
Manually extracting job posting data from websites is hectic and time-consuming. But when scraping job postings using Python scrapers, this job is easily done.
In this tutorial, you will learn how to scrape Glassdoor and extract job data, including job name, company, salary, etc.
Data Fields To Extract When Scraping Glassdoor Jobs
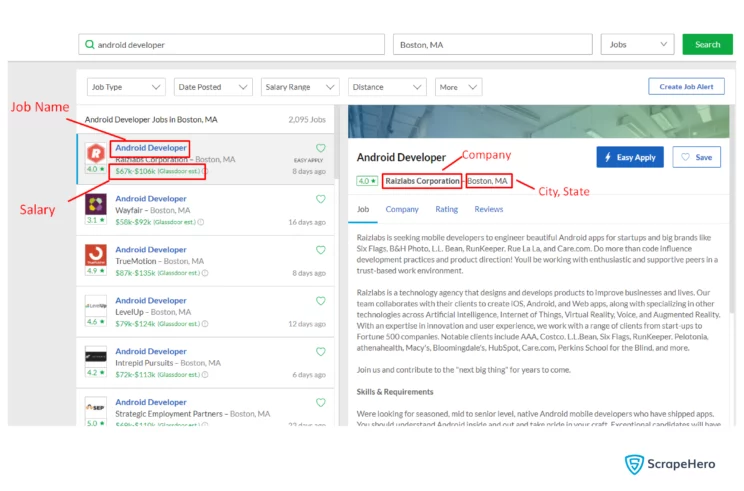
Here is the list of fields that you will scrape from Glassdoor using the scraper:
- Job Name
- Company
- State
- City
- Salary
- URL
Scraping Logic for Extracting Glassdoor Job Listings
To scrape Glassdoor job postings using Python, you need to first understand the scraping logic behind it.

- To scrape Glassdoor using Python, first construct the URL for the search results from Glassdoor. Let’s find Glassdoor listings related to the job of Android developer in Boston, Massachusetts
- Download the HTML of the search result page using Playwright
- Parse the page using LXML and collect the URLs for each job description page using XPaths
- Go to each job description URL using Playwright and download the HTML result of the job description page using Playwright
- Parse the page using LXML, and extract the required data using XPaths
- Save the data to a CSV file. For saving bulk details, you can use a JSON file
Requirements
1. Python 3 and Pip
Install Python 3 and Pip for various operating systems using the guides:
- Linux – Python 3 in Linux
- Mac – Python 3 in Mac
- Windows – Python 3 in Windows
2. Packages
For downloading and parsing the HTML, install the packages:
- PIP – PIP is used to install different packages in Python.
- LXML – LXML is needed to parse the HTML Tree Structure using XPaths.
- Playwright – Install Playwright.
- Unicodecsv – Install Unicodecsv for the csv file.
Running the Scraper
The name of the script is glassdoor.py. If you type in the script name in the terminal or command prompt with a -h
usage: glassdoor.py [-h] keyword place
positional arguments:
keyword job name
place job location
optional arguments:
-h, --help show this help message and exitThe argument “keyword” represents a keyword related to the job you are searching for, and the argument “place” is used to find the desired job in a specific location.
To find the list of Android developers in Boston, run the script like this:
python3 glassdoor.py "android-developer" "boston"This will create a CSV file named Android developer-Boston-job-results.csv that will be in the same folder as the script. After scraping Glassdoor job data the result obtained will be in a CSV file will be like this:
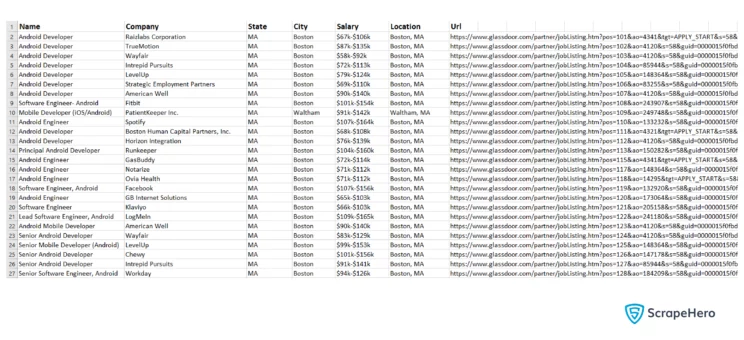
Get the complete code to scrape Glassdoor job data using Python and LXML on GitHub.
ScrapeHero Glassdoor Job Listings Scraper – An Alternate
By web scraping job posts from Glassdoor, you can use the data for various purposes. The Python scraper you have created now works for extracting most job listings on Glassdoor unless the website structure changes drastically.
Also, overcoming the anti-scraping measures by websites might become a major challenge especially when you try to scrape Glassdoor job postings using Python.
In such situations, to scrape job data from Glassdoor you can use ScrapeHero Glassdoor Job Listings Scraper by ScrapeHero Cloud, which can save you time and effort. It’s free up to 25 credits, involves no coding on your part, and easy to use.

Wrapping Up
Glassdoor scraping with a Python scraper is an effective way to collect job data. But if you like to scrape the details of thousands of pages at very short intervals, this scraper is probably not going to work. So you may need to build and run scrapers on a large scale, which is not always possible.
ScrapeHero can be your professional scraping partner so that you can meet all your enterprise-grade requirements. ScrapeHero web scraping services can offer you scalable solutions that manage data volume efficiently, providing clean, structured, and relevant data for specific needs.
Frequently Asked Questions
Yes. You can scrape Glassdoor job listings either by creating your own scraper or by using pre-built scrapers like ScrapeHero Glassdoor Job Listings Scraper.
First, construct the URL for Glassdoor search results and then download the page’s HTML. Then, parse and collect job description page URLs. Visit each URL and parse these pages with LXML to extract the required data using XPaths. Finally, save this data into a CSV.
The legality of web scraping depends on the jurisdiction, but it is generally considered legal if you are scraping publicly available data. Please refer to Legal Information to learn more about the legality of web scraping.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



