

A distributed web scraping architecture is a system in which multiple scraping nodes operate in parallel across different IPs, machines, and regions to extract web data at scale. Unlike single-threaded scrapers, a distributed setup uses a coordinated queue, worker fleet, and proxy layer to handle millions of pages per day without getting blocked, rate-limited, or throttled.
The story of almost every team that tries to scrape the web seriously is the same.
It starts with a script. The script works. Then the scope grows- more sites, more frequency, more volume. Then come the IP bans, the broken selectors, the 2 am alerts. Then come the engineers who are now spending half their time keeping the scraper alive instead of building the actual product.
What started as a tactical solution becomes a maintenance liability. And the root cause is always the same: the architecture was never built for scale.
That’s what this guide is about, how distributed web scraping systems are actually designed, what it takes to run them in production, and the decision every serious data team eventually faces: build this infrastructure yourself, or let someone else run it.
This guide is for teams who want to understand how this infrastructure works. If you’d rather skip straight to having it run for you, ScrapeHero does that →

What Is Large-Scale Web Scraping?
Most people who ask this question already have a scraper running. What they’re really asking is — at what point does what I have stop being enough?
Most teams start hitting real limits the moment scraping moves from one or two sites to dozens, regardless of total page count. Volume is one dimension of scale. Site diversity, freshness requirements, and anti-bot complexity are the others, and they bite just as hard.
Below that, you can get away with a lot. Above it, the web starts pushing back.
When Does Scraping Become “At Scale”?
The limits tend to show up in three ways:
Volume– Too many URLs for one machine to process within your freshness window. You need last night’s prices by 6am, but your single scraper takes 14 hours to finish the job.
Resistance– The more requests you send from the same IP, the faster sites detect and block you. Scale amplifies this problem exponentially, not linearly.
Diversity– Scraping 500 pages from one site is very different from scraping 500 sites with different structures, anti-bot setups, and rate limits. Complexity compounds quickly.
Single Scraper vs. Distributed Scraping — What’s the Difference?
| Single Scraper | Distributed Scraping | |
| IP Management | One IP – banned fast at volume | Rotating proxy pool across many IPs |
| Speed | Sequential, one page at a time | Parallel across a dozen nodes |
| Failure Handling | One failure stops everything | Nodes fail independently |
| Scale Ceiling | Hits limit as site diversity & frequency grows | Designed for millions of pages/day |
| Maintenance | Simple to manage | Complex to manage and coordinate |
| Anti-Bot Resilience | Easily detected | Mimics organic, distributed user traffic |
Think of it like this: one person walking into a store and picking up 10,000 items looks suspicious. Ten thousand people, each picking up one item, look like a normal shopping day. Distributed scraping works the same way- same data collected, just spread across enough nodes that no single one raises a flag.
What Is the Best Architecture for Large-Scale Web Scraping in 2026?
There is no shortage of scraping tutorials on the internet.
Most of them show you how to extract data from a single page. Very few show you what happens when that single page becomes ten million, and the system holding it all together needs to run unattended, recover from failures on its own, and keep delivering clean data while the websites it targets are actively trying to stop it.
That’s what a production-grade distributed scraping architecture actually looks like. And it is made up of six distinct layers, each with its own job.
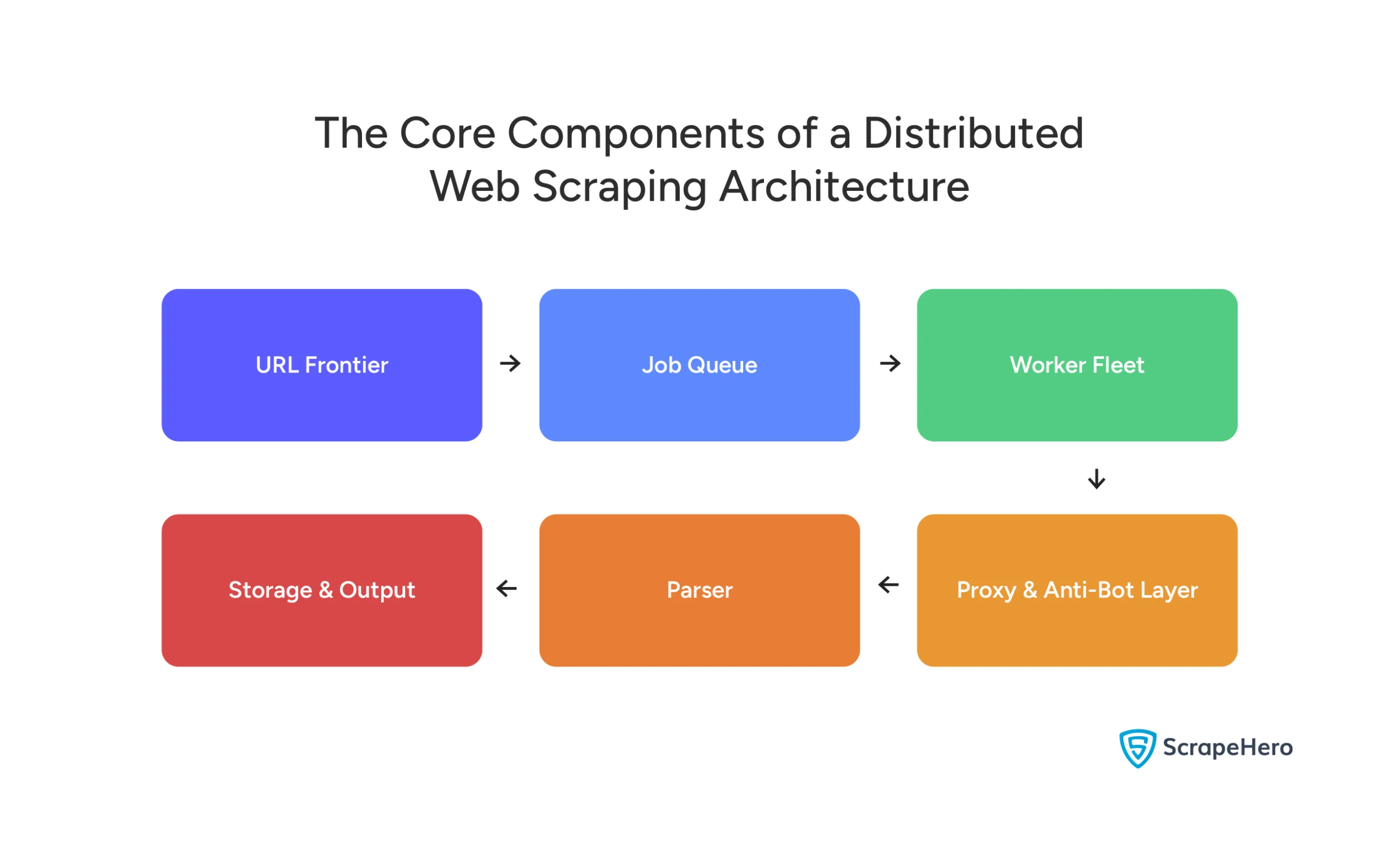
Each layer hands off to the next. A failure in any one of them affects everything downstream. Here’s what each one does and what it costs you to get wrong.
URL Frontier & Job Queue
The job queue holds every URL waiting to be scraped, manages crawl priority and frequency, and distributes work to individual workers. Get this wrong and you end up with duplicate scrapes, missed URLs, or workers sitting idle while the queue backs up.
🔧 Tool Spotlight Teams often repurpose Redis as a quick-start queue since it’s already in most stacks — push URLs in, have workers pop them off. It works at low volumes, but Redis was built for caching, not queuing, and those limitations surface quickly as you scale: limited persistence, no native message replay, and weaker consumer group management. For a purpose-built step up, RabbitMQ is a stronger choice — reliable message routing, built-in acknowledgements, and solid retry logic without the overhead of a full streaming platform. At serious scale, Kafka is the standard — high-throughput, fault-tolerant, and built to handle continuous large-volume URL streams, job replays, and infrastructure failures without data loss.
Worker Nodes & Browser Automation
Workers are the machines that actually visit pages and pull data. The key decision here is whether your targets require a full browser or whether a lightweight HTTP request will do.
HTTP clients like Scrapy or HTTPX are fast and cheap — they work well on simple, server-rendered pages. Headless browsers like Playwright and Puppeteer execute JavaScript and interact with pages like a real user — slower and more resource-intensive, but unavoidable on modern single-page applications. Most at-scale teams run both.
Proxy Rotation & IP Management
Every request your workers make comes from an IP address — and sites use that address, along with request patterns and timing, to decide if you’re a bot. A proxy layer cycles through a pool of IPs so no single one sends enough requests to trigger a ban.
Datacenter proxies are fast and cheap but easily fingerprinted. Residential proxies are assigned to real home devices, much harder to detect, and significantly more expensive.
💡 Pro Tip: At scale, your proxy strategy matters more than your scraping framework. Even a well-engineered Playwright setup will fail consistently if the proxy layer underneath it is thin or poorly rotated.
Anti-Bot Detection & Bypass Layer
This is the layer most teams underestimate, and the one that causes the most silent failures.
Modern anti-bot systems don’t just look at IP addresses. They analyze browser fingerprints, mouse movement patterns, request timing, TLS signatures, and dozens of other signals to distinguish automated traffic from human traffic. Getting past them requires actively mimicking human behavior, not just rotating IPs.
Data Parsing, Normalization & Storage
Raw HTML is not data. A parser extracts the specific fields you need, a normalization layer cleans and structures them, and a deduplication step ensures the same record scraped by two different workers doesn’t appear twice in your database.
Storage destination depends on downstream use: S3 for raw archival, PostgreSQL for structured querying, BigQuery for large-scale analytics.
Scheduler, Orchestrator & Self-Healing Logic
The orchestrator manages crawl schedules, monitors worker health, triggers retries on failure, and scales the worker fleet based on queue depth. Without it, your pipeline requires constant human supervision.
Monitoring & Observability
Tracks crawl success rates, extraction accuracy, data freshness, and queue health in real time. When something breaks — a site blocks you, a parser fails, a worker crashes — you know immediately instead of finding out three days later when a downstream team reports stale data.
Key Engineering Challenges of Running Scrapers at Scale
If the previous is what a distributed scraping system looks like on paper, this section is what it feels like to actually run one.
The challenges below are not edge cases or worst-case scenarios. They are the routine operational reality of maintaining a large-scale scraping infrastructure — and collectively, they are the reason most teams eventually question whether building this in-house was the right call.
Dynamic, JavaScript-Heavy Sites
A significant portion of the modern web doesn’t send you data — it sends you a shell. The actual content is loaded after the page renders, via JavaScript. Simple HTTP requests return empty or incomplete pages, which means your parser extracts nothing useful.
Handling this requires headless browsers, which are slower, more resource-intensive, and harder to scale than HTTP-based scrapers. The more JS-heavy your targets, the more this compounds across your entire worker fleet.
Anti-Bot Measures, And How Quickly They Evolve
This is the challenge that never stops. Anti-bot systems have moved well beyond simple IP blocking — they now analyze hundreds of signals simultaneously: browser fingerprints, mouse movement patterns, keystroke timing, TLS handshake signatures, and behavioral consistency across sessions.
Staying ahead of detection requires continuous investment. Every update an anti-bot vendor ships is potentially a breaking change for your bypass layer.
IP Blacklisting at Scale
Proxy rotation helps, but it doesn’t solve the problem on its own. Sites don’t just blacklist individual IPs anymore. They blacklist entire proxy provider ranges, flag suspicious request patterns regardless of IP, and use behavioral analysis to identify automated traffic even when it’s coming from residential addresses.
At scale, IP management becomes a full-time operational concern, not a configuration you set once.
Data Consistency & Deduplication
Distributed systems introduce a problem single scrapers don’t have: the same URL can be picked up and processed by multiple workers simultaneously. Without a robust deduplication layer, you end up with duplicate records, conflicting data versions, and downstream analytics built on dirty data.
The larger your worker fleet, the more aggressively you need to manage this.
Scraper Breakage From Layout Changes
This is the maintenance burden that catches most teams off guard. It’s not a one-time engineering problem, it’s an ongoing one. A scraper that works perfectly today can be silently returning empty fields by next week, with no error thrown and no alert fired unless you’ve built the monitoring to catch it.
The Real Cost of Doing This In-House
All of these challenges have something in common: they require dedicated, ongoing engineering attention. Not a one-time build. Not a quarterly review. Continuous maintenance.
⚠️ Real-World Cost Callout Consider a common scenario: a mid-sized analytics team assigns 2–3 engineers to maintain their scraping stack. If each spends 40% of their time on it, that’s effectively one full-time engineer consumed by maintenance, before a single dollar of infrastructure is counted.
What Infrastructure Is Needed for Large-Scale Scraping?
Most teams don’t think about infrastructure until their scraper breaks under load. By then, retrofitting a distributed architecture onto something that was never designed for it is significantly harder than building it right the first time.
Here’s what a properly sized setup actually looks like.
Cloud Infrastructure Options
The three major cloud providers — AWS, GCP, and Azure — all support distributed scraping workloads, but the choice of provider matters less than how you configure it.
The most important cost decision at this layer is instance type. Spot instances (AWS — Amazon Web Services) and preemptible VMs (Virtual Machines) on GCP (Google Cloud Platform) can reduce compute costs by up to 90% compared to on-demand pricing — and since scraping workers are stateless and restartable, they are well-suited to being interrupted and relaunched. Teams that design for this from the start unlock the cheapest compute tier on every major cloud provider and make horizontal scaling dramatically simpler.
How Many Requests Per Second Can a Large-Scale Scraper Handle?
There is no single answer, it depends entirely on your worker count, target site response times, proxy pool size, and how much JavaScript rendering your targets require. But as a practical reference:
| Pages/Day | Recommended Stack |
| 100K | Single node + basic proxies |
| 100K-1M | Small distributed fleet + RabbitMQ |
| 1M-10M | Full distributed + Kafka + residential proxies |
| 10+M | Managed service or dedicated infrastructure |
Pricing out infrastructure at this scale? ScrapeHero is a fully managed web scraping service that handles all of this for you. See how it works.
Proxy Infrastructure — How Much Do You Really Need?
Proxy pool sizing is one of the most underestimated infrastructure decisions in a distributed scraping setup. Too small a pool and your IPs burn out faster than you can rotate them. Too geographically concentrated and sites detect the pattern regardless of rotation.
A practical rule: for every 1,000 concurrent requests, you need a proxy pool large enough that no single IP is reused within a detection window — which varies by site but is typically between 10 and 60 minutes.
Residential proxies are the standard for high-value targets, but they come at a cost. Enterprise-scale proxy pools run $1,500–$2,850+/month before any other infrastructure is counted.
Scalable Scraper Maintenance Strategies
If the architecture is the hard part of building a distributed scraping system, maintenance is the hard part of running one.
Most teams discover this the wrong way, a scraper that worked perfectly for months suddenly returns empty fields, no error is thrown, and by the time anyone notices, days of data are missing. The architecture didn’t fail. The website changed. And the scraper had no way to know.
This section covers how teams handle that reality at scale.
How Do You Maintain Scrapers When Websites Change Layouts?
The most effective approach to scraper maintenance combines selector resilience — building scrapers that don’t break on minor DOM changes — with automated monitoring that catches extraction failures before they affect downstream data. Teams operating at serious scale are increasingly adding AI-assisted extraction to reduce breakage incidents significantly.
Website layout changes are not an edge case, they are scheduled maintenance for your scraper team. Every redesign, A/B test, or frontend framework migration on a target site is a potential breaking point.
The strategies that hold up at scale:
- Build resilient selectors from the start — Avoid brittle CSS selectors tied to specific class names or DOM depth. Prefer attribute-based selectors, semantic HTML elements, and XPath expressions that target content structure rather than visual layout.
- Monitor extraction output, not just scraper uptime — A scraper can run successfully and return garbage. Track field-level extraction rates — if the price field starts returning null on 30% of pages, something changed on the target site.
- Version your scrapers — Treat scraper configurations like code. When a site changes and you update the scraper, keep the previous version. If the new version introduces unexpected behavior, you can roll back immediately.
Using AI-Powered Web Data Extraction at Scale
The most significant shift in large-scale scraping over the last two years is the adoption of AI-assisted extraction — using machine learning models to identify and extract content semantically, rather than relying on fixed selectors that break when the DOM changes.
Instead of telling the scraper “extract the text from div.product-price”, an AI-assisted extractor understands “find the price of this product” — and adapts when the layout changes around it.
This is an area where the gap between in-house builds and managed services is widening fast. Building and maintaining your own AI extraction layer is a significant engineering investment — one that most teams cannot justify unless scraping is their core product.
Building a Scraper Health Monitoring System
Monitoring at the scraper level means tracking more than just whether the job ran. The metrics that actually matter:
- Extraction success rate — What percentage of scraped pages are returning complete, expected data? A drop here is your earliest signal that something changed on a target site.
- Data freshness — Is the data arriving on schedule? Delays in the pipeline surface here before they show up in downstream systems.
- Field-level null rates — Track how often specific fields return empty. A sudden spike in null prices or missing titles points directly to a layout change on that specific site.
- Queue depth and worker throughput — Is the queue growing faster than workers are processing it? This signals a capacity problem before it becomes a backlog.
How Do Companies Run Web Scrapers at Scale?
By this point in the guide, the architecture is clear. The infrastructure requirements are clear. The maintenance burden is clear. The question that naturally follows is — how do companies actually deal with all of this in practice?
The answer depends almost entirely on one decision: whether they build and operate the infrastructure themselves, or hand it off to a managed service.
The In-House Model — What It Actually Looks Like
Teams that go the in-house route typically start the same way — a scraper that works, scope that grows, and an architecture that gets retrofitted incrementally to handle increasing demand. Over time, what emerges is a dedicated data engineering function whose primary job is keeping the scraping pipeline alive.
In mature in-house setups, this typically means:
- A dedicated team of 2–5 engineers focused on scraping infrastructure
- A rotating on-call schedule for scraper breakages and pipeline failures
- A continuous cycle of proxy vendor evaluation as IPs get burned
- Regular re-engineering of scrapers as target sites update their frontends
- A growing internal toolset for monitoring, scheduling, and orchestration
This model works, but it works best when web data is central enough to the business to justify the ongoing investment. For companies where data collection is a means to an end rather than the product itself, the engineering overhead consistently outpaces the value of owning the infrastructure.
The Build vs. Buy Decision — Framed Honestly
Every team running scrapers at scale eventually asks this question. And the honest answer is that it’s not a technical decision, it’s a business one.
Building in-house makes sense when:
- Web data collection is your core product or a direct competitive differentiator
- You have compliance or data sovereignty requirements that rule out third-party services
- Your scraping targets are niche enough that no managed service covers them adequately
Using a managed service makes sense when:
- Data collection is a means to an end, not the product itself
- You need to move fast and can’t afford months of infrastructure build time
- Your engineering team’s time is better spent on what actually differentiates your business
Why ScrapeHero Is Built for This
If you’ve read this far, you understand what it takes to build and run a distributed web scraping system. The architecture, the infrastructure, the maintenance cycles, the proxy costs, the engineering overhead.
ScrapeHero exists for teams that have done that math and decided their time is better spent elsewhere.
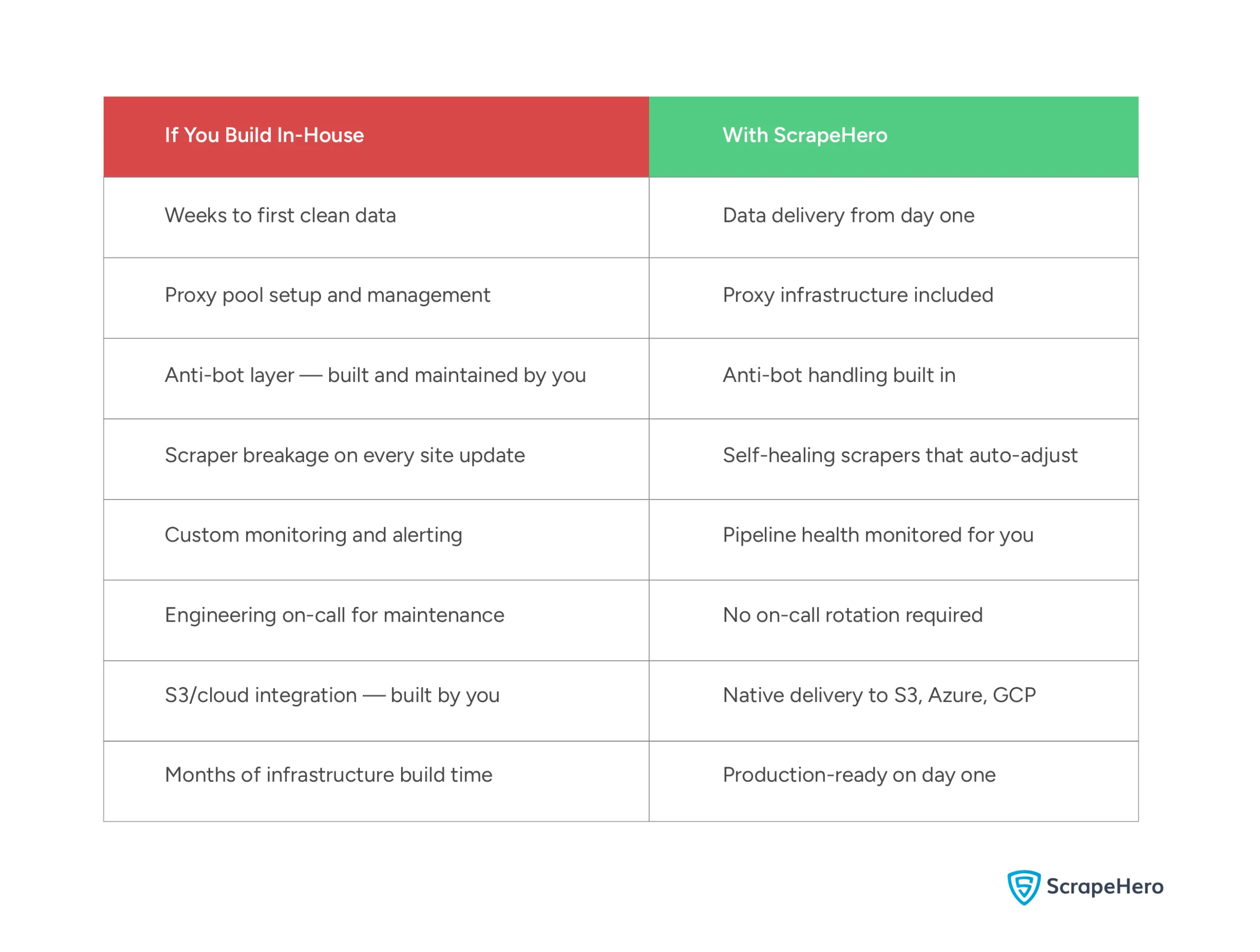
What You’d Spend Months Building vs. What You Get on Day One
What ScrapeHero Actually Does
ScrapeHero is a fully managed web scraping service, meaning you tell us what data you need, and we handle everything required to deliver it reliably at scale. No infrastructure to provision, no proxies to manage, no scrapers to maintain.
The service covers:
- Large-scale data extraction across thousands of pages per second
- Self-healing scrapers that automatically adjust when target sites change layouts — the maintenance problem this entire guide has been building toward
- Any output format — JSON, CSV, XML — delivered directly to your preferred destination, including S3, Azure, and Google Cloud
- Real-time data APIs for sites that don’t offer one natively
- AI and ML-ready datasets for teams building models on top of web data
Who Uses ScrapeHero?
ScrapeHero works with over 14,700 companies, from startups running their first data pipeline to Fortune 50 enterprises with mission-critical data operations.
Trusted by 14,700+ companies including Fortune 50 enterprises for production web data pipelines. ✅No Infra Overhead ✅Anti-Bot Built-In ✅SLA-Backed Delivery ✅Any Format/Any Cloud
You don’t need to build any of what this guide describes to start getting clean, reliable web data at scale.
Get Started. No Infrastructure Required.
FAQ
Building a scalable web scraper requires thinking in layers from the start, not retrofitting scale onto a single-machine setup after the fact.
The core components are a distributed job queue to manage URLs, a horizontally scalable worker fleet to process pages in parallel, a rotating proxy layer to avoid IP bans, and an anti-bot bypass strategy for protected sites.
On top of that, you need a data parsing and normalization layer, an orchestrator to manage worker health and retries, and a monitoring system to catch silent failures before they affect downstream data.
The stack you choose — Python vs. JavaScript, Redis vs. Kafka, datacenter vs. residential proxies — depends on your target volume, site complexity, and freshness requirements.
For a full breakdown of each layer, see the architecture section above.


