

Synchronous web scraping is a good choice for scraping large amounts of data of high quality. But when it comes to processing a large number of URLs at once within a limited scraping time, it is better to choose asynchronous web scraping.
This article mainly deals with asynchronous web scraping. Here you can learn to create an asynchronous scraper in Python using the aiohttp module.
Synchronous Web Scraping vs. Asynchronous Web Scraping in Python
In Python, web scraping is carried out in two primary modes: Synchronous and Asynchronous. Synchronous web scraping in Python is a traditional approach that involves sending a request and waiting for the response before continuing to the next action. It is easier to implement but slower and increases the total scraping time.
Whereas asynchronous web scraping in Python handles multiple requests simultaneously without waiting for each to complete. It can reduce the total time required for scraping large amounts of data. But it is more difficult to implement.
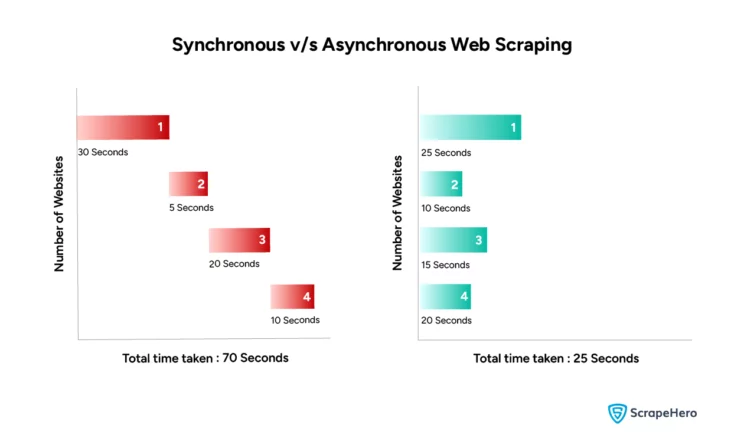
From the figure, it’s clear that when scraping multiple websites, the total time taken for asynchronous web scraping is much less than that of synchronous web scraping.
Scraping scrapeme.live Asynchronously in Python
Now let’s take a sample website, ScrapeMe, and create an asynchronous scraper to scrape details. You can also refer to ScrapeHero’s article ‘Web Scraping with Python Requests’ to understand how you can extract details from ScrapeMe using a synchronous Python scraper.
Web Scraping Using Python Asyncio
Asyncio is used as a foundation for multiple Python asynchronous frameworks that provide high-performance network and web servers, database connection libraries, distributed task queues, etc.
Web scraping using asyncio in Python is a technique for asynchronously fetching data from multiple web pages simultaneously. The asyncio library performs concurrent network requests without blocking the execution of your program, allowing other tasks to run in the meantime.
Usually, when web scraping using asyncio, it is combined with an asynchronous HTTP client for Python named aiohttp.
Choosing a Python Request Module That Works Asynchronously
You cannot use the popular Python requests module to send requests asynchronously; instead,as mentioned earlier, use the aiohttp module that supports sending requests asynchronously.
Install aiohttp using the pip command:
pip install aiohttpYou also require the LXML library to parse the HTML. Install LXML using the command:
pip install lxmlasync def send_request(url):
headers = {
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36",
"Accept-Language": "en-US,en;q=0.5"
}
async with aiohttp.ClientSession() as session:
async with session.get(url, headers=headers) as response:
if verify_response(response):
await response.text()
return response
print("Invalid response received. URL with the issue is:", url)
raise Exception("Stopping the code execution as invalid response received.")The send_request function handles sending requests using the aiohttp module. Async and await keywords are used in Python to create and await an asynchronous function.
Collecting Listing Page URLs
Scrapeme.live listing page URLs are generated in the format
f"https://scrapeme.live/shop/page/{listing_page_number}/"Designing an Asynchronous Scraper
Designing a scraper for asynchronous web scraping in Python is a little different. To make requests concurrently, you need to create multiple tasks and use asyncio.gather to run all these tasks concurrently.
Creating send_request coroutines from listing page URLs
listing_page_tasks = []
for listing_page_number in range(1, 6):
listing_page_url = f"https://scrapeme.live/shop/page/{listing_page_number}/"
listing_page_request = send_request(listing_page_url)
listing_page_tasks.append(listing_page_request)
listing_page_responses = await asyncio.gather(*listing_page_tasks)Here you have generated the first 6 listing page request URLs and created a send_request coroutine based on this listing page. Then you append all these coroutines to a list to send them concurrently using asyncio.gather.
Extracting Product URLs From the Listing Page Response
Now you need to extract product URLs from the listing page response using XPath.
async def get_product_urls(response):
parser = html.fromstring(await response.text())
product_urls = parser.xpath('//li/a[contains(@class, "product__link")]/@href')
return product_urlsproduct_urls = []
for each_listing_page_response in listing_page_responses:
products_from_current_page = await get_product_urls(each_listing_page_response)
product_urls.extend(products_from_current_page)Collect all the product page URLs from each listing page response and append them to a list.
Create send_request coroutines from product page URLs.
product_request_tasks = []
for url in product_urls:
product_request = send_request(url)
product_request_tasks.append(product_request)
product_responses = await asyncio.gather(*product_request_tasks)Create a send_request coroutine from the collected product URLs and send these requests concurrently using asyncio.gather.
When you send all the requests concurrently this may overload the server, so it isn’t recommended. Limit the number of requests by limiting the tasks and routes passed to the gather function.
Extracting Product Data Points
async def get_product_data(response):
parser = html.fromstring(await response.text())
product_url = response.url
title = parser.xpath('//h1[contains(@class, "product_title")]/text()')
price = parser.xpath('//p[@class="price"]//text()')
stock = parser.xpath('//p[contains(@class, "in-stock")]/text()')
description = parser.xpath('//div[contains(@class,"product-details__short-description")]//text()')
image_url = parser.xpath('//div[contains(@class, "woocommerce-product-gallery__image")]/a/@href')
product_data = {
'Title': clean_string(title), 'Price': clean_string(price), 'Stock': clean_stock(stock),
'Description': clean_string(description), 'Image_URL': clean_string(list_or_txt=image_url, connector=' | '),
'Product_URL': product_url}
return product_dataThe get_product_data function extracts title, price, stock, description, and image URL using XPath.
results = []
for each_product_response in product_responses:
product_result = await get_product_data(each_product_response)
results.append(product_result)Now append all the product results to a list and later save this data to a CSV file.
Saving Data to a CSV
def save_data_to_csv(data, filename):
keys = data[0].keys()
with open(filename, 'w', newline='') as csv_file:
writer = csv.DictWriter(csv_file, fieldnames=keys)
writer.writeheader()
writer.writerows(data)save_data_to_csv saves data to a csv named “scrapeme_live_Python_data”.
Running the Scraper
Run the main async function start_scraping using the asyncio.run function.
async def start_scraping():
listing_page_tasks = []
for listing_page_number in range(1, 6):
listing_page_url = f"https://scrapeme.live/shop/page/{listing_page_number}/"
listing_page_request = send_request(listing_page_url)
listing_page_tasks.append(listing_page_request)
listing_page_responses = await asyncio.gather(*listing_page_tasks)
product_urls = []
for each_listing_page_response in listing_page_responses:
products_from_current_page = await get_product_urls(each_listing_page_response)
product_urls.extend(products_from_current_page)
product_request_tasks = []
for url in product_urls:
product_request = send_request(url)
product_request_tasks.append(product_request)
product_responses = await asyncio.gather(*product_request_tasks)
results = []
for each_product_response in product_responses:
product_result = await get_product_data(each_product_response)
results.append(product_result)
save_data_to_csv(data=results, filename='scrapeme_live_Python_data.csv')
print('Data saved as csv')
if __name__ == "__main__":
asyncio.run(start_scraping())Get the complete code for Asynchronous Scraper Using Python on GitHub.
Wrapping Up
The choice between synchronous and asynchronous web scraping in Python depends on your scraping needs. Synchronous scraping is suitable for simple, straightforward, and small-scale projects, whereas asynchronous scraping is complex and ideal for large-scale, I/O-bound tasks.
If coding on your part is a constraint, then ScrapeHero Cloud could be a great solution for your scraping requirements. It offers pre-built crawlers and APIs such as Google Maps Search Results. It is hassle-free, affordable, fast, and reliable, offering a no-code approach to users without extensive technical knowledge.
For large-scale web scraping, efficiency and speed are paramount. So you can consult ScrapeHero. Considering the complexity of managing asynchronous operations, we suggest you avail yourself of ScrapeHero web scraping services, which are bespoke, custom, and more advanced.
Frequently Asked Questions
Yes, asynchronous programming in Python for web scraping is possible. It allows for efficient handling of I/O-bound and high-level structured network code with the use of the asyncio library in Python.
Asynchronous web scraping in Python refers to data extraction from websites in a non-blocking manner. It allows for multiple concurrent requests and pauses while waiting for a response, during which other routines can run.
In synchronous web scraping, requests are sent sequentially, waiting for each to complete before starting the next. This may lead to potential inefficiencies. However, in asynchronous scraping, there is no waiting for each request to finish before proceeding to the next.
In Python, asynchronous tasks are performed using the asyncio library. Defining functions with async def and await can execute multiple operations concurrently, optimizing performance and efficiency in I/O-bound applications.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



