
Yellow Pages is a website listing details, reviews, and business ratings. The data will be helpful for market research; you can understand what your business lacks and close the gaps. Web scraping Yellow Pages is one way to get this data.
This tutorial will show you how to scrape Yellow Pages using Python lxml and requests.
Data scraped from Yellow Pages
Let’s learn how to scrape data from Yellow Pages online by extracting these data points from its search results page.
- Business_name
- Telephone
- Business_page
- Rank
- Category
- Website
- Rating
- Street
- Locality
- Region
- Zip code
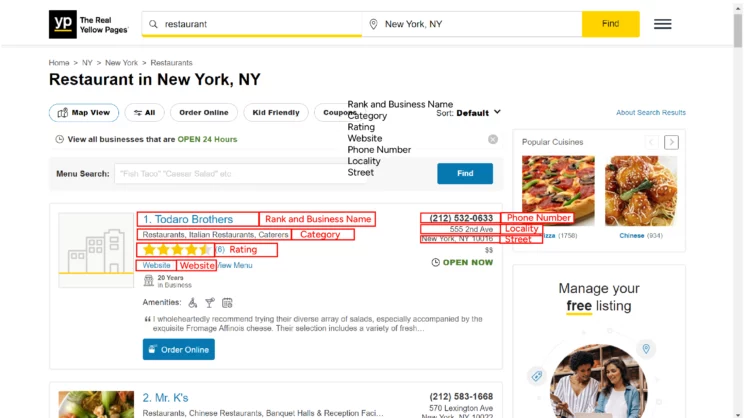 Everything else appears on the web page except for the business page link. The business page link is inside the href attribute of the anchor tag containing the business name. You can right-click on each data point and click inspect to get the code behind it, allowing you to build an XPath for it.
Everything else appears on the web page except for the business page link. The business page link is inside the href attribute of the anchor tag containing the business name. You can right-click on each data point and click inspect to get the code behind it, allowing you to build an XPath for it. 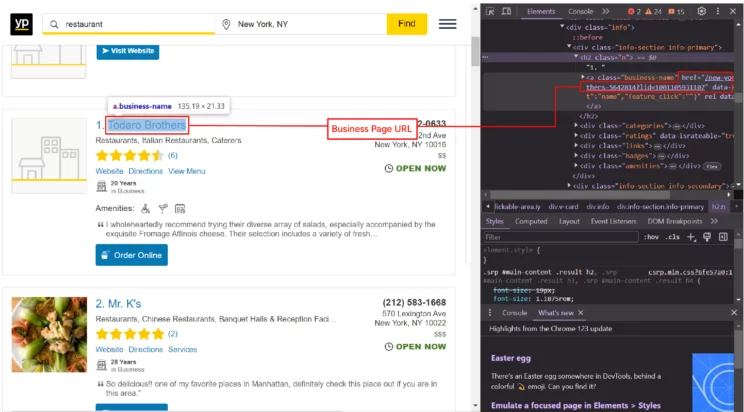
Set Up the Environment for Web Scraping Yellow Pages
Install Python requests and lxml with pip.
pip install lxml requestsThis tutorial writes the extracted data to a CSV file using the unicodecsv package; again, use pip to install the package.
pip install unicodecsvThe Code for Web Scraping Yellow Pages
This script showing how to scrape Yellow Pages contains three parts:
- Import the packages
- Define a function to extract data
- Call the function
Import Packages
In addition to the packages mentioned above, the tutorial also uses argparse to accept arguments from the command line. Therefore, import a total of four packages.
import requests
from lxml import html
import unicodecsv as csv
import argparseDefine a Function to Extract Data
It is better to define a separate function, parse_listing(), to scrape data from the search results page, which you can call inside a loop.
def parse_listing(keyword, place):The function accepts two arguments and returns the scraped data as an object. The arguments are a search keyword and a place. So, the first step is to build the URL for the search results page using these arguments.
url = "https://www.yellowpages.com/search?search_terms={0}&geo_location_terms={1}".format(keyword, place)Next, make an HTTP request; use the essential HTTP headers to bypass the anti-scraping measures while making the request.
headers = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'en-GB,en;q=0.9,en-US;q=0.8,ml;q=0.7',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Host': 'www.yellowpages.com',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36'
}
response = requests.get(url, verify=False, headers=headers)
The response will contain the source code of the search results page. Pass that code to the html.fromstring() method to parse it using lxml.
parser = html.fromstring(response.text)The links inside the HTML may not be absolute. To make them absolute, use the make_links_absolute() method.
base_url = "https://www.yellowpages.com"
parser.make_links_absolute(base_url)Analyzing the source code using inspect shows the details of each business in a div with the class v-card. Get these div elements using the xpath() method of lxml.
XPATH_LISTINGS = "//div[@class='search-results organic']//div[@class='v-card']"
lstings = parser.xpath(XPATH_LISTINGS)Now, iterate through each extracted div element to find the required details.
for results in listings:It is better to store the XPaths in a separate variable as it will be easier to update in the future.
XPATH_BUSINESS_NAME = ".//a[@class='business-name']//text()"
XPATH_BUSSINESS_PAGE = ".//a[@class='business-name']//@href"
XPATH_TELEPHONE = ".//div[@class='phones phone primary']//text()"
XPATH_STREET = ".//div[@class='street-address']//text()"
XPATH_LOCALITY = ".//div[@class='locality']//text()"
XPATH_RANK = ".//div[@class='info']//h2[@class='n']/text()"
XPATH_CATEGORIES = ".//div[@class='info']//div[contains(@class,'info-section')]//div[@class='categories']//text()"
XPATH_WEBSITE = ".//div[@class='info']//div[contains(@class,'info-section')]//div[@class='links']//a[contains(@class,'website')]/@href"
XPATH_RATING = ".//div[contains(@class,'result-rating')]/@class"Use the XPath variables to extract the required details.
raw_business_name = results.xpath(XPATH_BUSINESS_NAME)
raw_business_telephone = results.xpath(XPATH_TELEPHONE)
raw_business_page = results.xpath(XPATH_BUSSINESS_PAGE)
raw_categories = results.xpath(XPATH_CATEGORIES)
raw_website = results.xpath(XPATH_WEBSITE)
raw_rating = results.xpath(XPATH_RATING)[0] if results.xpath(XPATH_RATING) else None
raw_street = results.xpath(XPATH_STREET)
raw_locality = results.xpath(XPATH_LOCALITY)
raw_rank = results.xpath(XPATH_RANK)The extracted data may have some inconsistencies. Therefore, clean them. The method to clean each data point depends on the data type. For example, a string requires a cleaning procedure different from a list.
business_name = ''.join(raw_business_name).strip() if raw_business_name else None
telephone = ''.join(raw_business_telephone).strip() if raw_business_telephone else None
business_page = ''.join(raw_business_page).strip() if raw_business_page else None
rank = ''.join(raw_rank).replace('.\xa0', '') if raw_rank else None
category = ','.join(raw_categories).strip() if raw_categories else None
website = ''.join(raw_website).strip() if raw_website else None
rating =''
wordToNumb = {'one':'1','two':'2','three':'3','four':'4','five':'5','half':'.5'}
if raw_rating:
for digit in raw_rating.split()[1:]:
rating = rating+str(wordToNumb[digit])
street = ''.join(raw_street).strip() if raw_street else None
locality = ''.join(raw_locality).replace(',\xa0', '').strip() if raw_locality else None
locality, locality_parts = locality.split(',')
_, region, zipcode = locality_parts.split(' ')Finally, save the extracted data from each website to a dict element and append it to an array. Now, you only have to call this function with the place and the search keyword as arguments.
business_details = {
'business_name': business_name if business_name else "Not Available",
'telephone': telephone if telephone else "Not Available",
‘business_page': business_page if business_page else "Not Available",
'rank': rank if rank else "Not Available",
'category': category if category else "Not Available",
'website': website if website else "Not Available",
'rating': rating if rating else "Not Available",
'street': street if street else "Not Available",
'locality': locality if locality else "Not Available",
'region': region if region else "Not Available",
'zipcode': zipcode if zipcode else "Not Available",
}
scraped_results.append(business_details)Call the Function
Use the argparse module to make the script accept the arguments from the command line during execution.
argparser = argparse.ArgumentParser()
argparser.add_argument('keyword', help='Search Keyword')
argparser.add_argument('place', help='Place Name')
args = argparser.parse_args()
keyword = args.keyword
place = args.placeCall parse_listings() with the arguments and save the returned data to scraped_data.
scraped_data = parse_listing(keyword, place)Iterate through scraped_data and write the details to a CSV file.
if scraped_data:
print("Writing scraped data to %s-%s-yellowpages-scraped-data.csv" % (keyword, place))
with open('%s-%s-yellowpages-scraped-data.csv' % (keyword, place), 'wb') as csvfile:
fieldnames = ['rank', 'business_name', 'telephone', 'business_page', 'category', 'website', 'rating',
'street', 'locality', 'region', 'zipcode']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames, quoting=csv.QUOTE_ALL)
writer.writeheader()
for data in scraped_data:
writer.writerow(data)Here is the complete code to extract business listings from Yellow Pages
import requests
from lxml import html
import unicodecsv as csv
import argparse
def parse_listing(keyword, place):
"""
Function to process yellowpage listing page
: param keyword: search query
: param place : place name
"""
url = "https://www.yellowpages.com/search?search_terms={0}&geo_location_terms={1}".format(keyword, place)
print("retrieving ", url)
headers = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'en-GB,en;q=0.9,en-US;q=0.8,ml;q=0.7',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Host': 'www.yellowpages.com',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36'
}
# Adding retries
for retry in range(10):
try:
response = requests.get(url, verify=False, headers=headers)
print("parsing page")
if response.status_code == 200:
parser = html.fromstring(response.text)
# making links absolute
base_url = "https://www.yellowpages.com"
parser.make_links_absolute(base_url)
XPATH_LISTINGS = "//div[@class='search-results organic']//div[@class='v-card']"
listings = parser.xpath(XPATH_LISTINGS)
scraped_results = []
for results in listings:
XPATH_BUSINESS_NAME = ".//a[@class='business-name']//text()"
XPATH_BUSSINESS_PAGE = ".//a[@class='business-name']//@href"
XPATH_TELEPHONE = ".//div[@class='phones phone primary']//text()"
XPATH_STREET = ".//div[@class='street-address']//text()"
XPATH_LOCALITY = ".//div[@class='locality']//text()"
XPATH_RANK = ".//div[@class='info']//h2[@class='n']/text()"
XPATH_CATEGORIES = ".//div[@class='info']//div[contains(@class,'info-section')]//div[@class='categories']//text()"
XPATH_WEBSITE = ".//div[@class='info']//div[contains(@class,'info-section')]//div[@class='links']//a[contains(@class,'website')]/@href"
XPATH_RATING = ".//div[contains(@class,'result-rating')]/@class"
raw_business_name = results.xpath(XPATH_BUSINESS_NAME)
raw_business_telephone = results.xpath(XPATH_TELEPHONE)
raw_business_page = results.xpath(XPATH_BUSSINESS_PAGE)
raw_categories = results.xpath(XPATH_CATEGORIES)
raw_website = results.xpath(XPATH_WEBSITE)
raw_rating = results.xpath(XPATH_RATING)[0] if results.xpath(XPATH_RATING) else None
raw_street = results.xpath(XPATH_STREET)
raw_locality = results.xpath(XPATH_LOCALITY)
raw_rank = results.xpath(XPATH_RANK)
business_name = ''.join(raw_business_name).strip() if raw_business_name else None
telephone = ''.join(raw_business_telephone).strip() if raw_business_telephone else None
business_page = ''.join(raw_business_page).strip() if raw_business_page else None
rank = ''.join(raw_rank).replace('.\xa0', '') if raw_rank else None
category = ','.join(raw_categories).strip() if raw_categories else None
website = ''.join(raw_website).strip() if raw_website else None
rating =''
wordToNumb = {'one':'1','two':'2','three':'3','four':'4','five':'5','half':'.5'}
if raw_rating:
for digit in raw_rating.split()[1:]:
rating = rating+str(wordToNumb[digit])
print(rating)
street = ''.join(raw_street).strip() if raw_street else None
locality = ''.join(raw_locality).replace(',\xa0', '').strip() if raw_locality else None
locality, locality_parts = locality.split(',')
_, region, zipcode = locality_parts.split(' ')
business_details = {
'business_name': business_name if business_name else "Not Available",
'telephone': telephone if telephone else "Not Available",
'business_page': business_page if business_page else "Not Available",
'rank': rank if rank else "Not Available",
'category': category if category else "Not Available",
'website': website if website else "Not Available",
'rating': rating if rating else "Not Available",
'street': street if street else "Not Available",
'locality': locality if locality else "Not Available",
'region': region if region else "Not Available",
'zipcode': zipcode if zipcode else "Not Available",
}
scraped_results.append(business_details)
return scraped_results
elif response.status_code == 404:
print("Could not find a location matching", place)
# no need to retry for non existing page
break
else:
print("1")
print("Failed to process page")
return []
except Exception as e:
print(e)
print("Failed to process page")
return []
if __name__ == "__main__":
argparser = argparse.ArgumentParser()
argparser.add_argument('keyword', help='Search Keyword')
argparser.add_argument('place', help='Place Name')
args = argparser.parse_args()
keyword = args.keyword
place = args.place
scraped_data = parse_listing(keyword, place)
if scraped_data:
print("Writing scraped data to %s-%s-yellowpages-scraped-data.csv" % (keyword, place))
with open('%s-%s-yellowpages-scraped-data.csv' % (keyword, place), 'wb') as csvfile:
fieldnames = ['rank', 'business_name', 'telephone', 'business_page', 'category', 'website', 'rating',
'street', 'locality', 'region', 'zipcode']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames, quoting=csv.QUOTE_ALL)
writer.writeheader()
for data in scraped_data:
writer.writerow(data)Here are the business listings scraped from Yellow Pages. 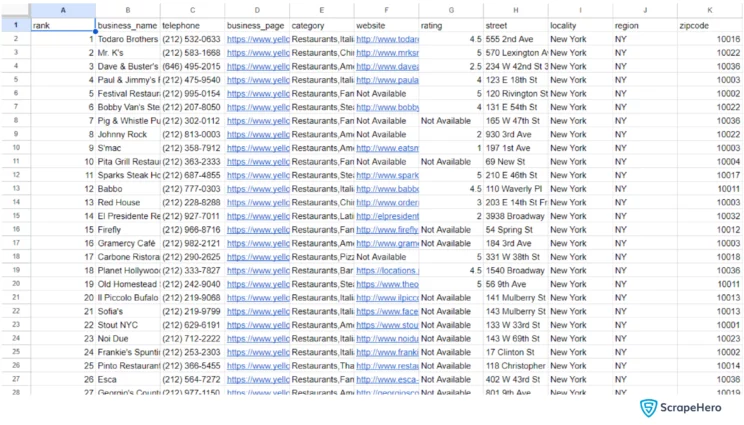
Code Limitations
The code will scrape Yellow Pages using Python lxml unless the anti-scraping measures have increased or the website structure has changed.
Advanced anti-scraping measures may detect your scraper despite the headers; a different IP address via a proxy is the only option. You might have to change the proxy routinely; this is proxy rotation.
If they change the website’s structure, you may have to reanalyze the HTML code and figure out the new XPaths.
ScrapeHero Yellow Pages Scraper: An Alternative
Use ScrapeHero Yellow Pages Scraper from ScrapeHero Cloud as an alternative to building a web scraper yourself. It is a pre-built no-code web scraper. The scraper lets you extract Yellow Pages data for free with a few clicks. You can avoid
- Managing legalities
- Worrying about anti-scraping measures
- Monitoring the website structure
In short, the web scraper will save you a lot of time. To use the scraper
- Head to ScrapeHero Cloud
- Create an account
- Select and add the Yellow Pages Crawler
- Provide a URL
- Specify the number of pages
- Click Gather Data.
After a few minutes, you can download the extracted data as a JSON, CSV, or Excel file, or we will upload it to your DropBox, Google Drive, or AWS bucket. You can also schedule the crawler to run periodically.

Wrapping Up
The tutorial showed how to scrape data from Yellow Pages using Python requests and lxml. But, be ready to change the code shown in the tutorial if Yellow Pages changes its structure or employs advanced anti-scraping measures.
However, you can avoid learning how to scrape Yellow Pages altogether by using the ScrapeHero Yellow Pages Scraper.
You can also contact ScrapeHero services for extracting details other than those included in the ScrapeHero Cloud web scraper. ScrapeHero is an enterprise-grade full-service web scraping service provider. We provide services ranging from large-scale web scraping and crawling to custom robotic process automation.
Frequently Asked Questions
Yellow Pages does not provide direct options for exporting the data to Excel. However, you can use the code from this tutorial to scrape data and save it as a CSV file supported by Excel.
A website can detect and block bots using several techniques. Here are some of them:
- Recognizing the browsing patterns: requests from bots are usually not random.
- Measuring the request rate: bots can make more rapid requests than humans.
- Analyzing the user agents: scrapers usually have a different user agent than the regular browser.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



