
Playwright is an open-source web automation framework like Selenium and Puppeteer that allows the automation of web applications and browsers, end-to-end testing, and web scraping in Python,.NET, Java, or Node.js. It is essential to block specific resources in Playwright while web scraping in order to save time and money.
This article discusses how you can block resources from loading during web scraping.
Why Block Playwright Resources?
Before beginning, understand why you need to block specific resources in Playwright. The following are some reasons for this:
Speed
When the number of requests is reduced, it can automatically speed up your scraping tasks. For any scraping service that matters, speed is a key performance metric. Fewer resources speed up the process.
Bandwidth
When resource-intensive files are skipped, especially when running large-scale operations, you can save bandwidth. If you block specific resources in Playwright the bandwidth can be reduced.
Focus
Extraneous content should be blocked in order to focus on the relevant data for your use case. Only HTML content will be required for scraping text-based data. Unnecessary resources can make the scraping process harder.
Cost Efficiency
When content-rich resources are avoided, there is less bandwidth, which ultimately leads to cost efficiency. This is particularly beneficial if you need to perform large-scale scraping.
Legal Considerations
Limiting the scope of your scraping to just the data needed could make your operations less intrusive, which might be beneficial from a legal standpoint.
Server Load
A website’s server gets overloaded often with frequent and heavy requests. When you block specific resources in Playwright, you are lessening the server load and obtaining the result you need in a much more efficient and faster way.
Note: In some cases, you might need the loading of certain resources to render a web page properly or to trigger specific JavaScript events.
One of the biggest disadvantages of web scraping with browsers is that it is expensive to run on a large scale due to the amount of computing and network bandwidth required. The biggest reason for the increase in network bandwidth is the additional requests that are fetched to render a web page.
Unlike a traditional web scraper that downloads the HTML file of a web page and parses it, a web scraper built with a browser “renders” the page by requesting every resource marked in the HTML file that is required for “painting” the web page. These could be images, CSS stylesheets, web fonts, JavaScript libraries, JavaScript files, etc.
To give you an example, let’s take a look at the percentage of requests that are downloaded to render this page: https://scrapeme.live/shop/
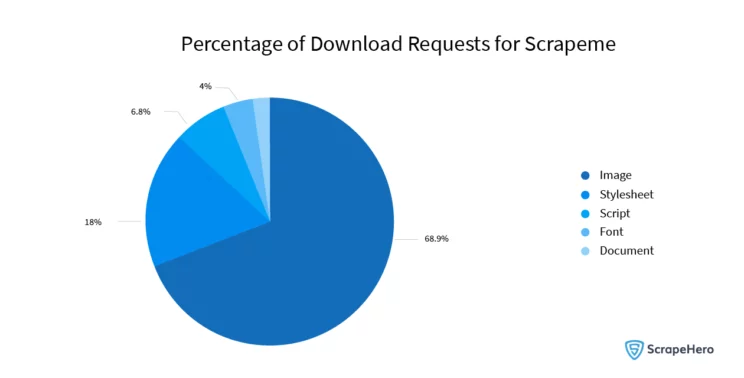
1.9 MB, and 51 requests are sent in the background. Nearly 69% of those are images, and 18% are stylesheets. You could save a large percentage of the network bandwidth used if you block specific resources in Playwright that are not necessary.
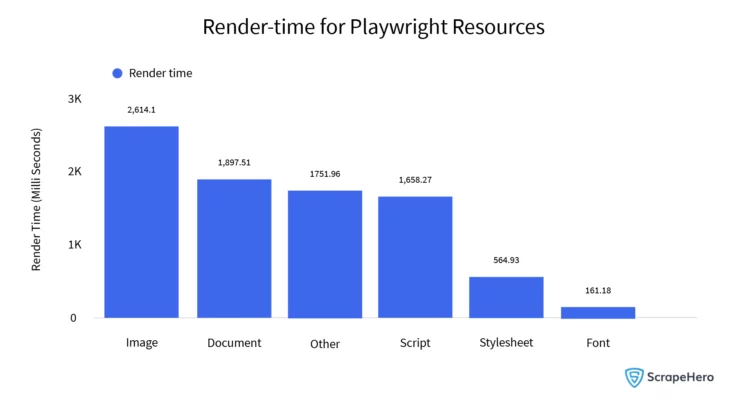
Rendering web pages also takes up time, increasing the run time of your web scrapers. 2614 milliseconds are required for rendering the images. In most cases, you may not need to render images and CSS while scraping a website. You could reduce the time spent waiting for the page to render if you blocked these requests.
If you are building a browser-based scraper to take screenshots of a web page or check how the page is rendered, blocking resources wouldn’t make sense.
The technique that can be used to block these requests is called Request Interception.
Even if you are able to block specific resources in Playwright, you have to understand that it is difficult to block specific browsers in Playwright as it is not directly supported by the framework. However, using some workarounds like User-Agent strings, blocking at the server level, or writing custom middleware in Playwright, you can achieve the results.
What Types of Resources Can Be Intercepted in Playwright?
You could technically intercept any type of request. The resource types supported by Playwright are listed below:
- document: an HTML or XML file.
- stylesheet: CSS stylesheet for the web page
- image: image files like PNG, JPG, etc.
- media: resources loaded via a <video> or <audio> element
- font: web fonts
- script: JavaScript code loaded via <script> tags
- texttrack: text tracks for audio or video
- xhr: short for XML HTTP Request, primarily used for AJAX requests for data. Most websites that render data using JavaScript code use this type, so these are better left unblocked.
- fetch: similar to XHR, but fetched using the new fetch() method.
- eventsource: opens a persistent connection to an HTTP server, which sends events in text or event-stream format.
- websocket: web socket connections that are opened between a browser and a web socket server
- manifest: JSON specification for Progressive Web Apps
- other: resources that aren’t covered by any other available type.
Blocking font, media, image, and stylesheet requests is generally safe for web scraping, as most pages will not lose any data. As you saw above, blocking images and stylesheets will give you the most savings. So it is crucial that you block specific resources in Playwright to make web scraping easier.
How To Intercept Requests in Playwright
Using the code given in this article, you can intercept images, JavaScript, CSS style sheets, and fonts in Playwright. You can put any of the types specified above into the set of resource types below and it would be blocked.
The function intercept below checks each request against a list of unwanted resource types. If a request type is in our block list, the request will be aborted by calling await route.abort() else allowed by calling await route.continue_().
import asyncio
from playwright.async_api import Playwright, async_playwright
async def intercept(route, request):
if request.resource_type in {'image', 'media', 'stylesheet', 'font'}:
await route.abort()
else:
await route.continue_()
async def run(playwright: Playwright) -> None:
browser = await playwright.chromium.launch(headless=False)
context = await browser.new_context()
# Open new page
page = await context.new_page()
# adding interception
await page.route('**/*', intercept)
# Go to https://scrapeme.live/shop/
await page.goto("https://scrapeme.live/shop/")
# ---------------------
await context.close()
await browser.close()
async def main() -> None:
async with async_playwright() as playwright:
await run(playwright)
asyncio.run(main())
Having the simple code out of our way, lets get into so more details regarding the type
Intercept and Block Images
You can block specific resources in Playwright like images by blocking the resource type – image. Blocking images will give you the best bandwidth savings, as images are the largest resource requested by most web pages.
async def intercept(route, request):
if request.resource_type in {'image'}:
await route.abort()
else:
await route.continue_()
await page.route("**/*", intercept)
You shouldn’t block images if the purpose of your scraper is to actually download the images.
Intercept and Block CSS Stylesheets
In most use cases, a CSS Stylesheet is not required for web scraping. They are safe to block. You can block CSS Stylesheets by intercepting the resource type stylesheet.
If your web scraper’s logic has clicks based on the position of a button, blocking CSS would mess with that logic. You might want to target the click with CSS Selector instead.
async def intercept(route, request):
if request.resource_type in {'stylesheet'}:
await route.abort()
else:
await route.continue_()
await page.route("**/*", intercept)
Intercept and Block JavaScript Files
JavaScript files or scripts loaded via the script tag are generally not safe to block. Most of the logic of a web page rendered via JavaScript would lie in these scripts, and blocking them would just mess up the data.
With careful trial and error, you could block JavaScript resources that are not crucial to rendering the web page with the data you need. For example, you could block Google Analytics, website trackers, etc. For this read the section “How to block requests in Chrome ?” mentioned in the article.
Here is the code to block all JavaScript resources in Playwright.
async def intercept(route, request):
if request.resource_type in {'script'}:
await route.abort()
else:
await route.continue_()
await page.route("**/*", intercept)
You can also block specific resources in Playwright like JavaScript requests.
async def intercept(route, request):
urls_to_block = ['https://www.google-analytics.com/analytics.js','https://www.googletagmanager.com/gtm.js','https://static.hotjar.com']
if request.resource_type in {'script'} and any(t in request.url for t in urls_to_block) :
await route.abort()
else:
await route.continue_()
await page.route("**/*", intercept)
A Request Interceptor in Action
Let’s look at a request interceptor in action and see the savings. You can see that this is the same code as at the beginning of the article.
import asyncio
from playwright.async_api import Playwright, async_playwright
async def intercept(route, request):
if request.resource_type in {'image', 'media', 'stylesheet', 'font'}:
await route.abort()
else:
await route.continue_()
async def run(playwright: Playwright) -> None:
browser = await playwright.chromium.launch(headless=False)
context = await browser.new_context()
# Open new page
page = await context.new_page()
# adding interception
await page.route('**/*', intercept)
# Go to https://scrapeme.live/shop/
await page.goto("https://scrapeme.live/shop/")
# ---------------------
await context.close()
await browser.close()
async def main() -> None:
async with async_playwright() as playwright:
await run(playwright)
asyncio.run(main())
Let’s run the scraper.
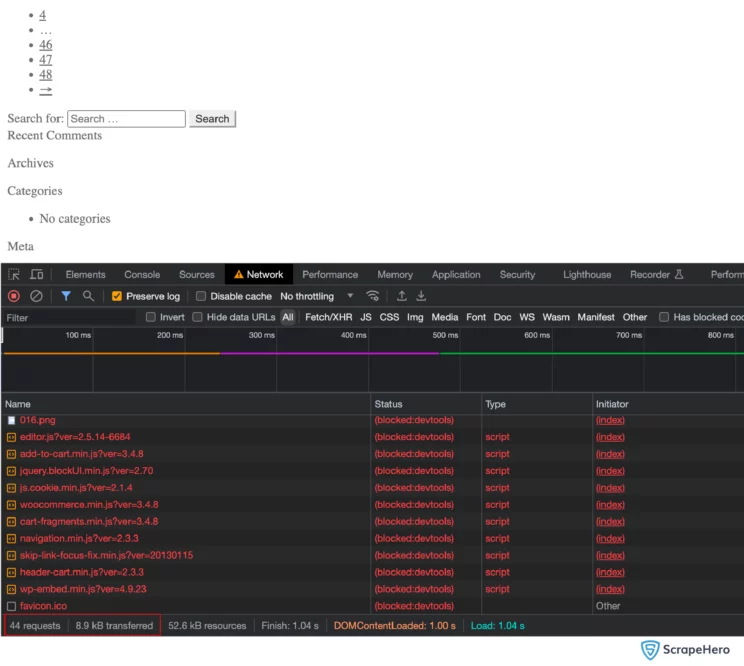
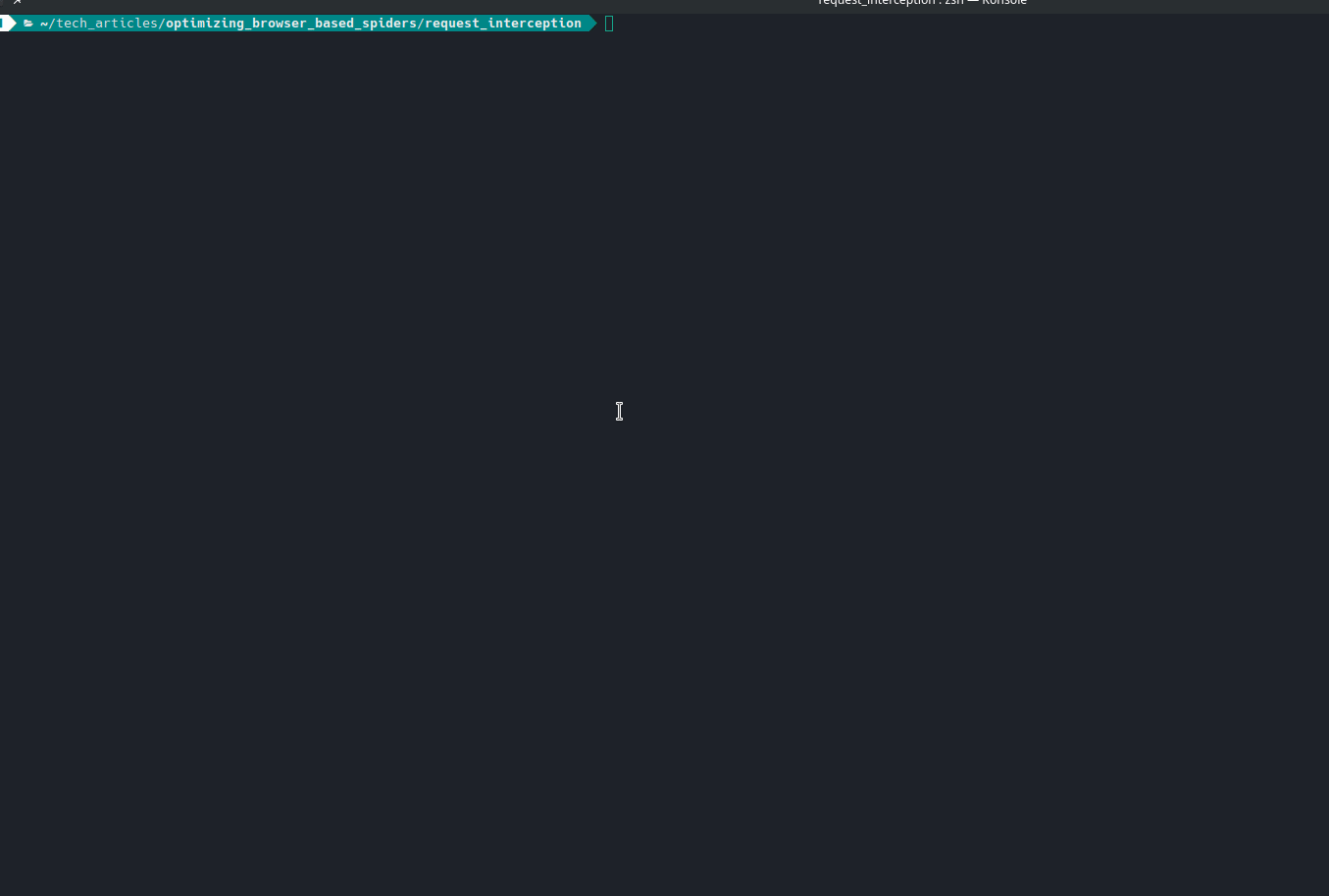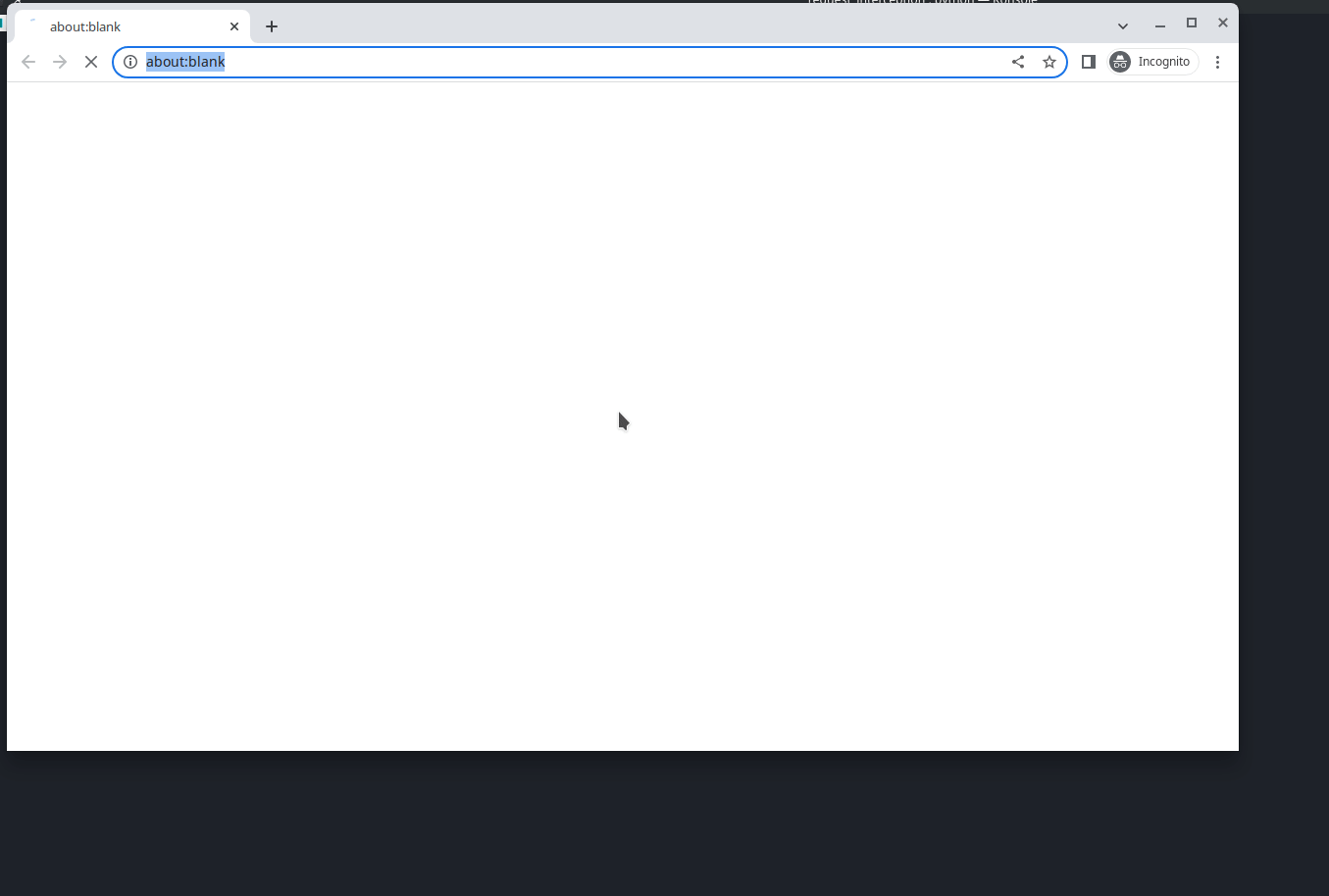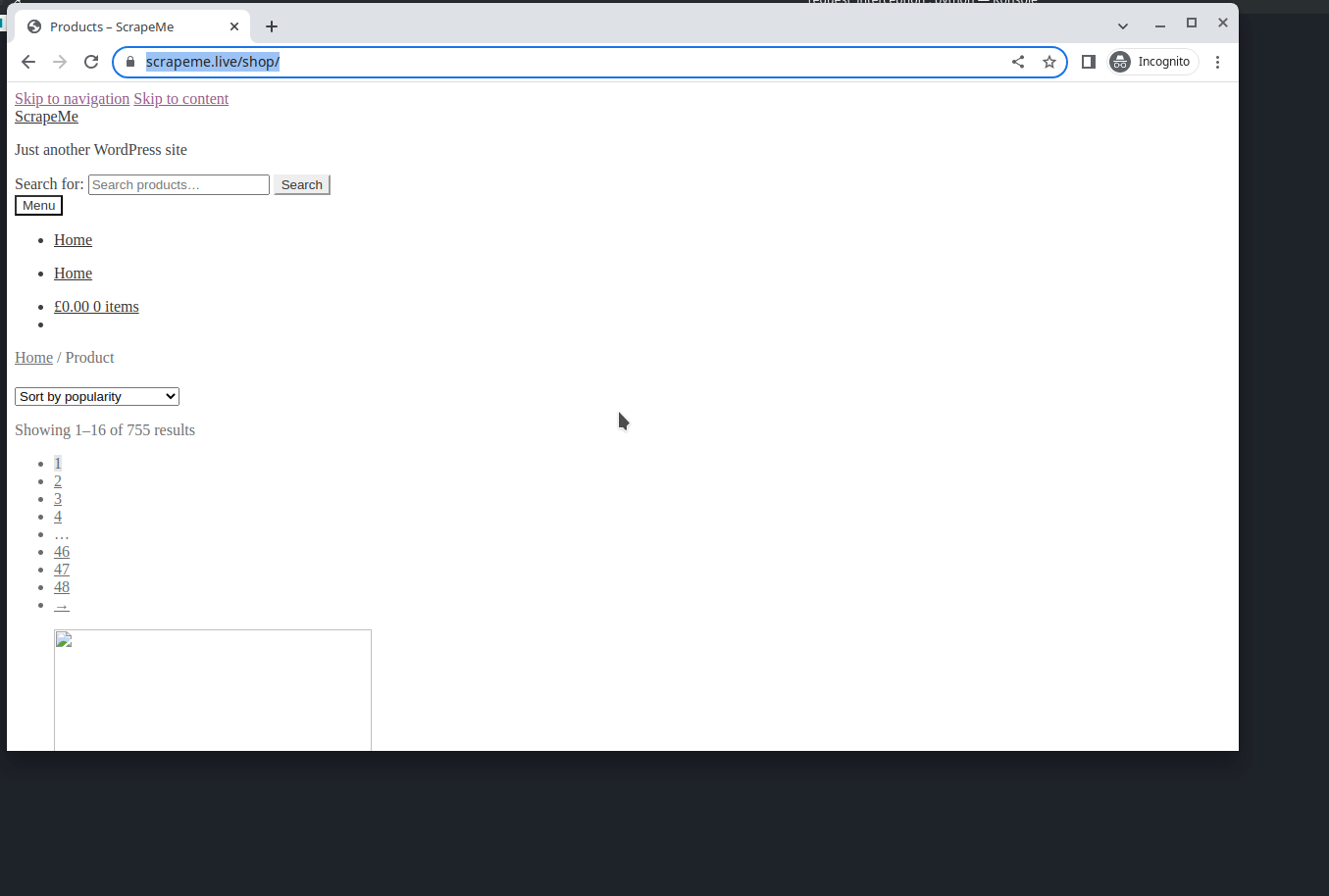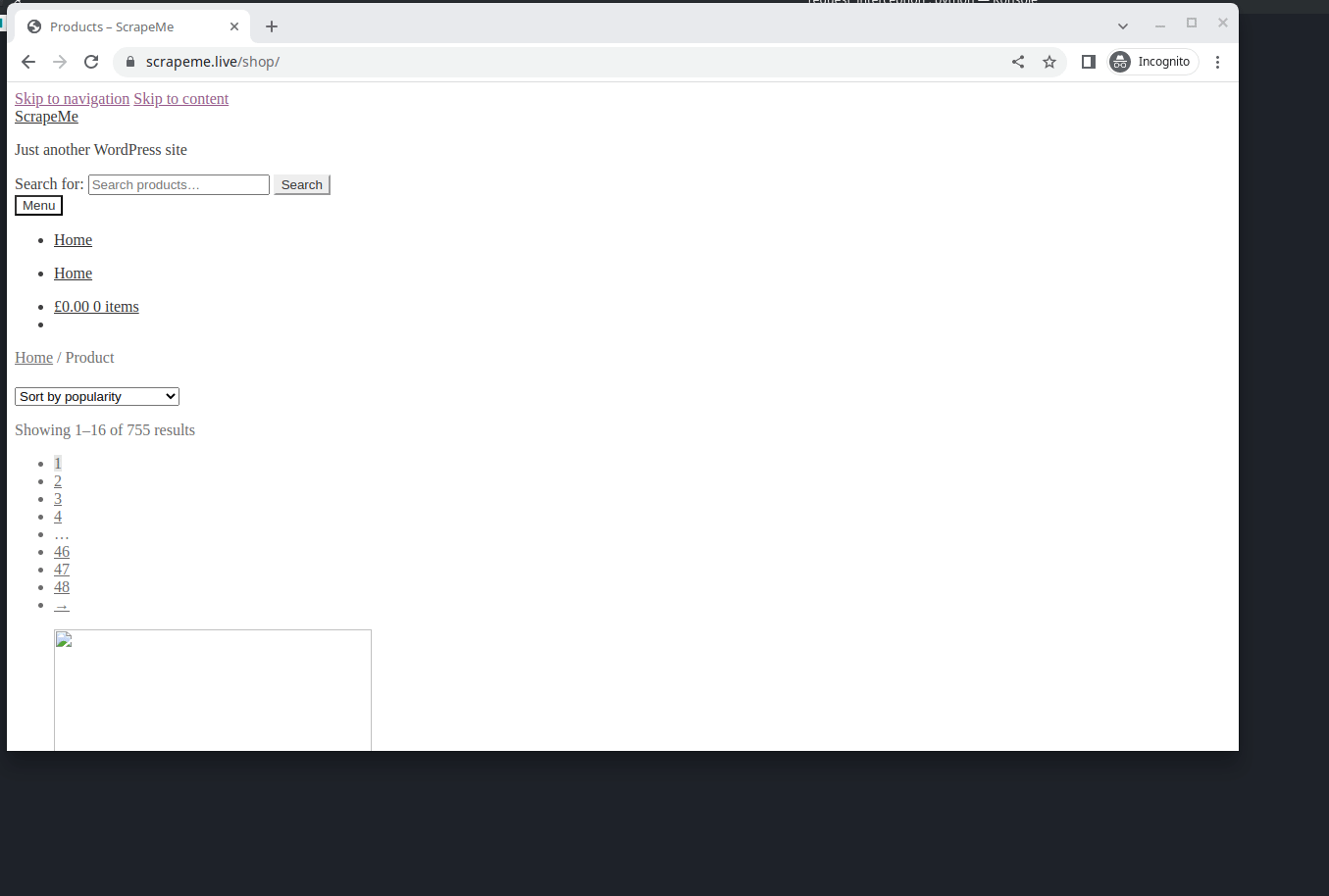
You can see that, after intercepting unwanted requests, the bandwidth transferred has been reduced to 8.7kb and the time taken to load the web page has decreased to 2.05 seconds. When it comes to large-scale web scraping, Request Interception can make a significant difference in time and resource costs. You can see the difference below:
Without request interception:
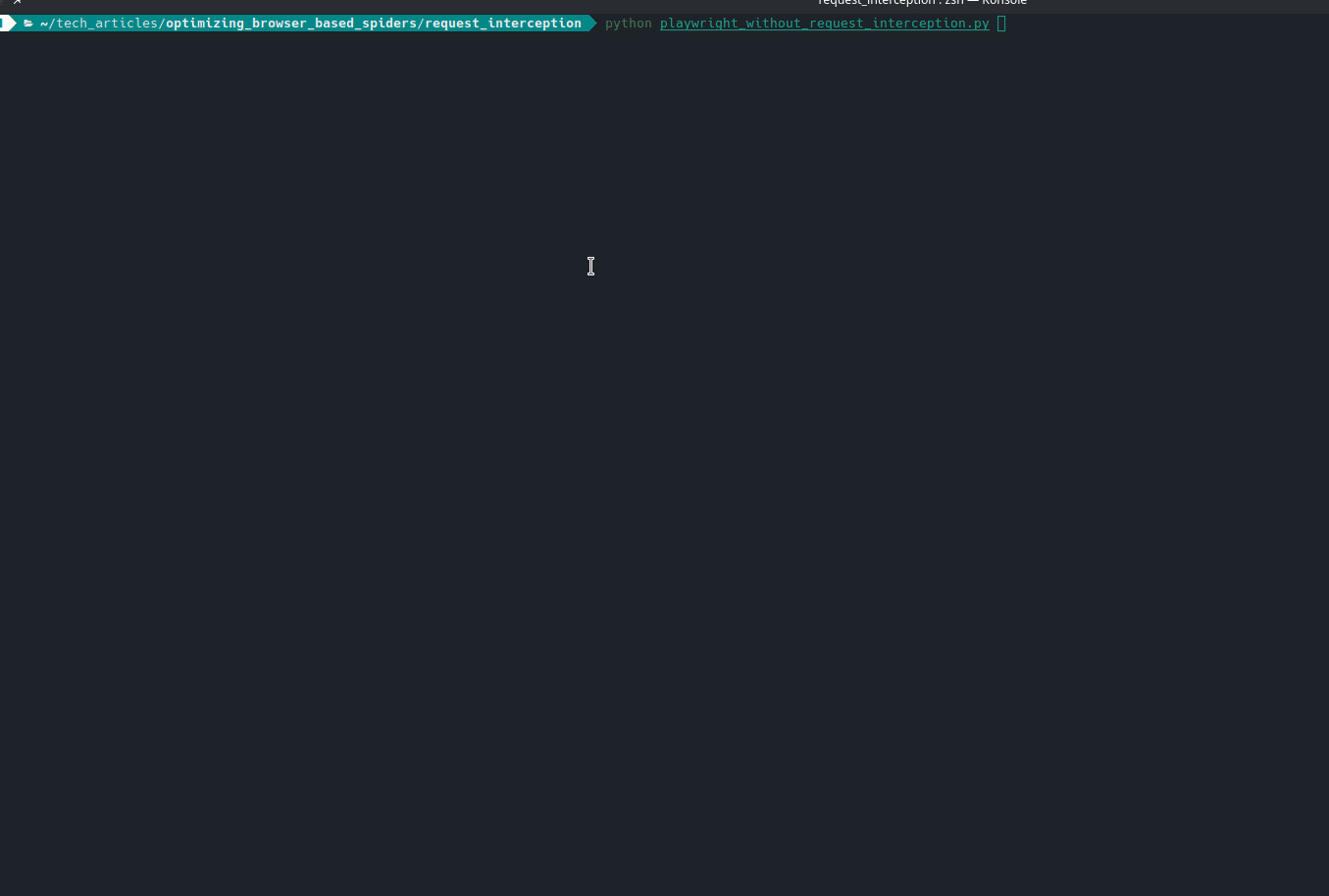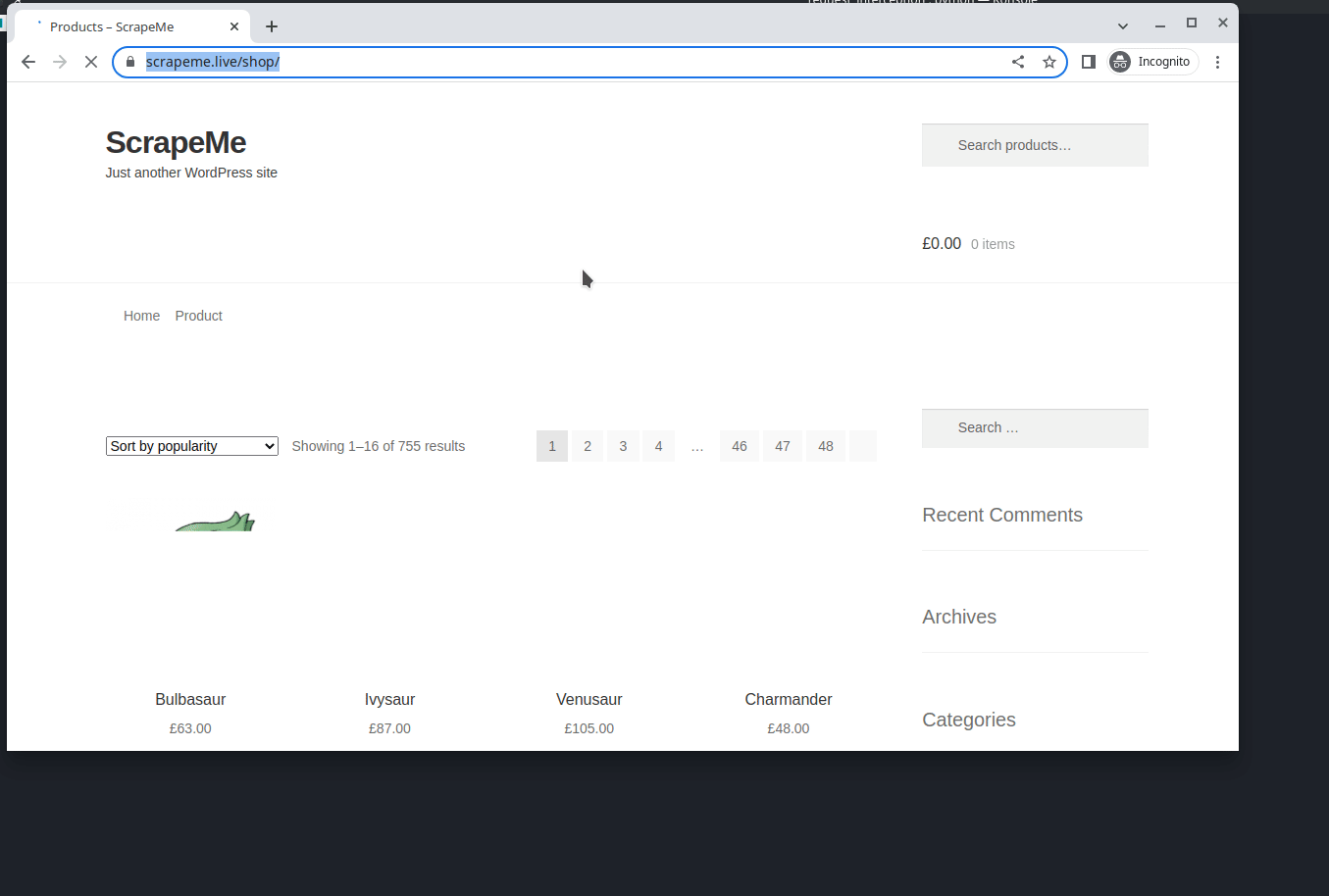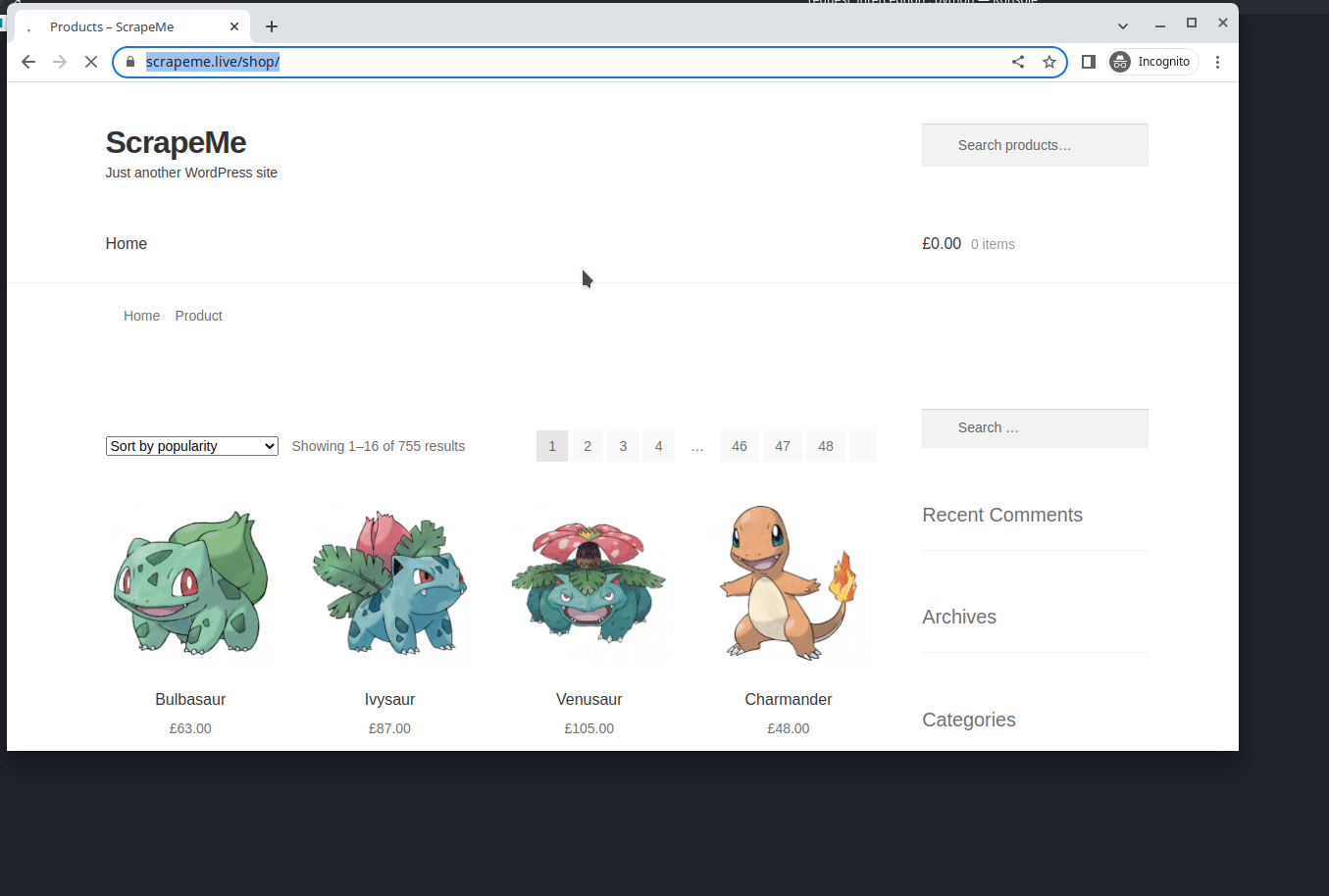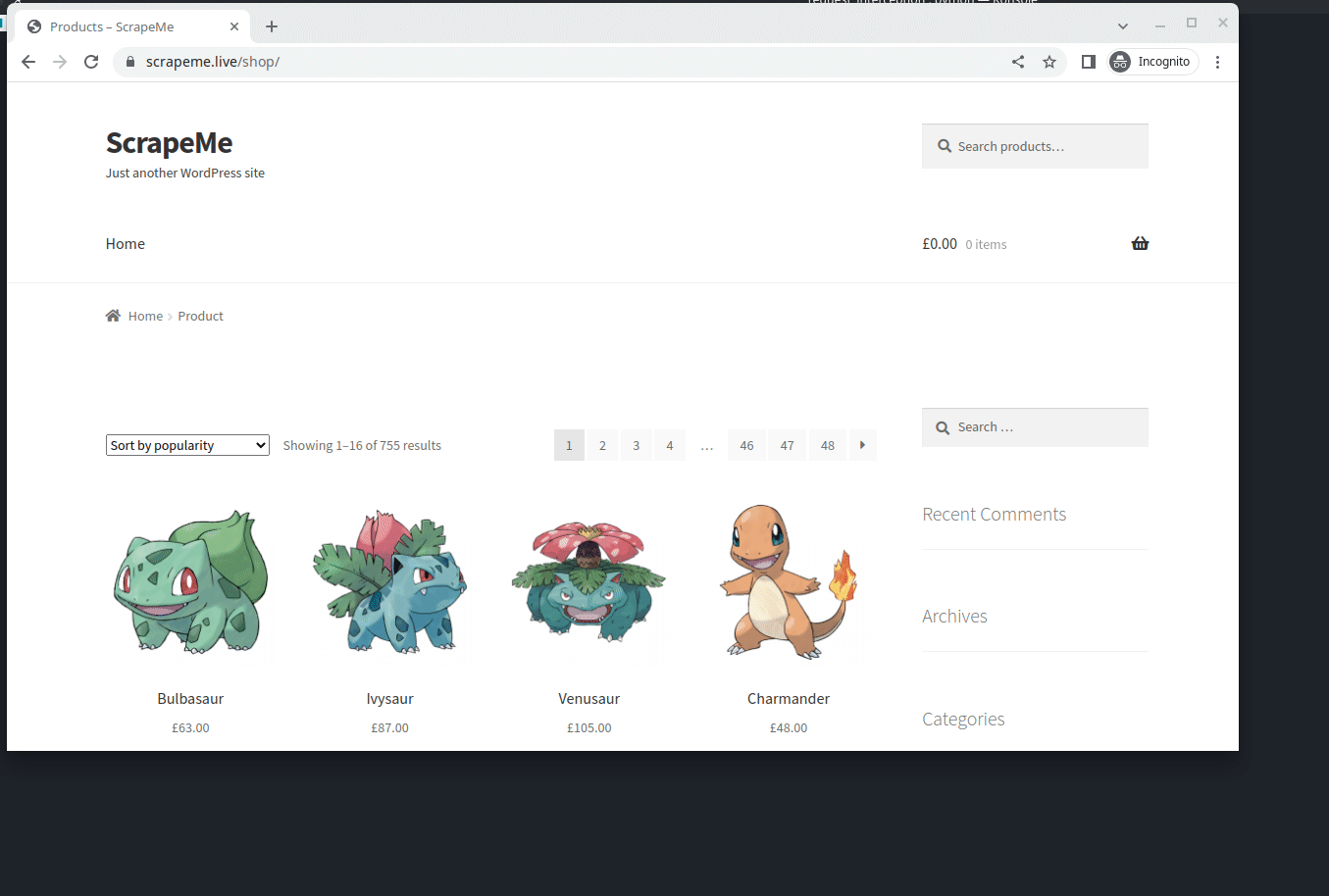
With request interception:
How To Block Requests in Chrome?
You can test whether blocking a certain request may break the page in the browser’s network tab. Open the browser’s network tab and load the webpage.
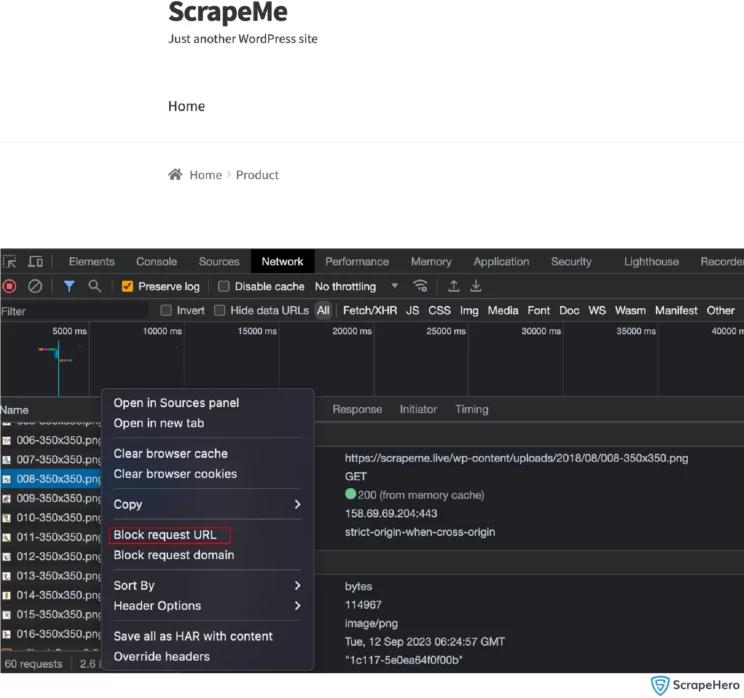
Select the request that you want to intercept and right-click on it. There you can see the option Block request URL(annotated in the above screenshot). Reload the page and ensure the page is still functioning.
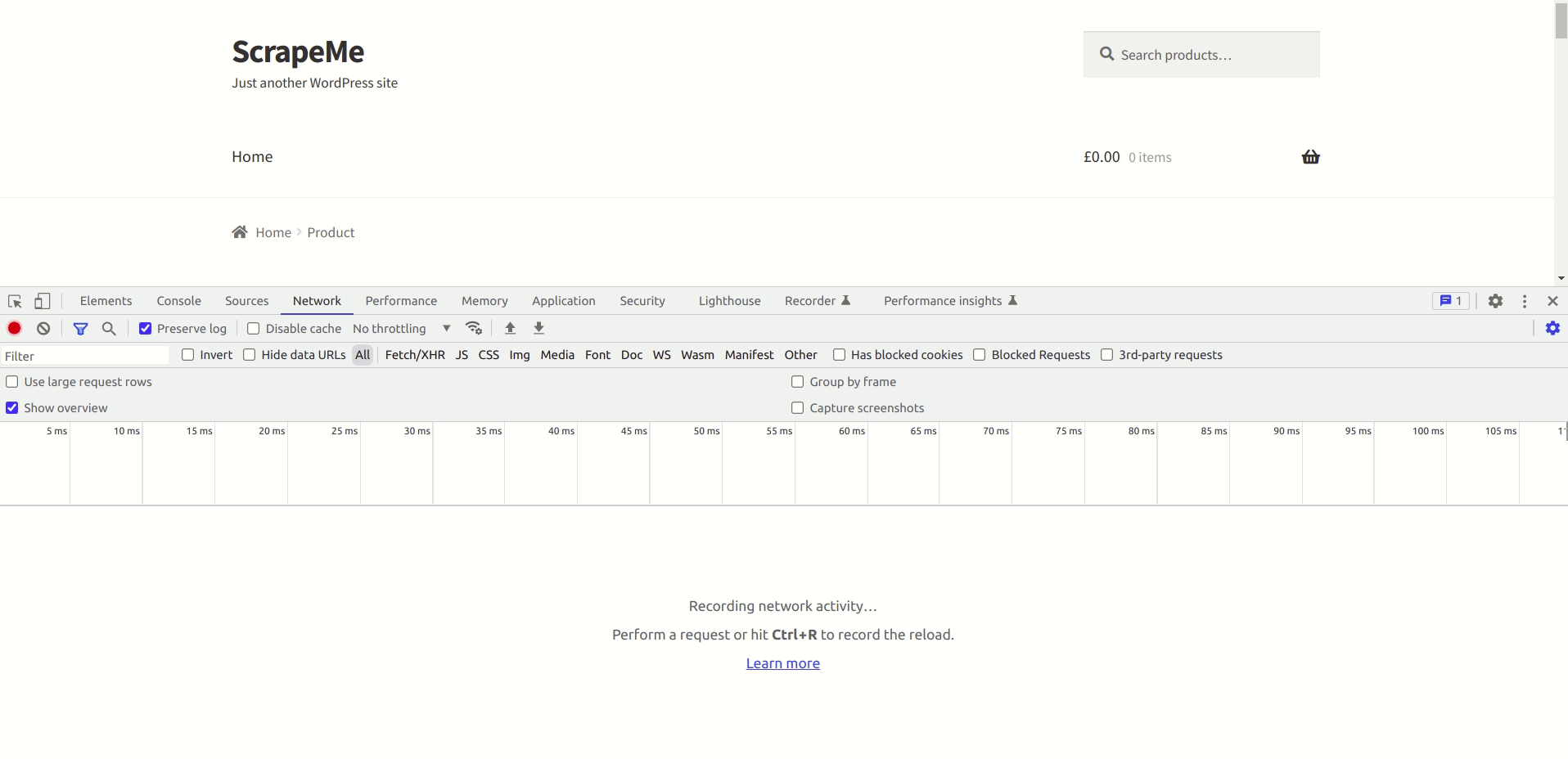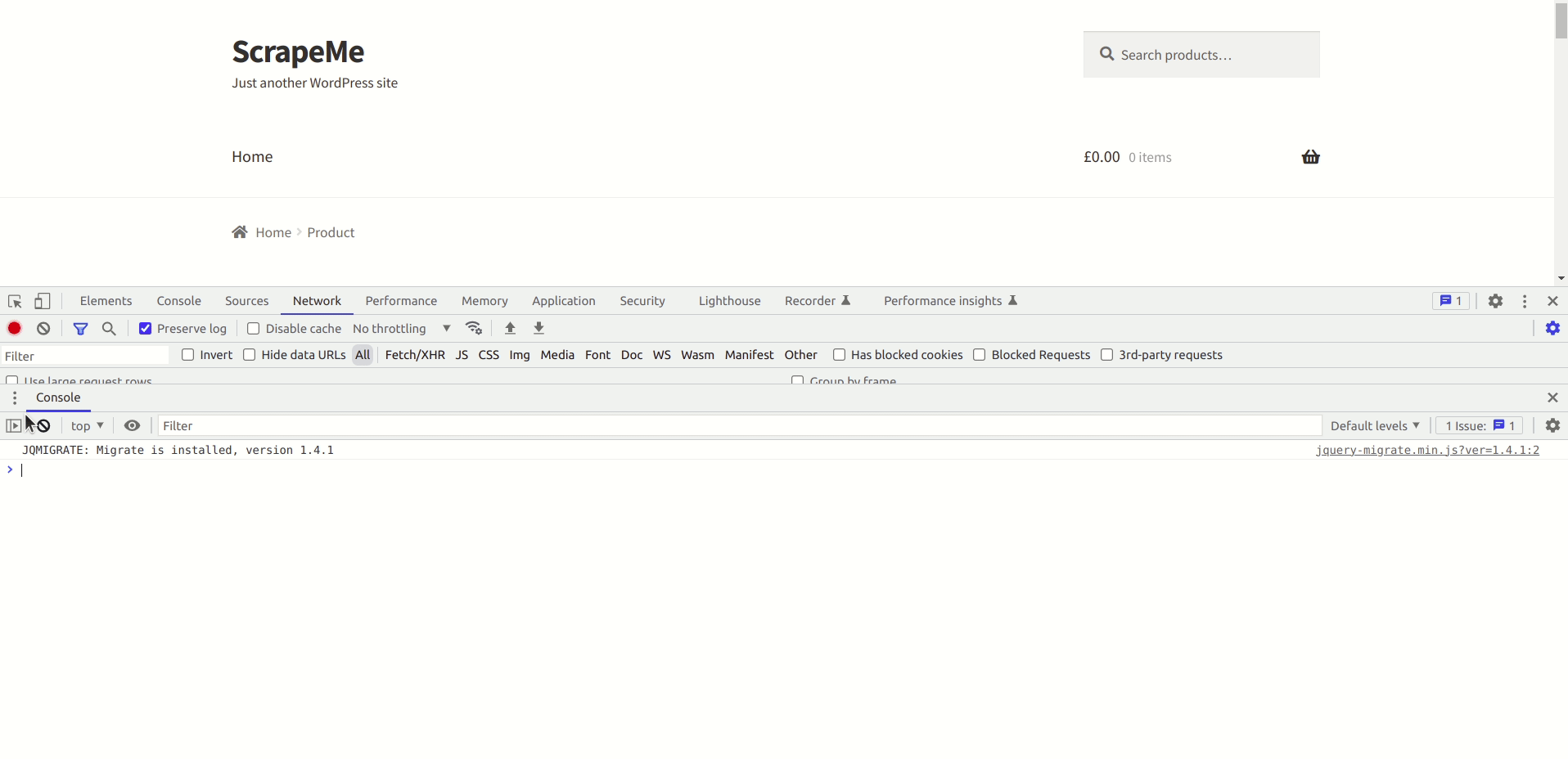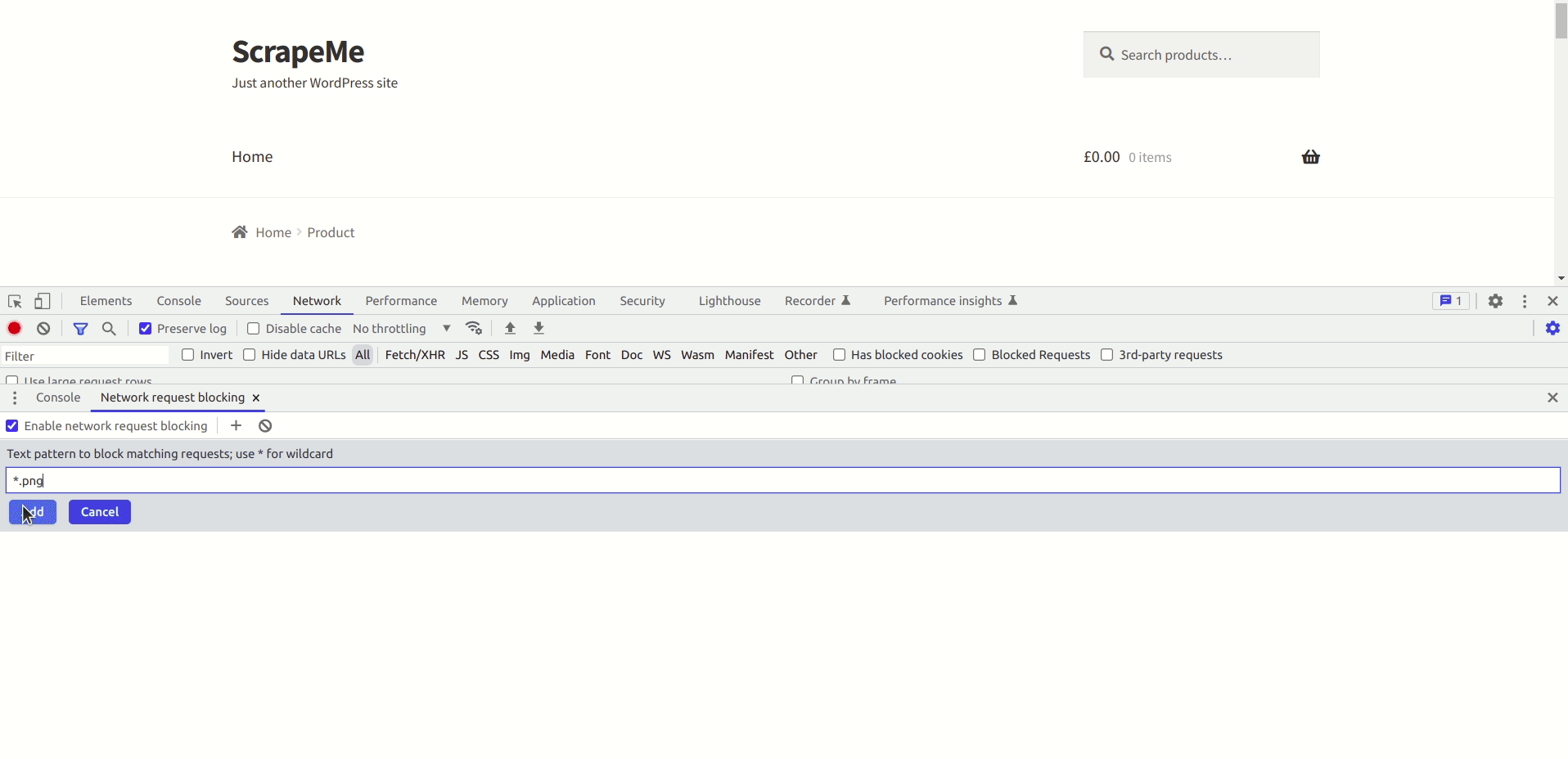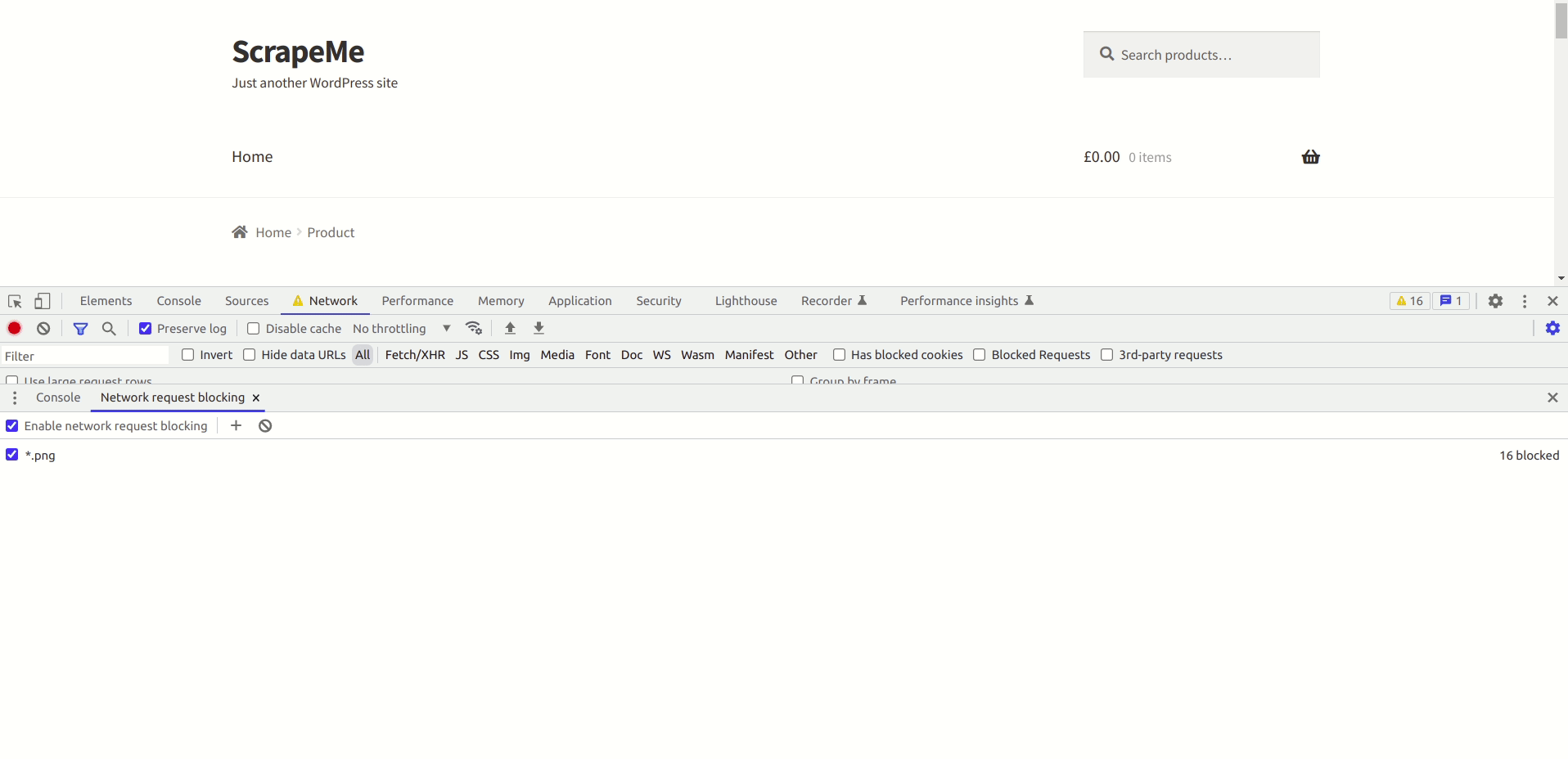
Apart from blocking individual requests, you can intercept requests that follow the same pattern. In the above example, you can see that there are a lot of images. Individually blocking each of them will consume a lot of time. In such cases, you can intercept the requests using pattern matching. The below video will show you how to do this:
Complete Code
Here is the complete code for Python and JavaScript that you can use for your purposes.
Python
import asyncio
from playwright.async_api import Playwright, async_playwright
async def intercept(route, request):
if request.resource_type in {'image', 'script', 'stylesheet', 'font'}:
await route.abort()
else:
await route.continue_()
async def run(playwright: Playwright) -> None:
browser = await playwright.chromium.launch(headless=False)
context = await browser.new_context()
# Open new page
page = await context.new_page()
# adding interception
await page.route('**/*', intercept)
# Go to https://scrapeme.live/shop/
await page.goto("https://scrapeme.live/shop/")
# ---------------------
await context.close()
await browser.close()
async def main() -> None:
async with async_playwright() as playwright:
await run(playwright)
asyncio.run(main())
JavaScript
const { chromium } = require("playwright");
(async () => {
const browser = await chromium.launch({
headless: false,
});
const context = await browser.newContext();
// Open new page
const page = await context.newPage();
await page.route("**/*", (route, request) => {
const unwantedResources = ["image", "script", "stylesheet", "font"];
if (unwantedResources.includes(request.resourceType())) {
route.abort();
} else {
route.continue();
}
});
// Go to https://scrapeme.live/shop/
await page.goto("https://scrapeme.live/shop/");
// ---------------------
await context.close();
await browser.close();
})();
Wrapping Up
Web scraping is a multi-step process that requires time, resources, and money. Loading unnecessary resources while web scraping can be a challenge for the whole process, and it may cost enterprises more.
When unwanted resources are blocked from loading during web scraping you will be able to save both time and money. Such improvements will also speed up your web scraper, increase the number of pages scraped per minute, and decrease proxy bills.
For unmatched data extraction, you can consult a reliable data service provider like ScrapeHero, which can provide you with customized solutions for all your scraping needs.
Frequently Asked Questions
- What is the difference between Puppeteer and Playwright?
There are many differences between Puppeteer and Playwright but the main one is Playwright supports various programming languages like Java, Python, Typescript, JavaScript, and C# while Puppeteer works only with JavaScript. - Does Playwright use real browsers?
Yes, Playwright uses real browsers, such as Chromium, Firefox, and WebKit, for automation. The real-browser environment can give a more accurate depiction of how your scraping code will perform in real-world scenarios. - What are the core concepts of Playwright?
Playwright mainly works on three core concepts: browser, context, and page. Initiating the browser is required for running the tests; using browser contexts, the Playwright framework can achieve parallelization, and it is on the page where every action on the test is performed. - What are the resource types in Playwright?
The main resource types in Playwright include document, stylesheet, image, media, font, script, texttrack, xhr, fetch, eventsource, websocket, and manifest. - What browser capabilities are available in Playwright?
Playwright offers a wide range of browser capabilities, such as multi-browser support, headless and headed modes, device emulation, network interception, geolocation and timezone, input automation, screenshots and screen recording, authentication, cookies and storage, concurrency, and JavaScript execution. - How to block requests in Chrome?
If you are a developer, you could block requests in Chrome by using Chrome DevTools, browser extensions, or JavaScript. If you are an end-user, then options include browser extensions, firewalls, or network-level blocking.


