
Yelp.com hosts reviews that show how much people like a business. You can scrape Yelp and analyze the reviews to conduct market research. Moreover, the reviews will help you generate ideas for improving your products and services.
This tutorial will show you how to scrape Yelp data using Python. The code uses Python requests to manage HTTP requests and lxml to parse HTML.
The Environment for Web Scraping Yelp
Both requests and lxml are external Python libraries, so you must install them separately using pip. You can use this code to install both lxml and requests.
pip install lxml requestsData Scraped from Yelp
The code will scrape Yelp for these details from its search results page.
- Business name
- Rank
- Review count
- Categories
- Ratings
- Price range
- Yelp URL
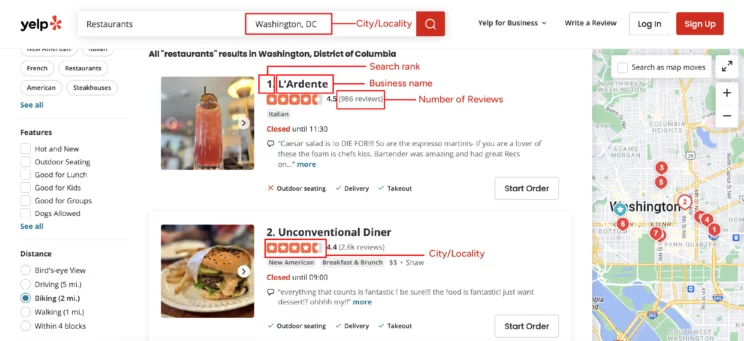
These will be in the JSON data inside a script tag of the search results page; there is no need to figure out XPaths for individual data points.
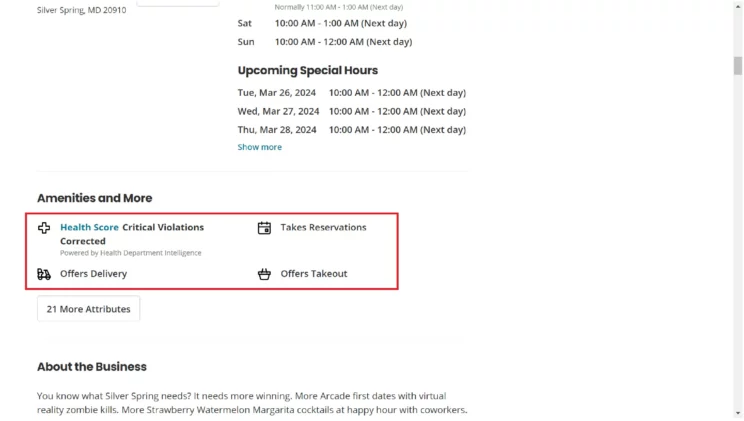
However, the code also makes HTTPS requests to the URL of each business listing extracted in the previous step and extracts more details. The code uses the XPath syntax to locate and extract these details, which include
- Name
- Working hours
- Featured info
- Phone number
- Rating
- Address
- Price Range
- Claimed Status
- Review Count
- Category
- Website
- Longitude and Latitude
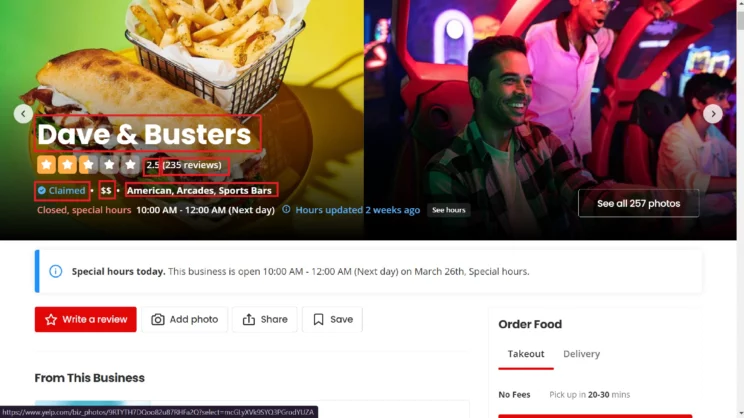
The Code for Web Scraping Yelp
To scrape Yelp using Python, import the libraries mentioned above, namely requests and lxml. These are the core libraries required for scraping Yelp data. Other packages imported are JSON, argparse, urllib.parse, re, and unicodecsv.
- The JSON module is necessary to parse JSON content from Yelp and save the data to a JSON file.
- The argparse module allows you to pass arguments from the command line.
- unicodecsv helps you save the scraped data as a CSV file.
- Urllib.parse enables you to manipulate the URL string.
- The re module handles regular expressions.
from lxml import html
import unicodecsv as csv
import requests
import argparse
import json
import re
import urllib.parseYou will define two functions in this code: parse() and parseBusiness().
parse()
The function parse()
- Sends HTTP requests to the search results page
- Parses responses, extracts business listings
- Returns the scraped data as objects
parse() sends requests to Yelp.com with a header intended to pose as a legitimate user. It uses a loop to try sending HTTP requests repeatedly until it gets the status code 200.
headers = {'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,'
'*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-language': 'en-GB;q=0.9,en-US;q=0.8,en;q=0.7',
'dpr': '1',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'}
success = False
for _ in range(10):
response = requests.get(url, verify=False, headers=headers)
if response.status_code == 200:
success = True
break
else:
print("Response received: %s. Retrying : %s"%(response.status_code, url))
success = FalseOnce you get the response, you can parse it using html.fromstring().
parser = html.fromstring(response.text)You can now extract the JSON data from the parsed object. After extracting it, you will also clean the data by removing unnecessary characters and spaces.
raw_json = parser.xpath("//script[contains(@data-hypernova-key,'yelpfrontend')]//text()")
cleaned_json = raw_json[0].replace('<!--', '').replace('-->', '').strip()
The code then parses the JSON data using json.loads() and extracts the search results.
json_loaded = json.loads(cleaned_json)
search_results = json_loaded['legacyProps']['searchAppProps']['searchPageProps']['mainContentComponentsListProps']
You can then iterate through the search results and obtain the required data with get().
for results in search_results:
# Ad pages doesn't have this key.
result = results.get('searchResultBusiness')
if result:
is_ad = result.get('isAd')
price_range = result.get('priceRange')
position = result.get('ranking')
name = result.get('name')
ratings = result.get('rating')
reviews = result.get('reviewCount')
category_list = result.get('categories')
url = "https://www.yelp.com"+result.get('businessUrl')The function then
- stores the scraped data in a dictionary
- appends it to an array
- returns the array
category = []
for categories in category_list:
category.append(categories['title'])
business_category = ','.join(category)
# Filtering out ads
if not(is_ad):
data = {
'business_name': name,
'rank': position,
'review_count': reviews,
'categories': business_category,
'rating': ratings,
'price_range': price_range,
'url': url
}
scraped_data.append(data)
return scraped_dataparseBusiness()
The parseBusiness() function extracts details from the businesses extracted by parse().
As before, the function makes an HTTP request to the URL of the Yelp business page and parses the response. However, this time, you will use XPaths.
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.90 Safari/537.36'}
response = requests.get(url, headers=headers, verify=False).text
parser = html.fromstring(response)You can figure out XPaths by inspecting the source code. To do that, right-click on the webpage and click inspect. For example, look at the code for the price range.
<span class=" css-14r9eb" data-font-weight="semibold">$$<!-- --> </span>
Price range is a text inside a span element. Therefore, you can write its XPath as
//span[@class=' css-14r9eb']/text()Similarly, you can find all the XPaths and extract the corresponding data.
raw_name = parser.xpath("//h1//text()")
raw_claimed = parser.xpath("//span[@class=' css-1luukq']//text()")[1] if parser.xpath("//span[@class=' css-1luukq']//text()") else None
raw_reviews = parser.xpath("//span[@class=' css-1x9ee72']//text()")
raw_category = parser.xpath('//span[@class=" css-1xfc281"]//text()')
hours_table = parser.xpath("//table[contains(@class,'hours-table')]//tr")
details_table = parser.xpath("//span[@class=' css-1p9ibgf']/text()")
raw_map_link = parser.xpath("//a[@class='css-1inzsq1']/div/img/@src")
raw_phone = parser.xpath("//p[@class=' css-1p9ibgf']/text()")
raw_address = parser.xpath("//p[@class=' css-qyp8bo']/text()")
raw_wbsite_link = parser.xpath("//p/following-sibling::p/a/@href")
raw_price_range = parser.xpath("//span[@class=' css-14r9eb']/text()")[0] if parser.xpath("//span[@class=' css-14r9eb']/text()") else None
raw_ratings = parser.xpath("//span[@class=' css-1fdy0l5']/text()")[0] if parser.xpath("//span[@class=' css-1fdy0l5']/text()") else NoneYou can then clean each data by striping extra spaces.
name = ''.join(raw_name).strip()
phone = ''.join(raw_phone).strip()
address = ' '.join(' '.join(raw_address).split())
price_range = ''.join(raw_price_range).strip() if raw_price_range else None
claimed_status = ''.join(raw_claimed).strip() if raw_claimed else None
reviews = ''.join(raw_reviews).strip()
category = ' '.join(raw_category)
cleaned_ratings = ''.join(raw_ratings).strip() if raw_ratings else None
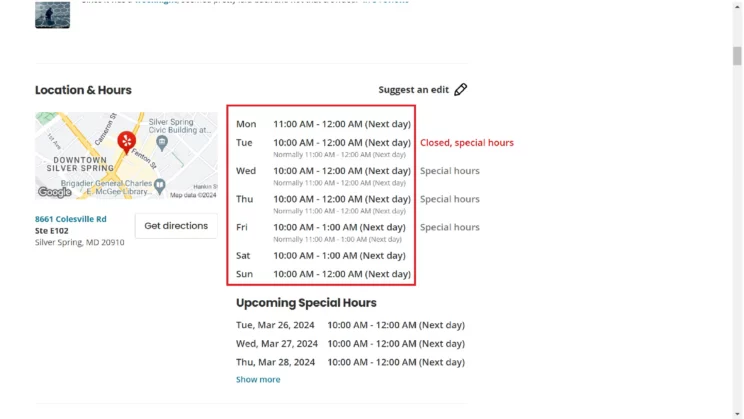
However, you must iterate through the hours table to find the working hours.
working_hours = []
for hours in hours_table:
if hours.xpath(".//p//text()"):
day = hours.xpath(".//p//text()")[0]
timing = hours.xpath(".//p//text()")[1]
working_hours.append({day:timing})
The business’s website URL will be inside another link, so you must decode it using regular expressions and urllib.parse.
if raw_wbsite_link:
decoded_raw_website_link = urllib.parse.unquote(raw_wbsite_link[0])
print(decoded_raw_website_link)
website = re.findall("biz_redir\?url=(.*)&website_link",decoded_raw_website_link)[0]
else:
website = ''Similarly, you require regular expressions to get the business location’s longitude and latitude.
if raw_map_link:
decoded_map_url = urllib.parse.unquote(raw_map_link[0])
if re.findall("center=([+-]?\d+.\d+,[+-]?\d+\.\d+)",decoded_map_url):
map_coordinates = re.findall("center=([+-]?\d+.\d+,[+-]?\d+\.\d+)",decoded_map_url)[0].split(',')
latitude = map_coordinates[0]
longitude = map_coordinates[1]
else:
latitude = ''
longitude = ''
else:
latitude = ''
longitude = ''
Finally, you will save all the extracted business details to a dict and append them to an array, which the function will return.
data={'working_hours':working_hours,
'info':info,
'name':name,
'phone':phone,
'ratings':ratings,
'address':address,
'price_range':price_range,
'claimed_status':claimed_status,
'reviews':reviews,
'category':category,
'website':website,
'latitude':latitude,
'longitude':longitude,
'url':url
}
return data
Next,
- set up argparse to accept the zip code and search keywords from the command line.
argparser = argparse.ArgumentParser() argparser.add_argument('place', help='Location/ Address/ zip code') search_query_help = """Available search queries are:\n Restaurants,\n Breakfast & Brunch,\n Coffee & Tea,\n Delivery, Reservations""" argparser.add_argument('search_query', help=search_query_help) args = argparser.parse_args() place = args.place search_query = args.search_query - call parse()
yelp_url = "https://www.yelp.com/search?find_desc=%s&find_loc=%s" % (search_query,place) print ("Retrieving :", yelp_url) #Calling the parse function scraped_data = parse(yelp_url) - use DictWriter() to write the data to a CSV file by writing
- the header of the CSV file using writeheader()
- each row with writerow() using a loop
#writing the data with open("scraped_yelp_results_for_%s_in_%s.csv" % (search_query,place), "wb") as fp: fieldnames = ['rank', 'business_name', 'review_count', 'categories', 'rating', 'price_range', 'url'] writer = csv.DictWriter(fp, fieldnames=fieldnames, quoting=csv.QUOTE_ALL) writer.writeheader() if scraped_data: print ("Writing data to output file") for data in scraped_data: writer.writerow(data) - call parseBusiness() in a loop and write the extracted details to a JSON file
for data in scraped_data: bizData = parseBusiness(data.get('url')) yelp_id = data.get('url').split('/')[-1].split('?')[0] print("extracted "+yelp_id) with open(yelp_id+".json",'w') as fp: json.dump(bizData,fp,indent=4)
Here is the complete code for web scraping Yelp.
from lxml import html
import unicodecsv as csv
import requests
import argparse
import json
import re
import urllib.parse
def parse(url):
headers = {'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,'
'*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-language': 'en-GB;q=0.9,en-US;q=0.8,en;q=0.7',
'dpr': '1',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'}
success = False
for _ in range(10):
response = requests.get(url, verify=False, headers=headers)
if response.status_code == 200:
success = True
break
else:
print("Response received: %s. Retrying : %s"%(response.status_code, url))
success = False
if success == False:
print("Failed to process the URL: ", url)
parser = html.fromstring(response.text)
raw_json = parser.xpath("//script[contains(@data-hypernova-key,'yelpfrontend')]//text()")
scraped_data = []
if raw_json:
print('Grabbing data from new UI')
cleaned_json = raw_json[0].replace('<!--', '').replace('-->', '').strip()
json_loaded = json.loads(cleaned_json)
search_results = json_loaded['legacyProps']['searchAppProps']['searchPageProps']['mainContentComponentsListProps']
for results in search_results:
# Ad pages doesn't have this key.
result = results.get('searchResultBusiness')
if result:
is_ad = result.get('isAd')
price_range = result.get('priceRange')
position = result.get('ranking')
name = result.get('name')
ratings = result.get('rating')
reviews = result.get('reviewCount')
category_list = result.get('categories')
url = "https://www.yelp.com"+result.get('businessUrl')
category = []
for categories in category_list:
category.append(categories['title'])
business_category = ','.join(category)
# Filtering out ads
if not(is_ad):
data = {
'business_name': name,
'rank': position,
'review_count': reviews,
'categories': business_category,
'rating': ratings,
'price_range': price_range,
'url': url
}
scraped_data.append(data)
return scraped_data
def parseBusiness(url):
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.90 Safari/537.36'}
response = requests.get(url, headers=headers, verify=False).text
parser = html.fromstring(response)
print("Parsing the page")
raw_name = parser.xpath("//h1//text()")
raw_claimed = parser.xpath("//span[@class=' css-1luukq']//text()")[1] if parser.xpath("//span[@class=' css-1luukq']//text()") else None
raw_reviews = parser.xpath("//span[@class=' css-1x9ee72']//text()")
raw_category = parser.xpath('//span[@class=" css-1xfc281"]//text()')
hours_table = parser.xpath("//table[contains(@class,'hours-table')]//tr")
details_table = parser.xpath("//span[@class=' css-1p9ibgf']/text()")
raw_map_link = parser.xpath("//a[@class='css-1inzsq1']/div/img/@src")
raw_phone = parser.xpath("//p[@class=' css-1p9ibgf']/text()")
raw_address = parser.xpath("//p[@class=' css-qyp8bo']/text()")
raw_wbsite_link = parser.xpath("//p/following-sibling::p/a/@href")
raw_price_range = parser.xpath("//span[@class=' css-14r9eb']/text()")[0] if parser.xpath("//span[@class=' css-14r9eb']/text()") else None
raw_ratings = parser.xpath("//span[@class=' css-1fdy0l5']/text()")[0] if parser.xpath("//span[@class=' css-1fdy0l5']/text()") else None
working_hours = []
for hours in hours_table:
if hours.xpath(".//p//text()"):
day = hours.xpath(".//p//text()")[0]
timing = hours.xpath(".//p//text()")[1]
working_hours.append({day:timing})
info = details_table
name = ''.join(raw_name).strip()
phone = ''.join(raw_phone).strip()
address = ' '.join(' '.join(raw_address).split())
price_range = ''.join(raw_price_range).strip() if raw_price_range else None
claimed_status = ''.join(raw_claimed).strip() if raw_claimed else None
reviews = ''.join(raw_reviews).strip()
category = ' '.join(raw_category)
cleaned_ratings = ''.join(raw_ratings).strip() if raw_ratings else None
if raw_wbsite_link:
decoded_raw_website_link = urllib.parse.unquote(raw_wbsite_link[0])
print(decoded_raw_website_link)
website = re.findall("biz_redir\?url=(.*)&website_link",decoded_raw_website_link)[0]
else:
website = ''
if raw_map_link:
decoded_map_url = urllib.parse.unquote(raw_map_link[0])
if re.findall("center=([+-]?\d+.\d+,[+-]?\d+\.\d+)",decoded_map_url):
map_coordinates = re.findall("center=([+-]?\d+.\d+,[+-]?\d+\.\d+)",decoded_map_url)[0].split(',')
latitude = map_coordinates[0]
longitude = map_coordinates[1]
else:
latitude = ''
longitude = ''
else:
latitude = ''
longitude = ''
if raw_ratings:
ratings = re.findall("\d+[.,]?\d+",cleaned_ratings)[0]
else:
ratings = 0
data={'working_hours':working_hours,
'info':info,
'name':name,
'phone':phone,
'ratings':ratings,
'address':address,
'price_range':price_range,
'claimed_status':claimed_status,
'reviews':reviews,
'category':category,
'website':website,
'latitude':latitude,
'longitude':longitude,
'url':url
}
return data
if __name__ == "__main__":
argparser = argparse.ArgumentParser()
argparser.add_argument('place', help='Location/ Address/ zip code')
search_query_help = """Available search queries are:\n
Restaurants,\n
Breakfast & Brunch,\n
Coffee & Tea,\n
Delivery,
Reservations"""
argparser.add_argument('search_query', help=search_query_help)
args = argparser.parse_args()
place = args.place
search_query = args.search_query
yelp_url = "https://www.yelp.com/search?find_desc=%s&find_loc=%s" % (search_query,place)
print ("Retrieving :", yelp_url)
#Calling the parse function
scraped_data = parse(yelp_url)
#writing the data
with open("scraped_yelp_results_for_%s_in_%s.csv" % (search_query,place), "wb") as fp:
fieldnames = ['rank', 'business_name', 'review_count', 'categories', 'rating', 'price_range', 'url']
writer = csv.DictWriter(fp, fieldnames=fieldnames, quoting=csv.QUOTE_ALL)
writer.writeheader()
if scraped_data:
print ("Writing data to output file")
for data in scraped_data:
writer.writerow(data)
#Extracting details from business pages
for data in scraped_data:
bizData = parseBusiness(data.get('url'))
yelp_id = data.get('url').split('/')[-1].split('?')[0]
print("extracted "+yelp_id)
with open(yelp_id+".json",'w') as fp:
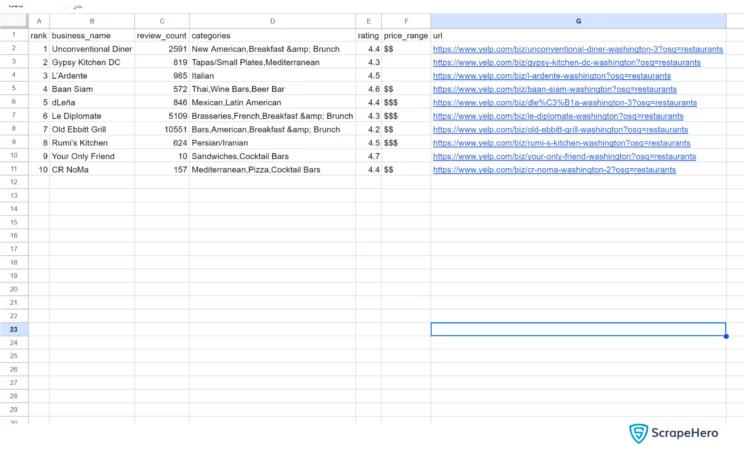
json.dump(bizData,fp,indent=4)Here is the data extracted from Yelp.
Code Limitations for Web Scraping Yelp
You can collect data from Yelp using this code for the time being. However, Yelp may change the JSON structure at any time. And when they do, you must update this code to reflect the changes.
Moreover, this code won’t be sufficient if you want to scrape data from Yelp on a large scale. You must consider advanced techniques like proxy rotation to bypass Yelp’s anti-scraping measures.
Using The Script
You can use the script from the command line with a zip code or location name and a search query. For example,
python yelp_scraper.py 20001 RestaurantsYou can get the syntax by using the -h flag.
usage: yelp_search.py [-h] place keyword
positional arguments:
place Location/ Address/ zip code
keyword Any keyword
optional arguments:
-h, --help show this help message and exit
Wrapping Up
It is possible to scrape Yelp using Python to gather data about your competitors and understand the pain points of your target customers. Python library requests and lxml can do the job.
But remember to watch for any changes to Yelp.com’s HTML structure. Whenever Yelp’s HTML structure changes, you must figure out the new XPaths for data points and JSON data.
Although, you don’t have to take all the trouble for web scraping Yelp.
You can try the ScrapeHero Yelp Scraper from the ScrapeHero cloud for free. It offers a no-code solution, so you don’t need to learn how to scrape Yelp data to use it.
You can also forget about modifying the code for large-scale data extraction. ScrapeHero services can help you with that.
ScrapeHero is an enterprise-grade web scraping service provider. Our services range from large-scale web scraping and crawling to custom robotic process automation. Leave all the coding to ScrapeHero; you only need to tell us what you need.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



