
Web crawling plays a vital role in navigating the digital landscape. It is often confused with web scraping. Even though both are methods used to collect data, web crawling is a much broader concept.
This article gives you an overview of web crawling with Python, what web crawlers are, how they differ from web scrapers, the types of web crawlers used, some use cases of crawling, and much more.
What Is Web Crawling?
Web crawling is an automated process that collects data from publicly available websites by visiting pages and discovering all the URLs. It indexes web pages using a program or automated script called a web crawler, supports search engine functions, and monitors website health.
What Is a Web Crawler?
As mentioned earlier, automated scripts or programs created to index web pages by systematically browsing the web are called web crawlers. They are also known by multiple names–web spider, spider bot, or simply the short-term crawler. A web crawler copies web pages, allowing search engines to retrieve and index them.
Difference Between Web Crawlers and Web Scrapers
Web crawlers discover and visit URLs systematically, browse the web, and index the content for search engines. On the other hand, web scrapers extract specific data points, such as prices or product descriptions, from web pages. Web crawlers assist in scraping by locating relevant URLs, whereas scrapers extract data from these web pages.
What Are the Different Types of Web Crawlers?
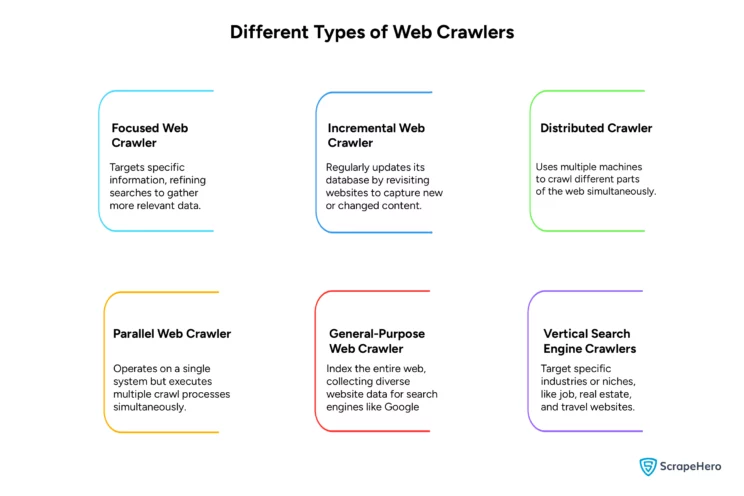
Web crawlers navigate the web and collect data related to specific needs. There are various types of web crawlers classified according to how they operate. Here’s an overview of different kinds of web crawlers:
-
Focused Web Crawlers
These web crawlers are designed to gather specific types of data. They are ideal for niche research, as they collect relevant data by focusing on predefined topics or domains.
-
Incremental Web Crawlers
These web crawlers revisit sites and update their indexes with altered or new content, always ensuring that the data remains current.
-
Distributed Web Crawlers
These web crawlers divide the web into different segments operating on multiple machines. They allow data extraction from various parts, simultaneously enhancing speed and reducing overall crawling time.
-
Parallel Web Crawlers
These web crawlers are similar to distributed crawlers but operate on a single system. To increase efficiency, parallel web crawlers execute many crawl processes at once.
-
General-Purpose Web Crawlers
These web crawlers scan the entire internet and index websites. They make the information accessible through search engines.
-
Vertical Search Engine Crawlers
These web crawlers refine data collection to industry-specific needs and provide targeted search results in sectors like jobs, real estate, or travel.
Other types of web crawlers serve unique purposes. These crawlers include link validation, social media, and image or video crawlers.
How Does a Web Crawler Work?
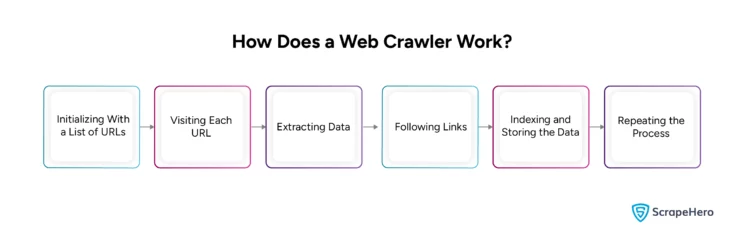
A web crawler operates by automatically visiting and gathering data from websites. The process begins with downloading the site’s robots.txt file, which contains sitemaps listing the URLs the search engine can crawl. Here’s a detailed breakdown of how a web crawler works:
-
Initializing With a List of URLs
The web crawler initiates the process with a list of URLs to visit. This list is generated by using a search engine, following links from other websites, or providing a set of URLs for crawling.
-
Visiting Each URL
The crawler visits each URL on the list by sending an HTTP request to the website’s server.
-
Extracting Data
After accessing the site, the crawler collects data from HTML codes and other resources, such as CSS or JavaScript. This collected data can be text, images, links, metadata, or other information.
-
Following Links
The web crawler follows the links mentioned on the web page and discovers new pages to crawl. This process is repeated for every page until it has visited all the pages in the original list or it reaches a specified limit.
-
Indexing and Storing the Data
The web crawler indexes and stores the data in a database. This is done to retrieve the information and use it for various purposes, such as search engine indexing or research data analysis.
-
Repeating the Process
The process starts again once the web crawler finishes crawling all the URLs in the given list. It can revisit the URLs to check for updates or crawl a new set.
Python Web Crawler – How to Build a Web Crawler in Python
To build a web crawler in Python, you can use libraries such as Requests for HTTP requests and BeautifulSoup for HTML parsing. Below is the step-by-step process for creating a basic Python web crawler.
Step 1: Set Up Your Environment
Install Python and necessary libraries on your system:
pip install requests beautifulsoup4Step 2: Import Libraries
Create a new Python file (e.g., `simple_crawler.py`) and import the required libraries:
import requests
from bs4 import BeautifulSoup
Step 3: Define the Crawler Function
Define a function to process URLs and parse HTML content:
def simple_crawler(url):
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.title.text
print(f'Title: {title}')
else:
print(f'Error: Failed to fetch {url}')
Step 4: Test the Crawler
Test the crawler by providing a URL:
if __name__ == "__main__":
sample_url = 'https://example.com'
simple_crawler(sample_url)
Step 5: Run the Crawler
Execute the script in your terminal:
python simple_crawler.pyYou can extend this crawler to extract more data types.
Scaling Web Crawling With Python–Key Strategies
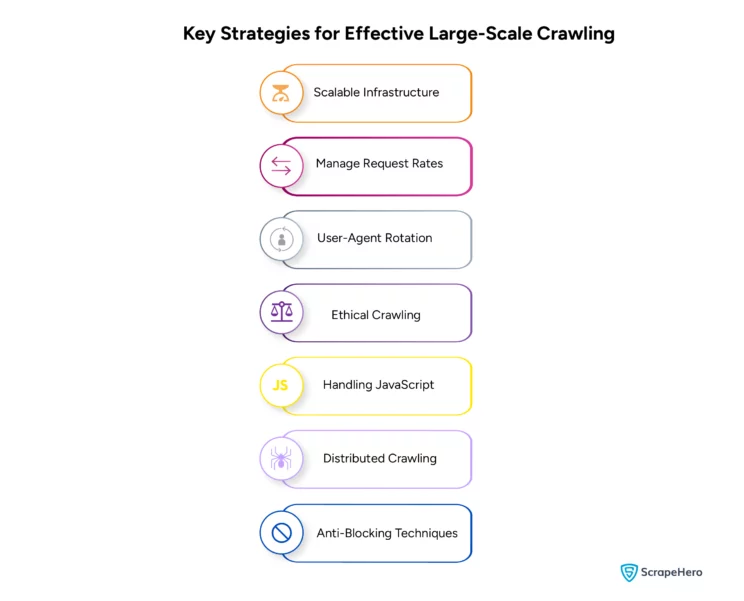
To crawl websites with millions of pages is not an easy task. It requires strategic planning and advanced techniques to crawl the web on a large scale. Mentioned are some strategies for effective large-scale web crawling with Python, minimizing the risk of getting blocked by websites :
-
Scalable Infrastructure
By using services like ScrapeHero, managing the complexities of large-scale web crawling ensures data quality.
-
Manage Request Rates
To reduce the load on the target server, limit the number of concurrent requests, and set delays between requests to mimic human interaction.
-
User-Agent Rotation
To avoid detection by anti-scraping technologies, constantly rotate User-Agents.
-
Ethical Crawling
Respect the `robots.txt` of websites and avoid crawling during peak hours.
-
Handling JavaScript
Utilize tools like Selenium or Puppeteer for sites that render content with JavaScript .
-
Distributed Crawling
Use multiple machines or the cloud to handle extensive crawling
-
Anti-Blocking Techniques
Implement IP rotation and session management to avoid websites blocking them.
Web Crawling With Python Tools
Many open-source web crawling frameworks and tools are available, making discovering links and visiting pages easier. Such tools save time and effort in solving the crawling task and optimizing the website. A few of these frameworks and tools include:
- Apache Nutch
- Heritrix
- StormCrawler
- Crawlee
- NodeCrawler
Web Crawling With Python – Use Cases

Web crawling is employed in several scenarios where there’s a need to focus on navigating and indexing web content rather than extracting specific data. These are some particular use cases where web crawling is involved:
- Link Validation: Web crawlers navigate through hyperlinks to check the validity of website links and ensure they lead to active pages, maintaining website integrity and user experience.
- Website Archiving: Organizations use web crawlers to systematically browse and capture snapshots of web pages, archiving the state of the web at different times.
- SEO Audits: Web crawlers help conduct SEO audits by analyzing site structures, discovering SEO opportunities, and identifying issues like duplicate content or poor link structures.
- Sitemap Generation: Automated tools use web crawling to create or update sitemaps. They visit all web pages on a site and use the URLs found to generate sitemaps.
- Network Security: Web crawlers are used in cybersecurity to map out the network structure of a web domain, identifying vulnerable spots where hackers could enter.
Web Crawling With Python – Best Practices and Considerations
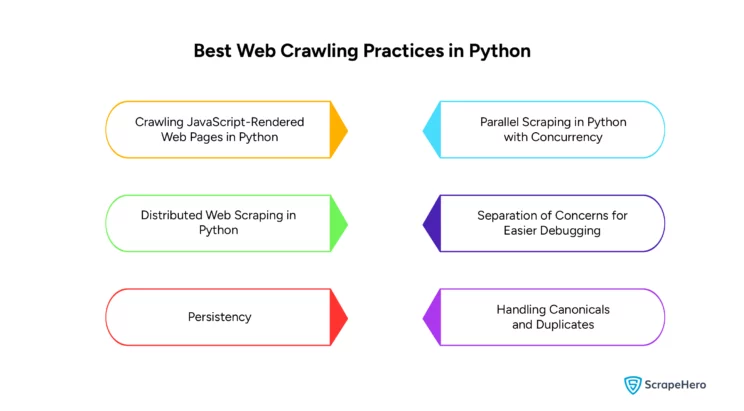
-
Crawling JavaScript-Rendered Web Pages in Python
To extract information from JavaScript-loaded websites, use Python’s Selenium library. It allows control over web browsers to collect data even if they’re built using React.
-
Parallel Scraping in Python with Concurrency
Utilize the `threading` and `queue` modules to manage multiple crawler threads in Python as they improve crawl performance through concurrent processing.
-
Distributed Web Scraping in Python
Integrate with systems like Celery or Redis Queue for scalable and distributed crawling in Python, as they enable the distribution of tasks across multiple servers.
-
Separation of Concerns for Easier Debugging
Divide the crawling process into different functions for HTML retrieval, page crawling, content scraping, etc.
-
Persistency
Store all the URLs, timestamps, and extracted content using databases to handle data persistently.
-
Handling Canonicals and Duplicates
Adjust the URL queue management to skip pages already crawled and respect canonical URLs, thus avoiding redundant content indexing.
Wrapping Up
Web crawlers are essential to indexing website content over the Internet. This indexing helps the search engine find the website and rank it organically. ScrapeHero offers scalable and sophisticated large-scale web crawling solutions that cater to your needs and go beyond essential data extraction.
You can use ScrapeHero Cloud Crawlers, which are ready-made Python web crawlers that can assist you in data-driven decision-making. If you require custom Python web crawlers or API solutions to streamline your business operations, you can use ScrapeHero web scraping services.
Frequently Asked Questions
Yes, Python is used for web crawling. Its libraries, such as Requests and BeautifulSoup, facilitate making HTTP requests and parsing HTML.
Web scraping is the process of extracting specific data from websites, while web crawling is the automated web browsing process of indexing content for search engines.
Web crawlers crawl sites. They systematically browse the web from a list of URLs and follow hyperlinks and index pages.
Web crawlers are not illegal, but using them without permission and violating the website’s terms of service or copyright laws can lead to legal issues.
First, use the Requests library to send an HTTP request to the URL and retrieve its content, and then use BeautifulSoup to parse the HTML and extract information.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data


