit.com/r/news/comments/7ud052/san_francisco_plans_to_wipe_out_thousands_of_pot/"
#Adding a User-Agent String in the request to prevent getting blocked while scraping
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.47 Safari/537.36'
request = urllib.request.Request(url,headers={'User-Agent': user_agent})
html = urllib.request.urlopen(request).read()
soup = BeautifulSoup(html,'html.parser')
#First lets get the HTML of the table called site Table where all the links are displayed
main_table = soup.find("div",attrs={'id':'siteTable'})The extracted div element is in the variable main_table.
Now, find all the anchor tags from main_table with the class bylink comments may-blank using find_all.
comment_a_tags = main_table.find_all('a',attrs={'class':'bylink comments may-blank'})
The next step is to extract hrefs from all the anchor tags and make all the relative URLs absolute.
Download the HTML code from each URL and extract the details, including the comments and the number of upvotes.
It is better to create a function that extracts the details from each post page. That way, you only have to call this function in a loop that iterates through the extracted URLs.
Locate the Required Elements in the HTML Code
Again, use the developer tools to inspect the HTML code of the comments page and figure out how to locate the elements. For each data point, right-click on it and select inspect to open the developer tools. An HTML code for that element will appear on the right pane.
Title
The anchor tag enclosing the title looks like this:
<a class="title may-blank outbound" data-event-action="title" href="http://fox40.com/2018/01/31/san-francisco-plans-to-wipe-out-thousands-of-pot-convictions/" tabindex="1" data-href-url="http://fox40.com/2018/01/31/san-francisco-plans-to-wipe-out-thousands-of-pot-convictions/" data-outbound-url="https://out.reddit.com/t3_7ud052?url=http%3A%2F%2Ffox40.com%2F2018%2F01%2F31%2Fsan-francisco-plans-to-wipe-out-thousands-of-pot-convictions%2F&token=AQAAeTb5ZXwuZvnReTc854IIHDRK5ArFYUw4Cz3X1eJ2156rjFdh&app_name=reddit.com" data-outbound-expiration="1710831225000" rel="nofollow ugc">San Francisco Plans to Wipe Out Thousands of Pot Convictions</a>
It seems possible to use the class attribute to locate the anchor tag as before. The data-event-action attribute can also locate the title.
The find() method in BeautifulSoup can locate and extract the title in either case.
soup.find('a',attrs={'class':'title may-blank outbound'}).text
soup.find('a',attrs={'data-event-action':'title'}).text
Also, check if there are multiple elements with the same selector; the code should not select any other anchor tag besides the one with the post title.
The find() method of BeautifulSoup selects the first element it matches and ignores the rest. For selecting multiple elements, use find_all().
This find_all() method will clarify if there are multiple elements matching the selection criteria.
soup.find_all('a',attrs={'class':'title'})The above code will show that there aren’t any other anchor tags with the class title. However, there will be 9 elements with the class title; this code will show that.
len(soup.find_all('a',attrs={'class':'title'}))Therefore, the anchor tag and the class make a unique selector for the title, even though multiple HTML elements with the class title exist.
The above discussion shows multiple ways to select the title.
title = soup.find_all('a',attrs={'class':'title'}).text
title = soup.find('a',attrs={'data-event-action':'title'}).text
title = soup.find('a',attrs={'class':'title may-blank outbound'}).text
Number of Upvotes
Here is the HTML code behind the upvotes
<div class="midcol unvoted"> <div class="arrow up login-required access-required" data-event-action="upvote" role="button" aria-label="upvote" tabindex="0"></div> <div class="score dislikes" title="88324">88.3k</div> <!-- THE DIV BELOW WOULD BE HIGHLIGHTED --> <div class="score unvoted" title="88325">88.3k</div> <div class="score likes" title="88326">88.3k</div> <div class="arrow down login-required access-required" data-event-action="downvote" role="button" aria-label="downvote" tabindex="0"></div> </div>
Reddit has 3 divs for upvotes with different classes:
- score_dislikes: for someone who has downvoted
- score_unvoted: for someone who hasn’t voted
- score_likes: for the upvoter
The code doesn’t log in or upvote using this scraper, so only select the div with the class score_unvoted.
soup.find_all('div',attrs={'class':'score unvoted'})
The above code will give
[<div class="score unvoted" title="64966">65.0k</div>]
Therefore, the selector is appropriate for the data point. Next, extract the text using it.
upvotes = soup.find('div',attrs={'class':'score unvoted'}).textOriginal Poster
The original poster or the username of the person who submitted the link is inside an anchor similar to
<a href="https://old.reddit.com/user/Kobobzane" class="author may-blank id-t2_1389xh">Kobobzane</a>
The class of the anchor tag seems to be a random number and may vary with each post, which is easy to check by analyzing the code of another comment page.
For example, the anchor tag of the comment page
<a href="https://old.reddit.com/user/sixty9e" class="author may-blank id-t2_a623f7ost">sixty9e</a>
Here, the value is different, but it also has the same class author. You can check if the selector is suitable with len().
len(soup.find_all('a',attrs={'class':'author'}))len() gives the number of items in the list returned by find_all().
There will be more than one anchor tag with the class author, making the selector unsuitable. To solve this problem, find the div element that includes the title link.
The HTML code shows that those details are inside a div element with the ID siteTable.
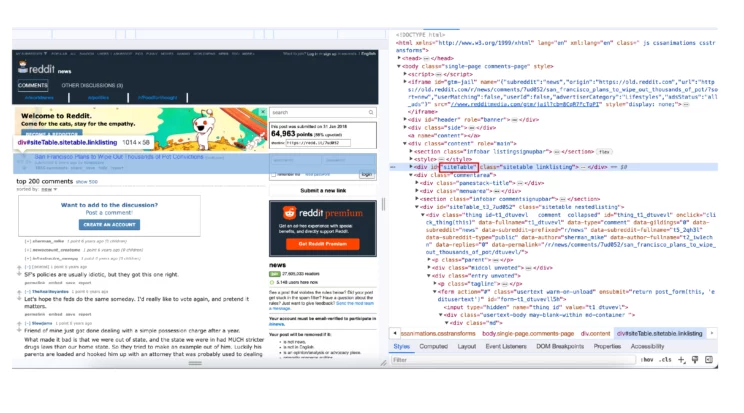
Now, extract the div using find() and check the number of anchor tags associated with the class author.
main_post = soup.find('div',attrs={'id':'siteTable'})
len(main_post.find_all('a',attrs={'class':'author'}))There is only one such tag in the div siteTable, allowing you to extract the title, upvotes, and original poster.
title = main_post.find('a',attrs={'class':'title'}).text
upvotes = main_post.find('div',attrs={'class':'score unvoted'}).text
original_poster = main_post.find('a',attrs={'class':'author'}).text
Number of Comments
The number of comments is also in the div siteTable. It is inside an anchor tag with the class bylink comments may-blank.
<a href="https://old.reddit.com/r/unitedstatesofindia/comments/1bibrd8/dont_shout_at_me_cji_chandrachud_reprimands/" data-event-action="comments" class="bylink comments may-blank" rel="nofollow">57 comments</a>
This code can extract the number of comments.
comments_count = main_post.find('a',attrs={'class':'bylink comments may-blank'}).text
Comments
There are a lot of comments on the page, and you want to extract certain details from each of them. Therefore, it is better to select the comments section as a whole and then extract Reddit comments and details from it.
The comments are in a div with the class commentarea.
comment_area = soup.find('div',attrs={'class':'commentarea'})First, find all the comments. Inspecting the div commentarea will show that each comment is in a div with the class entry unvoted. Next, use this code to select all the comments in commentarea.
comments = comment_area.find_all('div', attrs={'class':'entry unvoted'})Loop through the extracted comments and extract the commenter, comment text, and permalink of each comment.
However, the HTML code shows that comments without a form tag have a ‘load more’ link. So extract only those comments with a form tag.
That is why the code uses a conditional statement to ensure that it only tries to extract details from the comments with a form tag.
for comment in comments:
if comment.find('form'):
try:
commenter = comment.find(attrs={'class':'author'}).text
comment_text = comment.find('div',attrs={'class':'md'}).text.strip()
permalink = comment.find('a',attrs={'class':'bylink'})['href']
extracted_comments.append({'commenter':commenter,'comment_text':comment_text,'permalink':permalink})
except:
extracted_comments.append({'commenter':"none",'comment_text':"none",'permalink':"none"})
The code uses a try-except block; this ensures code completion even if it encounters some comments deleted by its authors.
These deleted comments do not have a commenter, even though the comment itself is visible.
Post Permalink
The post permalink is directly available in the HTTP response.
permalink = request.full_urlDefine a Function for Parsing
You can now integrate all the techniques discussed above and make a function parse_comment_page.
This function accepts a comment page URL and returns the data extracted from the page as a dict.
def parse_comment_page(page_url):
#Adding a User-Agent String in the request to prevent getting blocked while scraping
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.47 Safari/537.36'
request = urllib.request.Request(page_url,headers={'User-Agent': user_agent})
html = urllib.request.urlopen(request).read()
soup = BeautifulSoup(html,'html.parser')
main_post = soup.find('div',attrs={'id':'siteTable'})
title = main_post.find('a',attrs={'class':'title'}).text
upvotes = main_post.find('div',attrs={'class':'score unvoted'}).text
original_poster = main_post.find('a',attrs={'class':'author'}).text
comments_count = main_post.find('a',attrs={'class':'bylink comments may-blank'}).text
comment_area = soup.find('div',attrs={'class':'commentarea'})
comments = comment_area.find_all('div', attrs={'class':'entry unvoted'})
print(len(comments))
extracted_comments = []
for comment in comments:
if comment.find('form'):
try:
commenter = comment.find(attrs={'class':'author'}).text
comment_text = comment.find('div',attrs={'class':'md'}).text.strip()
permalink = comment.find('a',attrs={'class':'bylink'})['href']
extracted_comments.append({'commenter':commenter,'comment_text':comment_text,'permalink':permalink})
except:
extracted_comments.append({'commenter':"none",'comment_text':"none",'permalink':"none"})
#Lets put the data in dict
post_data = {
'title':title,
'no_of_upvotes':upvotes,
'poster':original_poster,
'no_of_comments':comments_count,
'comments':extracted_comments
}
print(post_data)
return post_dataIntegrate Everything
It is possible to extract the details from any comments page on Reddit using the above function. However, this Python tutorial for web scraping Reddit comments will show you how to navigate to multiple comment pages. The code uses a loop to do that.
Set up the loop to repeatedly call parse_comments_page and append the data to a variable named extracted_data.
Finally, save the data to a JSON file.
Here is the complete code for web scraping Reddit using Python. By tweaking a little, you can also use this code to scrape a subreddit.
import urllib.request
from bs4 import BeautifulSoup
import json
from time import sleep
def parse_comment_page(page_url):
#Adding a User-Agent String in the request to prevent getting blocked while scraping
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.47 Safari/537.36'
request = urllib.request.Request(page_url,headers={'User-Agent': user_agent})
html = urllib.request.urlopen(request).read()
soup = BeautifulSoup(html,'html.parser')
main_post = soup.find('div',attrs={'id':'siteTable'})
title = main_post.find('a',attrs={'class':'title'}).text
upvotes = main_post.find('div',attrs={'class':'score unvoted'}).text
original_poster = main_post.find('a',attrs={'class':'author'}).text
comments_count = main_post.find('a',attrs={'class':'bylink comments may-blank'}).text
comment_area = soup.find('div',attrs={'class':'commentarea'})
comments = comment_area.find_all('div', attrs={'class':'entry unvoted'})
print(len(comments))
extracted_comments = []
for comment in comments:
if comment.find('form'):
try:
commenter = comment.find(attrs={'class':'author'}).text
comment_text = comment.find('div',attrs={'class':'md'}).text.strip()
permalink = comment.find('a',attrs={'class':'bylink'})['href']
extracted_comments.append({'commenter':commenter,'comment_text':comment_text,'permalink':permalink})
except:
extracted_comments.append({'commenter':"none",'comment_text':"none",'permalink':"none"})
#Lets put the data in dict
post_data = {
'title':title,
'no_of_upvotes':upvotes,
'poster':original_poster,
'no_of_comments':comments_count,
'comments':extracted_comments
}
print(post_data)
return post_data
url = "https://old.reddit.com/r/news/comments/7ud052/san_francisco_plans_to_wipe_out_thousands_of_pot/"
#Adding a User-Agent String in the request to prevent getting blocked while scraping
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.47 Safari/537.36'
request = urllib.request.Request(url,headers={'User-Agent': user_agent})
html = urllib.request.urlopen(request).read()
soup = BeautifulSoup(html,'html.parser')
#First lets get the HTML of the table called siteTable where all the links are displayed
main_table = soup.find("div",attrs={'id':'siteTable'})
comment_a_tags = main_table.find_all('a',attrs={'class':'bylink comments may-blank'})
extracted_data = []
#Remove[:10] to scrape all links
for a_tag in comment_a_tags[:10]:
url = a_tag['href']
if not url.startswith('http'):
url = "https://reddit.com"+url
print('Extracting data from %s'%url)
#Lets wait for 5 seconds before we make requests, so that we don't get blocked while scraping.
#if you see errors that say HTTPError: HTTP Error 429: Too Many Requests , increase this value by 1 second, till you get the data.
extracted_data.append(parse_comment_page(url))
with open("comments.json","w") as jsonFile:
json.dump(extracted_data,jsonFile,indent=4)
#Lets wait for 10 seconds before we make requests, so that we don't get blocked while scrapingCode Limitations
This code is capable of web scraping Reddit using Python on a small scale. On a large scale, the code needs additional changes. That is because Reddit may block the IP address if the code makes too many HTTP requests.
In such cases, you need techniques such as IP rotation to scrape without getting blocked.
Moreover, keep track of Reddit’s HTML structure, or this code will fail. The reason is that the Python code locates the HTML elements based on the website’s structure. When the structure changes, the code won’t be able to locate the elements.
Wrapping Up
Web scraping Reddit using Python is possible with libraries such as Urllib and BeautifulSoup. You can use them to build a scraper that can extract comments from posts. However, beware of the changes in the HTML code of their website.
Whenever Reddit’s HTML code changes, reanalyze the website and figure out new attributes to look for while scraping.
Moreover, this code does not consider anti-scraping measures, like IP blocking. You require an advanced code to get around that. But you don’t have to worry about all that if you choose ScrapeHero.
ScrapeHero is a full-service, enterprise-grade web scraping service provider. We can build high-quality web scrapers the way you want. Leave all the hassle to us. Our services range from large-scale web crawlers to custom robotic process automation. We also have pre-built web scrapers on ScrapeHero Cloud that offer a no-code solution.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



