

Web scraping is a valuable tool in this era of data-driven decision-making. Gathering public data for analysis is not just about accessing data but also careful ethical consideration of how it is used. This opens a new area of study: Ethical web scraping.
This article discusses various aspects of the ethics of web scraping and the legalities involved in the United States for ensuring compliance and integrity.
What Is Web Scraping?
Web scraping, known by its various names—web harvesting or web data extraction—is an automatic method using bots to extract large amounts of data from websites. It extracts the unstructured data from the HTML code of the web page and stores the data in a database.
Why Is Web Scraping Controversial?
Web scraping is controversial as it revolves around legal, ethical, and technical issues. It’s crucial to respect privacy and data ownership when collecting personal data without consent. The data gathered through web scraping may fall under intellectual property.
As said earlier there are many ethical issues with web scraping. So scraping private data without permission is seen as a violation of copyright laws, emphasizing the need for ethical practices in web scraping.
Aggressive web scraping can increase the load on website servers, degrading service for other users. Moreover, the data scraped from dynamic websites that have changed website structure may not be accurate or reliable. For these reasons, adherence to best practices while scraping websites is a must.
Legal Framework Governing Web Scraping in the U.S
Due to ethical issues with web scraping, such as copyright infringement, privacy, and contractual obligations, it is subject to legal scrutiny in the U.S. Businesses or individuals involved in web scraping must deal with a complex legal landscape if they do not comply with applicable laws and regulations.
The legality of web scraping in the U.S. mainly depends on specific laws and court decisions as discussed:
1. The Computer Fraud and Abuse Act (CFAA)
The Computer Fraud and Abuse Act (CFAA) was enacted in 1986 and is the primary federal statute governing computer-related crimes. The CFAA prohibits access to a computer without authorization. However, the word “authorization” is in a gray area, especially in web scraping cases, which leads to varying legal outcomes.
2. The Digital Millennium Copyright Act (DMCA)
The Digital Millennium Copyright Act (DMCA) intends to protect digital data from unauthorized reproduction or distribution. From a web scraping point of view, this act focuses more on infringement of copyright laws, that is, scraping and republishing copyrighted material without permission.
3. Court Rulings
There are many Court Rulings regarding data scraping, such as the Meta vs. Bright Data Case, which are discussed in detail in the upcoming sections. In most cases, the legal stance on web scraping is that scraping publicly accessible data is not a violation of the CFAA. However, unauthorized intrusions into protected computer systems are considered a violation of the law.
Web Scraping Ethical Issues
Web scraping can have several harmful consequences. Some ethical issues with web scraping are breaches of the privacy of individuals due to the exposure of personal data, threats to the privacy and trade secrets of organizations as sensitive business information gets exposed, reducing organizational value, and reducing revenue or customer trust. These risks raise concerns about the legality and ethics of web scraping data.

Since the ethical landscape of web scraping is quite complex, it is better to involve a few considerations to mitigate potential harms:
-
Adopting Mixed Ethical Approaches in Web Scraping
Follow a combination of duty-based ethics and outcome-based ethics. Duty-based ethics focus on the morality of actions, whereas outcome-based ethics consider the consequences.
-
Upholding Privacy and Confidentiality Standards
Respect individual privacy and data confidentiality in web scraping to prevent breaches, such as in many court cases involving violating internet privacy laws.
-
Ensuring Ethical Data Usage and Securing Consent
Data must be responsibly used for the intended purposes only. This ensures that the data obtained with consent does not violate user expectations and ethical norms.
-
Preventing Bias and Discrimination Through Careful Data Handling
The data gathered through web scraping must be managed carefully; if not, it can reinforce biases or result in unfair practices.
-
Safeguarding Organizational Privacy and Preserving Content Value
When web scraping exposes sensitive business information, it can diminish the value of the business or brand, affecting the credibility of the website’s content or affecting the original data owners financially.
-
Prioritizing High-Quality Data for Impactful Decision-Making
Since the quality of the data extracted has a substantial impact on business and policy decisions, this data must meet high standards of accuracy.
Legal Implications
There are no universal legal rules for web scraping. However, some basic guidelines focus on critical legal points. These guidelines help us understand the legal side of web scraping and the importance of following rules. There are three primary legal areas considered when web scraping:
- Copyright
- Terms of service
- Trespass to chattels
1. Copyright
The term copyright stresses respecting the ownership of content in this aspect. Generally, facts and ideas are not considered copyrightable, but expressions or arrangements of facts are.
So, by collecting facts from the data sources, no one violates the law, but copying them will be an issue.
2. Terms of Service
Terms of service (ToS) are formed to follow the rules set by websites. They also mean a legally binding relationship between the website and the user. But note that the legal binding will also be specific for each service.
Also, there are no general Terms of Service (ToS) for websites. In most cases, terms of service lie in a gray area.
3. Trespass to Chattels
While ‘copyright’ and ‘terms of service’ are familiar terms in engineering, ‘trespass to chattels’ is less known. It is from common law and means interfering with someone else’s property on purpose.
In web scraping, if a scraper overloads a website, causing a Denial of Service (DoS) without permission, it can be seen as a ‘trespass to chattels.’
Case Studies of Ethical Web Scraping in the U.S.
Ethics of web scraping is a crucial topic for businesses, analysts, and researchers. When organizations adhere to legal and ethical guidelines, they can collect data responsibly.
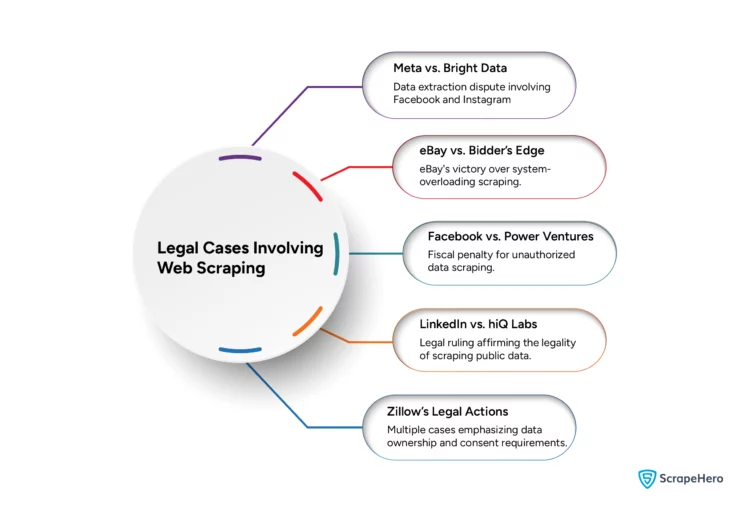
Here are some controversial high-profile web scraping legal battles that happened over the years:
1. Meta vs. Bright Data Case
In 2023, Meta Platforms sued Bright Data in California for illegal scraping from Facebook and Instagram. Bright Data defended its practices by highlighting the legality of extracting public data.
Result: The Federal Court in the U.S. ruled in favor of Bright Data and confirmed that scraping publicly accessible data from Meta’s platforms did not violate Meta’s terms of service when conducted without logging into an account.
2. eBay vs. Bidder’s Edge Case
In 2000, eBay sued Bidder’s Edge, a price comparison site, for scraping its website content. eBay argued that the scraping strained its system and could lead to further harm if others did the same.
Result: eBay won the case when the court sided with it, preventing Bidder’s Edge from scraping eBay’s website data.
3. Facebook vs. Power Ventures Case
In 2009, Facebook sued Power Ventures for scraping user-uploaded content from its site. Power Ventures violated the Computer Fraud and Abuse Act by accessing Facebook’s servers after being told to stop, leading to an injunction.
Result: The U.S. District Court ruled in favor of Facebook, treating the case as an intellectual property issue. It also imposed a financial penalty on Power Ventures for the unauthorized data extraction.
4. LinkedIn vs. hiQ Labs Case
In 2019, LinkedIn sued hiQ Labs for scraping publicly available profiles for analytics. hiQ argued that preventing access to public data violated antitrust laws and constituted unfair competition.
Result: The Ninth Circuit Court ruled in favor hiQ Labs, allowing them to scrape public LinkedIn profiles. The court determined that scraping publicly accessible data did not violate the Computer Fraud and Abuse Act (CFAA).
5. Zillow’s Legal Battles With Scrapers
Since 2013, Zillow has had some legal battles against web scraping services. It has consistently taken legal action to enforce its terms of service and protect its data.
Result: Zillow has won some cases against data scraping services accused of stealing real estate listings from Zillow’s website.
Dos and Don’ts of Legal and Ethical Web Scraping
From a legal and ethical perspective, individuals and businesses engaging in web scraping need to carefully evaluate their practices and ensure compliance with relevant laws.
Legal Considerations
It is vital to determine that the scraping activity does not disrupt the website’s services, which could otherwise lead to legal repercussions. Ensure the scraping goals are legal and focused on only publicly available information.
Ethical Considerations
When conducted responsibly, web scraping becomes a legitimate tool for business purposes. To reduce the load on the website, use proxy servers, and headless browsers. In general, from both legal and ethical perspectives, some dos and don’ts need to be understood and followed.
Dos of Ethical Scraping:
- Targeted Scraping: Scrape only necessary data specific to the needs to avoid overloading the website.
- Adherence to Terms of Use: Respect the website’s scraping permissions, consulting the terms of use and robot.txt file.
- Transparency: Be transparent in scraping methods and prepared to justify the legality and ethics of these practices.
Don’ts of Ethical Scraping:
- Avoid Excessive Scraping: Avoid scraping too frequently or extensively. This method also reduces the server load on the website.
- Handle Sensitive Information Carefully: Ensure to mask and process securely, personally identifiable information when scraping.
- Secure Storage of Scraped Data: The extracted data must be stored safely to prevent unauthorized use if it is leaked.
|
Ethical Web Scraping Guidelines |
Dos |
Don’ts |
|
Guideline 1 |
Targeted Scraping |
Avoid Excessive Scraping |
|
Guideline 2 |
Adherence to Terms of Use |
Careful Handling of Sensitive Information |
|
Guideline 3 |
Transparency in Methods |
Secure Storage of Scraped Data |
The Rules of Scraping Websites Legally
Web scraping public data is not illegal, but websites often face issues like breach of contract, copyright infringement, and fraud. Different types of agreements and policies could limit web scraping.
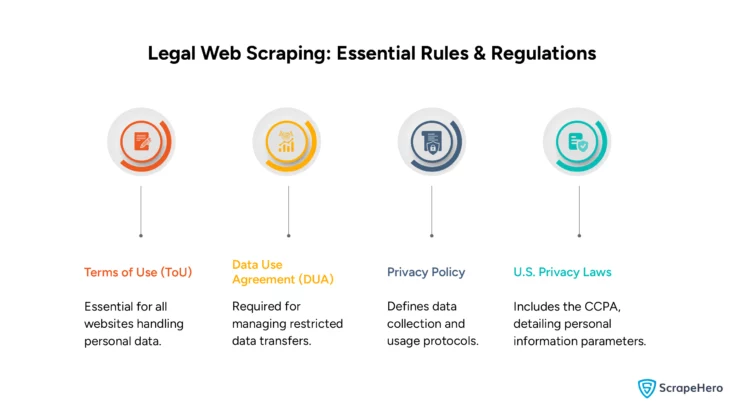
-
Terms of Use
Terms of Use (ToU), also known as Terms of Service or Terms and Conditions, is a legal agreement that users must follow when using a website or service. ToUs are a must for all websites that store personal information, especially on e-commerce and social media platforms.
-
Data Use Agreement
A Data Use Agreement (DUA) is a contract the Privacy Rule requires to govern the transfer of restricted or non-public data. It ensures the secure handling of the data developed by nonprofit, government, or private organizations if it is not public or restricted to use.
-
Privacy Policy
A Privacy Policy is a document that establishes how a website should collect, use, and protect users’ data. It advises website users to review these terms during registration. The policy also explains data usage, access, updates, and legal consequences for non-compliance across different regions.
-
The U.S. Privacy Act
The U.S. has many different state laws, such as California’s CCPA, which defines personal information extensively. There are also laws for specific sectors, such as the Health Insurance Portability and Accountability Act (HIPAA) for health and the Gramm-Leach-Bliley Act of 1999 (GLBA) for finance.
Best Practices for Legal and Ethical Web Scraping
Responsible web scraping requires adherence to both legal standards and ethical guidelines. To ensure legality, foster ethical responsibility, and maintain trust and compliance in operations, the users must consider some practices:

- Responsible Data Use: The data extracted should be used only for the declared purposes without infringement of any laws or ethical standards.
- Stay Informed: Get the legal updates and adjust scraping practices accordingly with new laws and court decisions.
- Data Governance: Establish clear and ethical guidelines for managing the data responsibly throughout its lifecycle.
- Rate Throttling: Control the scraping rate to prevent the website owner from thinking of it as a DDoS attack.
- Minimal Data Retention: To avoid potential legal and ethical issues with web scraping, save only the data necessary for the intended use.
- Avoid Sensitive Data: Avoid scraping private information and check the site’s robots.txt file to stay out of sensitive areas.
- User Agent String: Use a user agent string to identify the scraper and make it easier for the website owner to contact you if needed.
- Formal Data Collection Policy: Develop and adhere to a formal policy that clearly defines what data can be collected and used responsibly.
What Should You Consider When Looking for a Web Scraper Service?
The right web scraper service provider must ensure the service aligns with your business needs. Here are some key considerations for choosing a responsible and honest data web scraping service provider:

-
Legal Compliance
The web scraping service provider must adhere to the legal frameworks related to web scraping, such as copyright laws and data privacy regulations (e.g., GDPR, CCPA), and agree to the website’s Terms of Service and robots.txt files.
-
Ethical Considerations
The service provider should commit to ethical scraping practices, which include overloading website servers, respecting data privacy, and ensuring the use of data for legitimate purposes.
-
Data Quality and Accuracy
The web scraping service provider must ensure the quality and reliability of the collected and provided data, including handling dynamic content and error-checking processes.
-
Customization Capabilities and Scalability
The service should be adaptable and meet specific needs like custom data extraction, scraping frequency, and outputs, along with being scalable to handle increased data loads as required.
-
Technical Support and Customer Service
Providing good customer support is essential, especially when encountering technical issues. The provider should offer flexible support hours, respond quickly, and be an expert in the area.
-
Security and Reliability
The provider should ensure the security of the data collected, especially if it’s sensitive or personal data. They must also be Reliable and should handle any changes to the website.
-
Cost Effectiveness
Choose a provider that simultaneously meets the needs and fits within the budget requirements. Transparency in pricing is critical to ensure no hidden costs are involved in the entire process.
-
Reputation Reviews and Experience
The service provider’s reputation is another factor to check thoroughly. Check the performance and reliability of the provider through reviews, testimonials, and case studies. Industry-specific experience is also crucial for understanding specific sectors’ unique challenges and needs.
-
Data Handling and Export Options
The provider should handle data extraction, storage, and export, sticking to the specified formats. They should also have robust procedures for data management.
-
Compliance with Future Regulations
The web scraping service provider must stay up-to-date and follow new rules about data privacy and web scraping whenever there are changes in laws and regulations.
Closing Thoughts
It’s true that web scraping offers significant opportunities for businesses and individuals to gain invaluable insights and form strategic decisions. However, this practice has legal and ethical challenges because its rules are not fully established.
It is essential to ensure that web scraping is done responsibly and ethically. With the assistance of a reputed web scraping service like ScrapeHero, you can navigate the evolving digital landscape.
ScrapeHero web scraping services ensure that our web scraping practices are legal and ethical by complying with data protection laws, respecting website terms, adapting to legal changes, and securing collected data. Businesses can rely on us to meet their data scraping needs effectively and efficiently.
Frequently Asked Questions
It completely depends on the use of data, adherence to privacy laws, respect for website terms of service, and the impact on website performance.
Yes. If you violate a website’s terms of service, infringe on copyright, or access data against the provisions of laws like the Computer Fraud and Abuse Act, you can be sued.
Web scraping for commercial use can be legal, but it depends on the website’s terms of service, compliance with copyright laws, and relevant data protection regulations.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



