
Most of us build scrapers using browser automation frameworks, if the website we are trying to scrape is built heavily using modern javascript frameworks, or if the anti scraping services used by the website blocks any requests that is not made from a real browser.
You can build and run web scrapers with browsers quickly using any of the browser automation frameworks like Playwright, Puppeteer or Selenium by automating some clicks and parsing the data to extract what you need.
One of the biggest disadvantages of web scraping with browsers is that they are expensive to run on a large scale due the amount of compute and bandwidth required.
In this article we’ll discuss a few techniques that can be used to create an efficient browser-based scraper. We will use the Playwright framework on Python as an example in this article. Most of these techniques can be used for the other frameworks too.
Learn more about web scraping using Playwright: Web Scraping using Playwright in Python and Javascript
Use headless mode or a headless browser
Browser based web scrapers consume a lot of memory. You can use a headless browser, or just enable the headless mode of a browser automation framework like Playwright to reduce the memory usage.
What is a headless browser?
A browser without a user interface (head) is called a headless browser. It can render websites like any other standard browser. They are better, less time-consuming, and faster. Since the headless browser does not have a UI, it has minimal overhead and can be used for tasks like web scraping and automation.
We recommend using a full fledged browser when building a web scraper using a browser automation framework. But while scaling and running the scrapers, you could switch to headless mode.
In the playwright framework, when you launch a browser, it is headless by default. You can turn it off by setting the headless argument as False.
browser = playwright.chromium.launch(headless=False)
A word of caution – Some anti scraping services checks for presence of a headless browser or a headless flag to detect and block scrapers.
Avoid launching a new browser context for each page
A browser-based scraper needs a browser and a browser context. Launching a browser and creating a new context for each page is expensive and time-consuming. However, we can reuse the browser and context for multiple pages, which reduces the time delay between closing and creating a new context.
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
# Open new page
page_1 = context.new_page()
# Go to https://scrapeme.live/shop/
page_1.goto("https://scrapeme.live/shop/")
# Open new page
page_2 = context.new_page()
# Go to https://scrapeme.live/shop/
page_2.goto("https://scrapeme.live/shop/page/2/")
context.close()
browser.close()
Reduce network bandwidth usage by using request interception
When a web page is rendered on a browser, it creates a chain of requests for all the required external resources. See the number of requests made to render https://scrapeme.live/shop
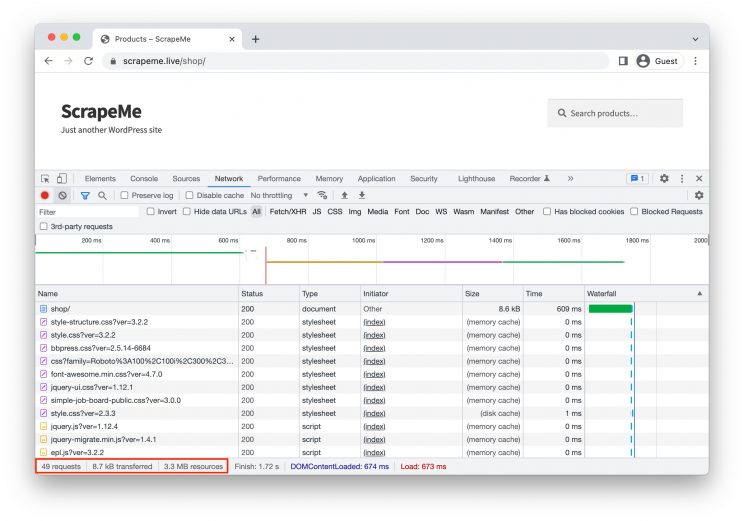
You can see that 49 requests were made to render a single web page and consumed about 3.3 MB of bandwidth. When scraping thousands of pages the number of requests made and the bandwidth consumed adds up a huge number, increasing our costs.
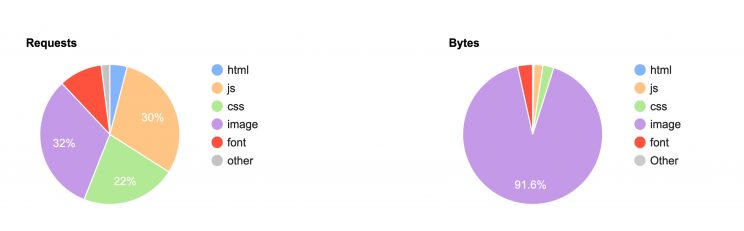
If we look into the content types of resources that are being fetched, we can see that 32% of the requests are images, and 22% are CSS files and 10% Fonts. 91% of the bandwidth used is for images. For many web scraping related use cases these resources are not required to get the data we are trying to collect. We could save a lot of bandwidth and thus time, by not downloading these external resources.
We can intercept these requests and block the requests we think are not necessary to render the page with the data we are trying to scrape.
You can also block javascript requests, API requests, and third-party domain requests, but it may break the webpage or prevent it from displaying data. You need to be very careful while deciding which requests to block.
For a full tutorial and example code on intercepting requests in Playwright, please follow
Profiling and optimizing the code
By profiling your code, you can identify key areas of your scraper that require optimization. You can use various profiling tools such as Pyinstrument to check how much time each line in the scraper takes to complete.
For example, your code might be waiting for an event or sleep to ensure that the webpage has loaded completely. In Playwright, all navigation function calls, including page.goto, page.reload, page.click, etc. waits for the navigation to complete by default. Any additional waits added are redundant and can be removed.
The optimization part requires you to spend a lot of time experimenting with various approaches. The time invested in optimizing might be worth it if it is a large scrape.
Learn More about optimizing your existing web scrapers that use browsers
How to optimize your Playwright web scrapers using code profiling
How To Optimize Playwright Web Scrapers Using Code Profiling Tools
Adopting a hybrid approach if possible
For certain situations, you could adopt a hybrid approach by using a browser, only for those pages that wouldn’t work without a full fledged browser and use a normal requests based (non browser based) web scraper for the other pages.
If your use case supports such an apporach, you can save lot of bandwidth and compute costs when scraping a large number of pages.


