
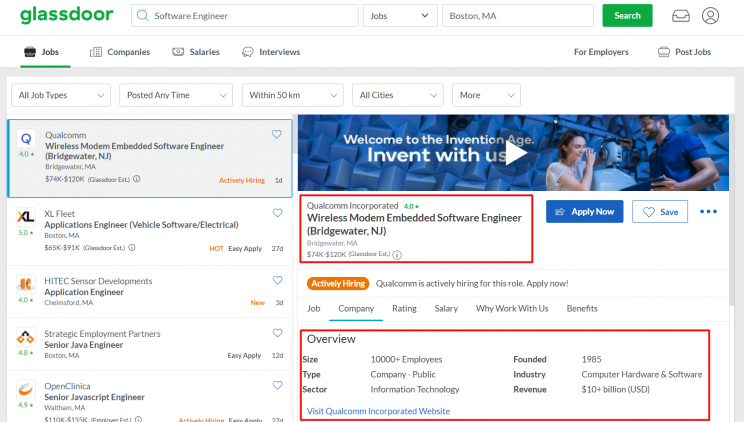
Glassdoor is one of the world’s largest job recruiting websites that offers millions of job listings. This tutorial will help you scrape job data from any Glassdoor domain using the Glassdoor Job Listings Crawler in the ScrapeHero Cloud. The crawler accepts multiple search URLs and filters. You can scrape Glassdoor for job data such as Job title, salary, company, address, industry, revenue, website, and more.
Here are the steps to scrape Glassdoor job data
- Create a ScrapeHero Cloud account and add the Glassdoor crawler
- Input the list of job listings URLs
- Run the scraper and download the data
Web scraping Glassdoor job data can help you gather job listings and data feeds over a certain time period. You can identify when jobs are listed to make an analysis on jobs that are trending and the companies, industries that are currently hiring. You can also combine the job data scraped from the Indeed Job Listings Crawler to create your own job boards, monitor the competition for job listings, predict and analyze job trends.
The ScrapeHero Cloud has pre-built scrapers which help businesses to easily gather data from job listing websites such as Glassdoor and Indeed. These scrapers are easy to use and cloud-based, you need not worry about selecting the fields to be scraped nor download any software. The scraper and the data can be accessed from any browser at any time and can deliver the data directly to Dropbox.

What are we extracting from Glassdoor?
- Job Title
- Locations
- Posted Date
- Company Name
- Estimated Salary
- Headquarters
- Rating
- Sector
- Revenue
- Website
- Company Size
- Year Founded
- Industry
- Description
- URL
Step 1 – Create an Account
First, we will create a ScrapeHero Cloud account. To sign up go to the link – https://cloud.scrapehero.com/accounts/login/ and create an account with your email address.

Step 2 – Input the Details
The crawler accepts any job listing URL and from all Glassdoor domains. Go to Glassdoor.com and search for a particular location and job title. Select you necessary filters such as – job type, salary range, location and more. Copy and paste the URL into the input field for Search URLs/Job Listing URLs.
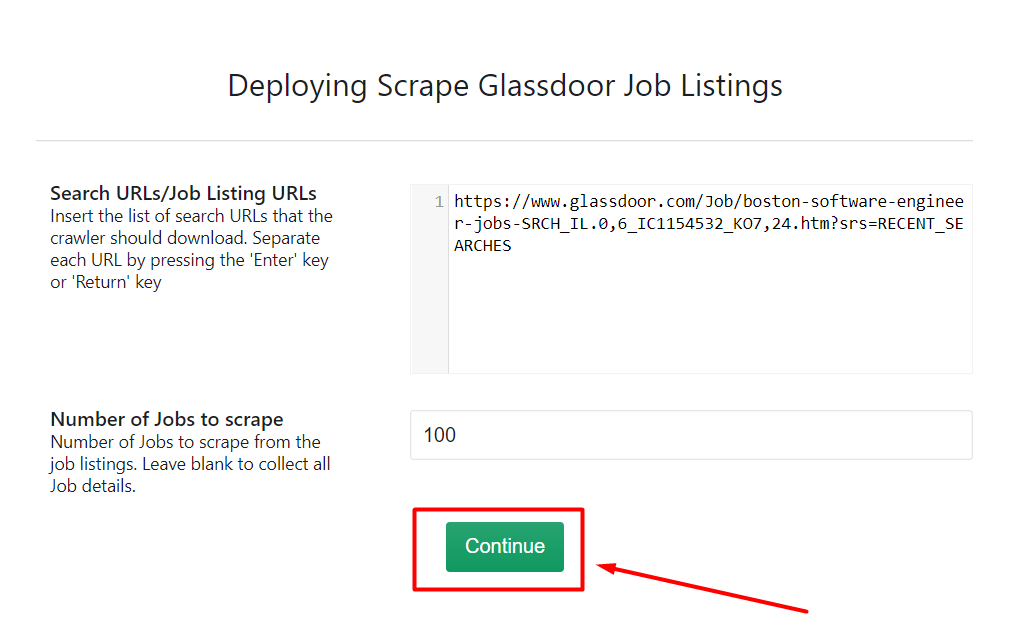
Example:
https://www.glassdoor.com/Job/boston-software-engineer-jobs-SRCH_IL.0,6_IC1154532_KO7,24.htm?srs=RECENT_SEARCHES
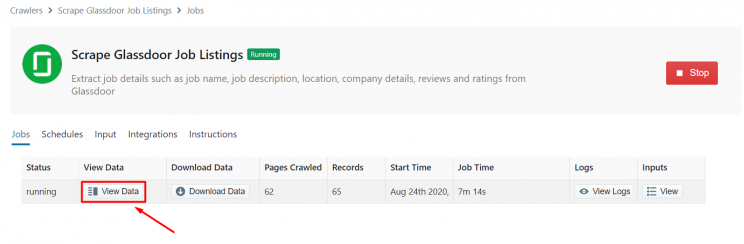
Step 3 – Run the Glassdoor Scraper
The Glassdoor crawler page will open up and you will see the option to ‘Gather Data’. Once you have clicked it the scraper will start to run.

After the scrape is complete the ‘Status’ of the crawler will change from ‘Started’ to ‘Finished’. Click on ‘View Data’ to view the scraped data.
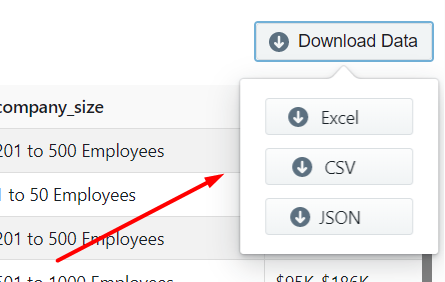
Step 4 – Download Glassdoor Data
You can see all the job data scraped on this page. To download the scraped job data click on ‘Download Data’.

A drop down to select a data format will appear. You can choose between CSV, JSON, and XML formats. After clicking on the data format option, a file will soon be downloaded with all the scraped Glassdoor job data.
You can get data delivered to Dropbox if you integrate the crawler account to your Dropbox account. You also have the option to schedule the data if you want to extract Glassdoor data on a timely basis.
Here is how the scraped Glassdoor data looks like.
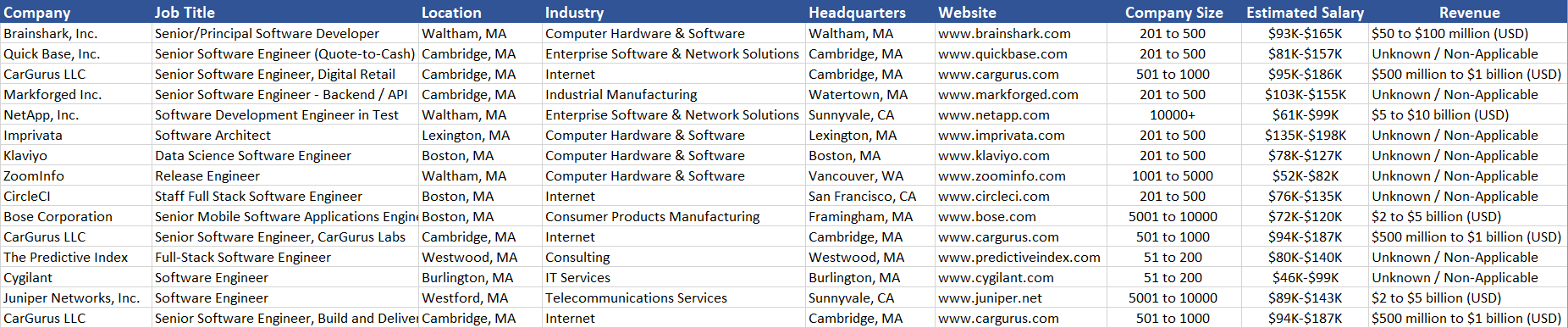
If you would like to learn how to scrape Glassdoor listings on your own you can head over to our Python tutorial. If you are interested in scraping Indeed, you can follow this tutorial to scrape Indeed Job Listing data.
Turn the Internet into meaningful, structured and usable data
We can help with your data or automation needs


