
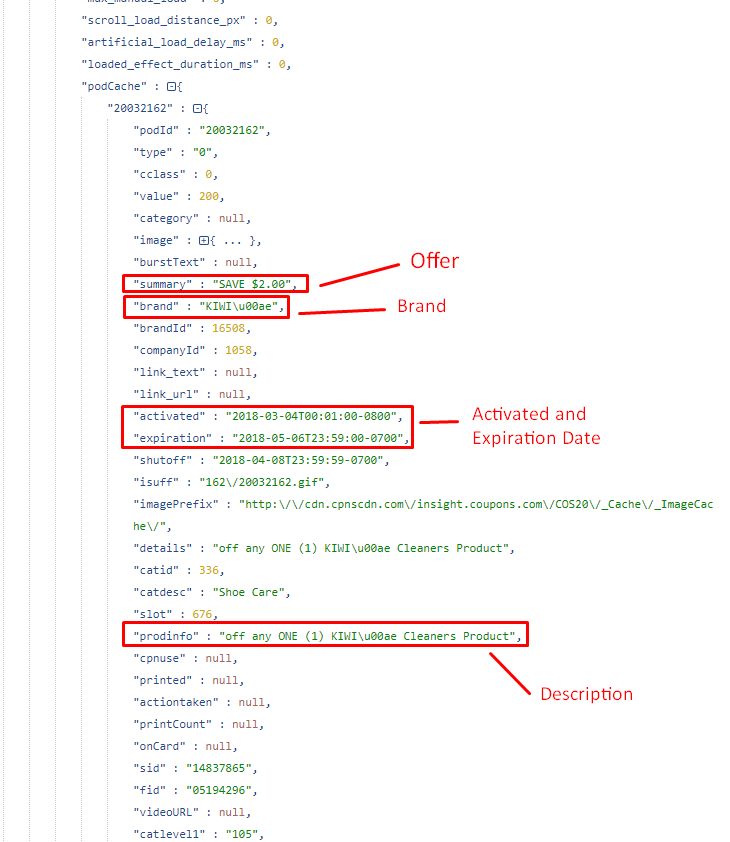
- Discounted Price
- Brand
- Category
- Product Description
- Activated Date
- Expired Date
- URL
Below is an annotated screenshot of the data we will be extracting.
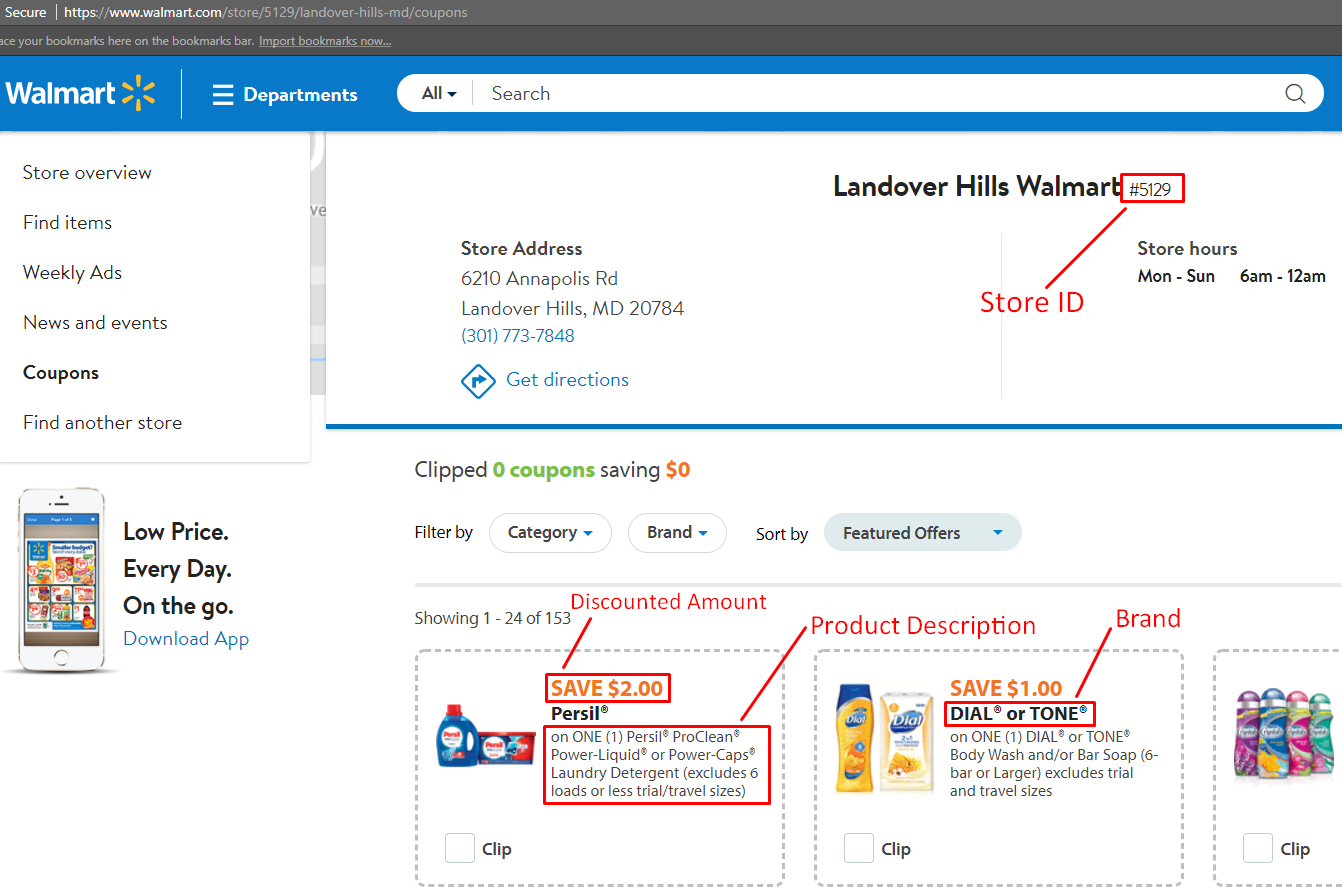
You could go further and scrape the coupons based on filters and brand. But for now, we’ll keep it simple and stick to these.
Finding The Data
Open any browser and select a store URL. We’ll take this one https://www.walmart.com/store/5941/washington-dc. Click on the options Coupons on the left side and you’ll see the list of coupons available for Walmart store 5941. The GIF below shows how the store URL is obtained:
Right-click on any link on the page and choose – Inspect Element. The browser will open a toolbar and show the HTML Content of the Web Page, formatted nicely. Click Clear ![]() on the Network panel to clear all requests from the Request table.
on the Network panel to clear all requests from the Request table.
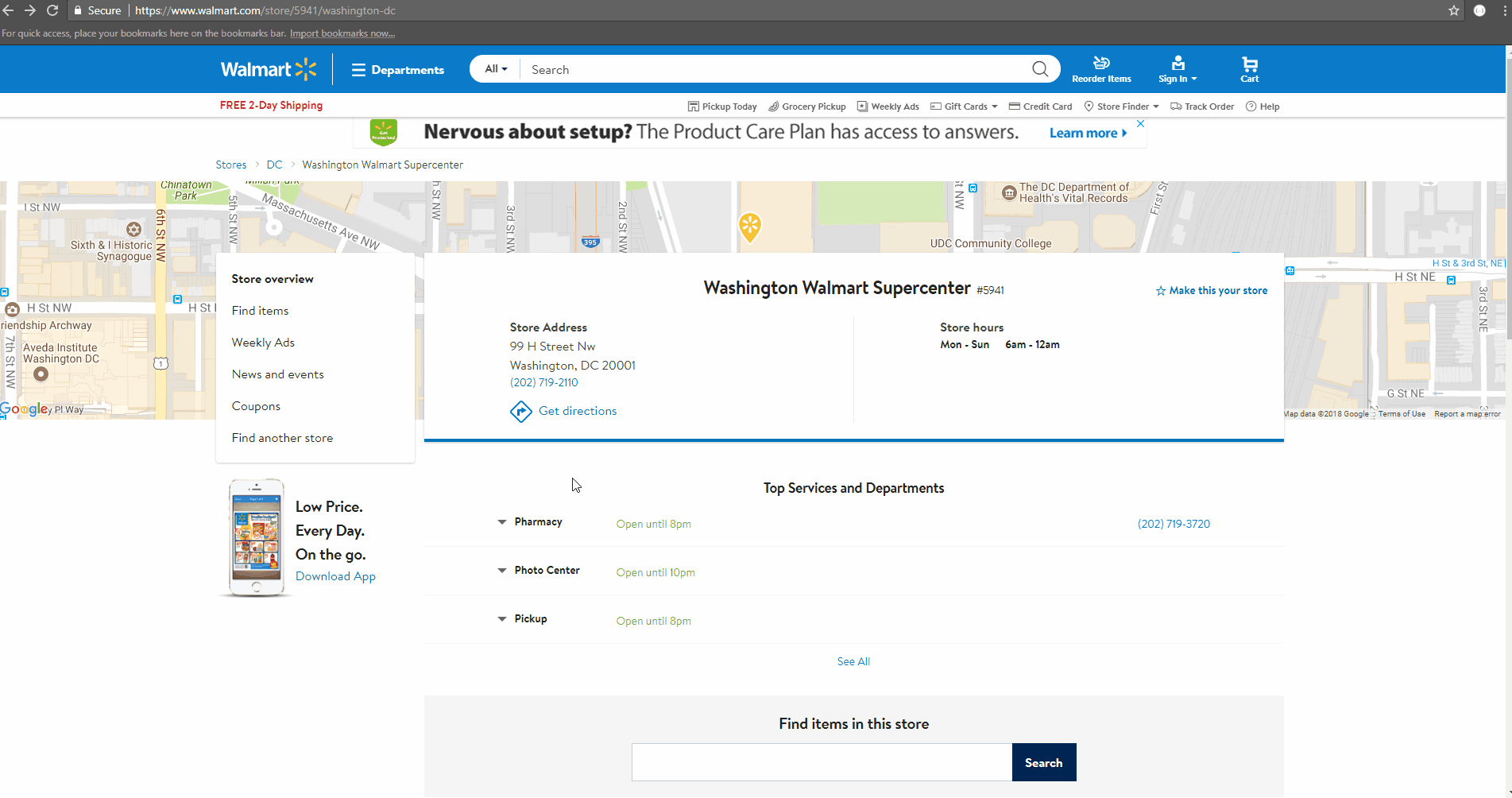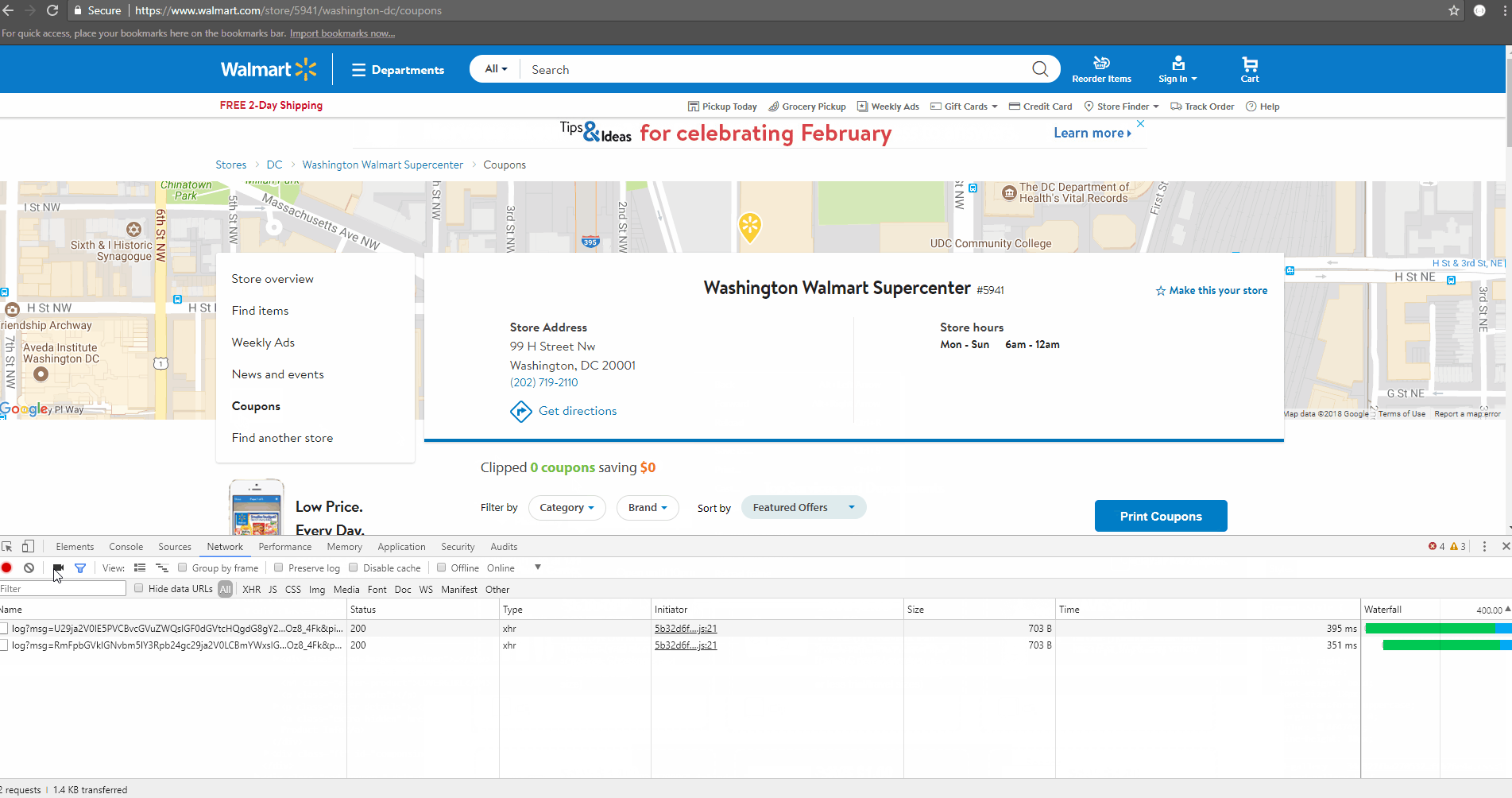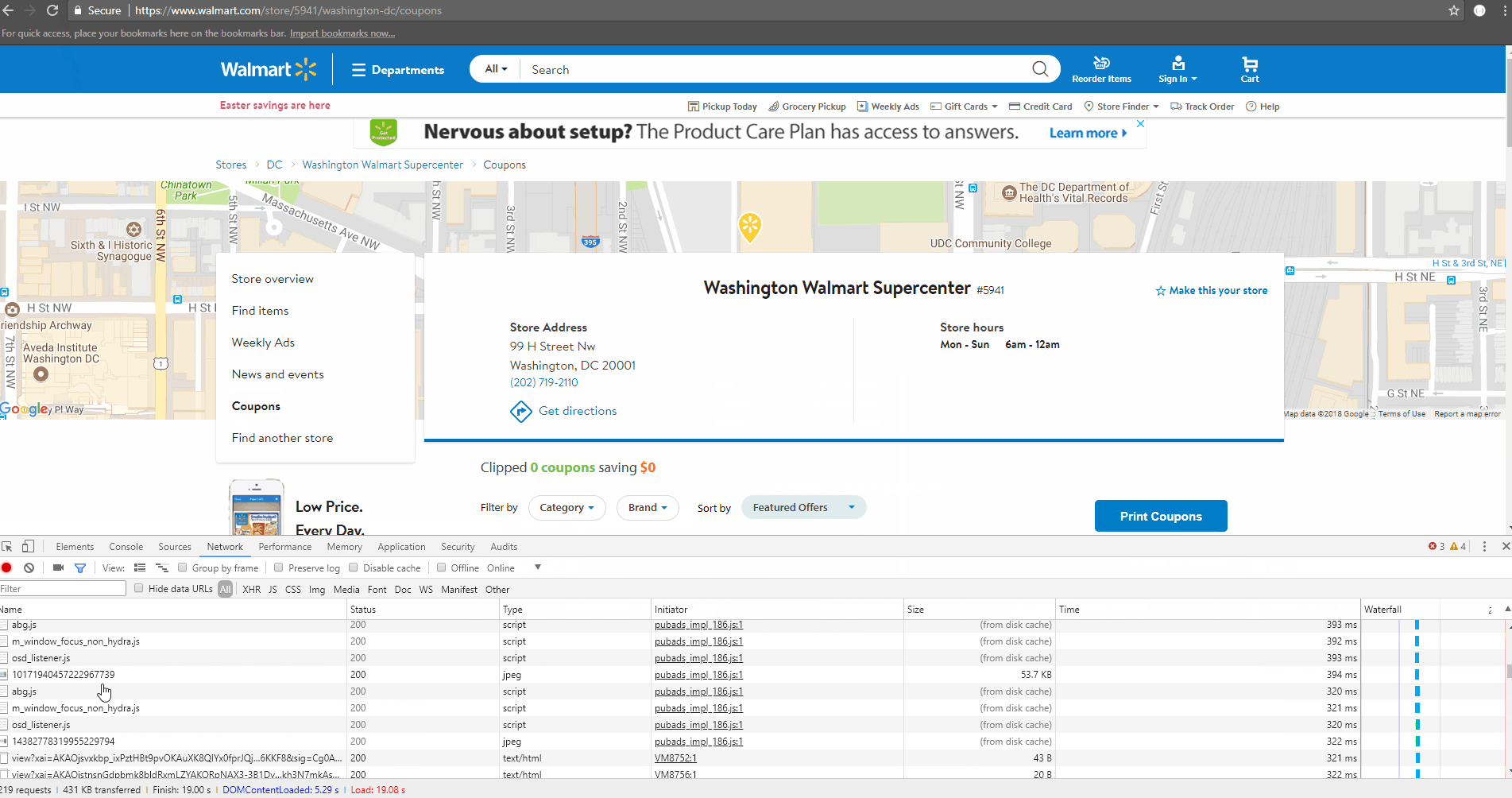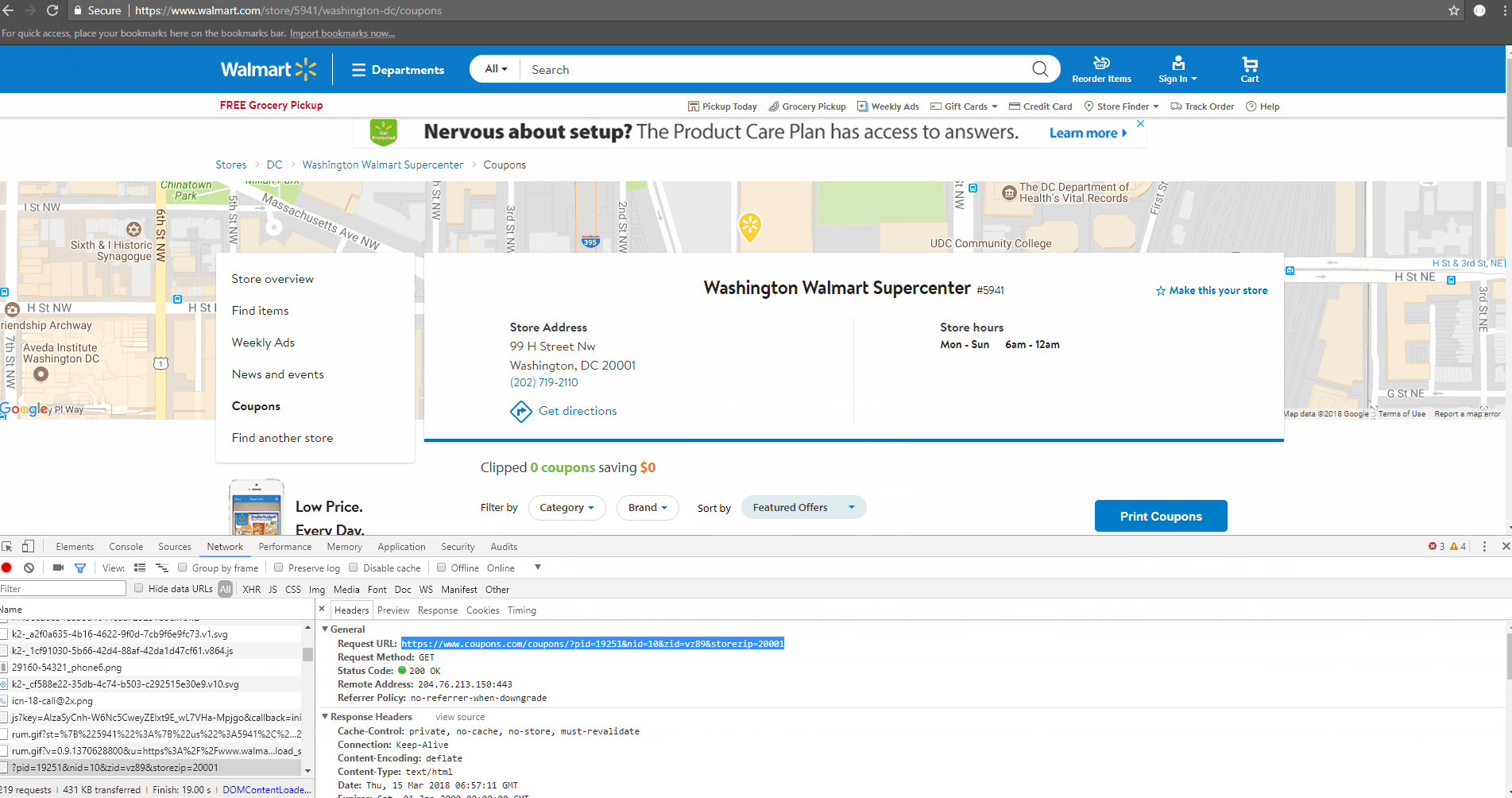
Click on the request – ?pid=19521&nid=10&zid=vz89&storezip=20001
You’ll see the Request URL – https://www.coupons.com/coupons/?pid=19251&nid=10&zid=vz89&storezip=20001
The next step is to identify the get parameters values- pid, nid, and storezip. Check for these variables in the page source of https://www.walmart.com/store/5941/washington-dc
You can see that these variables are assigned to a javascript variable _wml.config. Use regular expressions to filter those variables from the page source and then create a URL for the coupon endpoint – https://www.coupons.com/coupons/?pid=19251&nid=10&zid=vz89&storezip=20001.

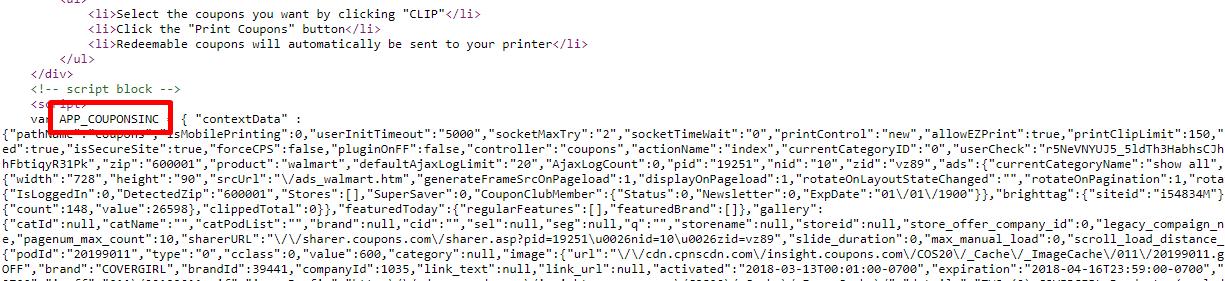
Retrieve the HTML from this coupon URL and you’ll see the data you need to extract within the javascript variable APP_COUPONSINC. Copy the data into a JSON parser to view the data in a structured format.
Read More – Learn to scrape Yelp business data
You can see the data fields for the coupons within each coupon ID.
Building the Scraper
We will use Python 3 for this tutorial. The code will not run if you are using Python 2.7. To start, you need a computer with Python 3 and PIP installed in it.
Most UNIX operating systems like Linux and Mac OS comes with Python pre-installed. But, not all the Linux Operating Systems ship with Python 3 by default.
Let’s check your python version. Open a terminal (in Linux and Mac OS) or Command Prompt (on Windows) and type
-- python version
and press enter. If the output looks something like Python 3.x.x, you have Python 3 installed. If it says Python 2.x.x you have Python 2. If it prints an error, you don’t probably have python installed.If you don’t have Python 3, install it first.
Read More – Learn to scrape Ebay product data
Install Python 3 and Pip
Here is a guide to install Python 3 in Linux – http://docs.python-guide.org/en/latest/starting/install3/linux/
Mac Users can follow this guide – http://docs.python-guide.org/en/latest/starting/install3/osx/
Windows Users go here – https://www.scrapehero.com/how-to-install-python3-in-windows-10/
Install Packages
- Python Requests, to make requests and download the HTML content of the pages (http://docs.python-requests.org/en/master/user/install/).
- Python LXML, for parsing the HTML Tree Structure using Xpaths (Learn how to install that here – http://lxml.de/installation.html)
- UnicodeCSV for handling Unicode characters in the output file. Install it using pip install unicodecsv.
The Code
from lxml import html
import csv
import requests
import re
import json
import argparse
import traceback
def parse(store_id):
"""
Function to retrieve coupons in a particular walmart store
:param store_id: walmart store id, you can get this id from the output of walmart store location script
(https://github.com/scrapehero/walmart_store_locator/blob/master/walmart_store_locator.py)
"""
#sending request to get coupon related meta details
url = "https://www.walmart.com/store/%s/coupons"%store_id
headers = {"accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"accept-encoding":"gzip, deflate, br",
"accept-language":"en-GB,en;q=0.9,en-US;q=0.8,ml;q=0.7",
"referer":"https://www.walmart.com/store/finder",
"upgrade-insecure-requests":"1",
"user-agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36"
}
#adding retry
for retry in range(5):
try:
response = requests.get(url, headers=headers)
raw_coupon_url_details = re.findall('"couponsData":({.*?})',response.text)
if raw_coupon_url_details:
coupons_details_url_info_dict = json.loads(raw_coupon_url_details[0])
#these variables are used to create coupon page url
pid = coupons_details_url_info_dict.get('pid')
nid = coupons_details_url_info_dict.get('nid')
zid = coupons_details_url_info_dict.get('zid')
#coupons details are rendering from the following url
#example link :https://www.coupons.com/coupons/?pid=19251&nid=10&zid=vz89&storezip=20001
coupons_details_url = "https://www.coupons.com/coupons/?pid={0}&nid={1}&zid={2}".format(pid,nid,zid)
print("retrieving coupon page")
coupon_headers = {"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding":"gzip, deflate, br",
"Accept-Language":"en-GB,en;q=0.9,en-US;q=0.8,ml;q=0.7",
"Host":"www.coupons.com",
"Upgrade-Insecure-Requests":"1",
"User-Agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36"
}
response = requests.get(coupons_details_url,headers=coupon_headers)
coupon_raw_json = re.findall("APP_COUPONSINC\s?=\s?({.*});",response.text)
print("processing coupons data")
if coupon_raw_json:
data = []
coupon_json_data = json.loads(coupon_raw_json[0])
coupons = coupon_json_data.get('contextData').get('gallery').get('podCache')
for coupon in coupons:
price = coupons[coupon].get('summary')
product_brand = coupons[coupon].get('brand')
details = coupons[coupon].get('details')
expiration = coupons[coupon].get('expiration')
activated = coupons[coupon].get('activated')
category_1 = coupons[coupon].get('catdesc1','')
category_2 = coupons[coupon].get('catdesc2','')
category_3 = coupons[coupon].get('catdesc3','')
category = ' > '.join([category_1,category_2,category_3])
wallmart_data={
"offer":price,
"brand":product_brand,
"description":details,
"category":category,
"activated_date":activated,
"expiration_date":expiration,
"url":coupons_details_url
}
data.append(wallmart_data)
return data
except:
print(traceback.format_exc())
return []
if __name__=="__main__":
argparser = argparse.ArgumentParser()
argparser.add_argument('store_id',help = 'walmart store id')
args = argparser.parse_args()
store_id = args.store_id
scraped_data = parse(store_id)
if scraped_data:
print ("Writing scraped data to %s_coupons.csv"%(store_id))
with open('%s_coupons.csv'%(store_id),'w') as csvfile:
fieldnames = ["offer","brand","description","category","activated_date","expiration_date","url"]
writer = csv.DictWriter(csvfile,fieldnames = fieldnames,quoting=csv.QUOTE_ALL)
writer.writeheader()
for data in scraped_data:
writer.writerow(data)
Execute the full code with the script name followed by the store ID:
python3 walmart_coupon_retreiver.py store_id
As an example, to find the coupon details of store 3305, we would run the script like this:
python3 walmart_coupon_retreiver.py 3305
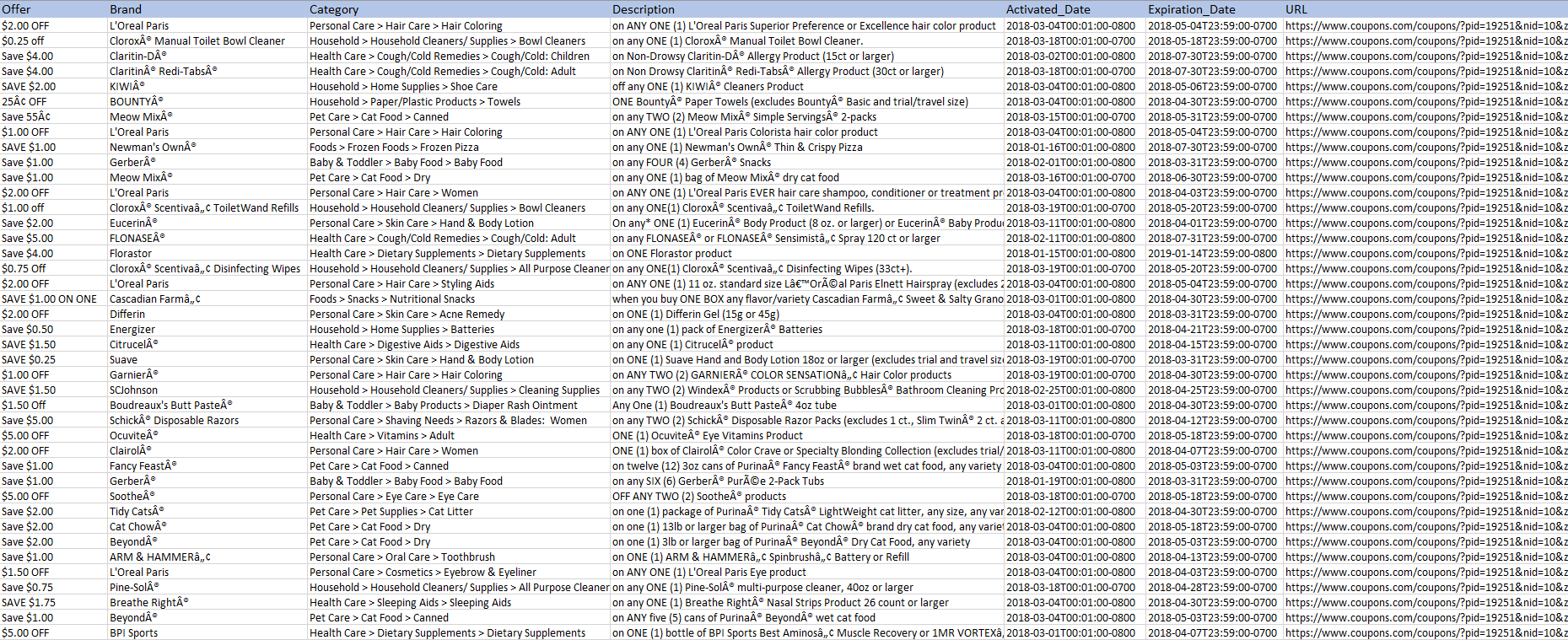
You should get a file called 3305_coupons.csv that will be in the same folder as the script. The output file will look similar to this.
You can download the code at the link https://github.com/scrapehero/walmart-coupons
Read More – Learn to scrape Yellowpages for business data
Known Limitations
This code should work for extracting coupon details of Walmart stores for all store IDs available on Walmart.com. If you want to scrape the details of thousands of pages you should read Scalable do-it-yourself scraping – How to build and run scrapers on a large scale and How to prevent getting blacklisted while scraping. If you would like to scrape Walmart store locations you can look at our previous post – How to Scrape Store Locations from Walmart using Python 3
If you need professional help with scraping complex websites, contact us by filling up the form below.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data
Disclaimer: Any code provided in our tutorials is for illustration and learning purposes only. We are not responsible for how it is used and assume no liability for any detrimental usage of the source code. The mere presence of this code on our site does not imply that we encourage scraping or scrape the websites referenced in the code and accompanying tutorial. The tutorials only help illustrate the technique of programming web scrapers for popular internet websites. We are not obligated to provide any support for the code, however, if you add your questions in the comments section, we may periodically address them.


