
Web scraping Amazon reviews can offer insightful data for market research, sentiment analysis, and competitive analysis. By building a Python scraper, you can extract product review data such as title, content, product name, rating, etc. from Amazon and export it into an Excel spreadsheet.
Through this article, learn to create a simple Amazon product review scraper using Python and SelectorLib. Later, run it on a console in order to extract all the details you need.
Steps for Web Scraping Amazon Reviews
- Markup the data fields to scrape using Selectorlib.
- Copy and run the code.
- Download the data in Excel or CSV file.
Data Fields To Scrape From Amazon

Here are some of the data fields that are obtained when scraping Amazon product reviews and extracted into a spreadsheet from Amazon:
- Product Name
- Review Title
- Review Content/Review Text
- Rating
- Date of Publishing Review
- Verified Purchase
- Author Name
- URL
Installation
For web scraping Amazon product reviews, install the required Python3 packages. The libraries mentioned are used:
- Python Requests – To make requests and download the HTML content of the pages
- LXML – To parse the HTML tree structure using XPaths
- Python Dateutil – To parse review dates
- Selectorlib – To extract data using the YAML file created from the web pages downloaded
Install these libraries using pip3
pip3 install python-dateutil lxml requests selectorlibThe Functionality of the Amazon Product Review Scraper
Here is what a scraper created for scraping Amazon product reviews does:
- It reads a list of product review page URLs from a file called urls.txt, which contains the URLs for the Amazon product pages you need.
- It uses a selectorlib YAML file that identifies the data on an Amazon page and is saved in a file called selectors.yml.
- Scrapes the data.
- Saves the data as a CSV spreadsheet called data.csv.
Creating the YAML File – selectors.yml
Using the Selectorlib Web Scraper Chrome Extension, you can mark the data that you need to extract. It also helps in creating the CSS selectors or XPaths needed to extract that data.
You can use the template created by ScrapeHero to extract the details already mentioned. But if you want to scrape more data fields, then add the new field using Selectorlib to the existing template.
Let’s consider an Amazon page: Nike Women’s Reax Run 5 Running Shoes
Mark up the fields for the data you need to scrape from the Amazon Product Reviews Page using the Selectorlib Chrome Extension.
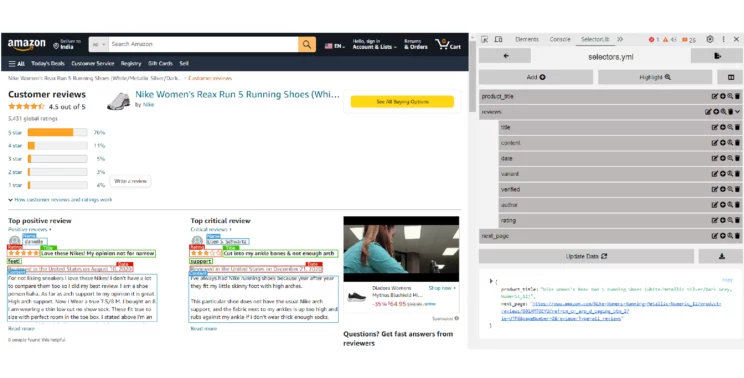
Click on ‘Highlight’ to highlight and preview all of your selectors in the template, and then click on ‘Export’ to download the YAML file, selectors.yml.
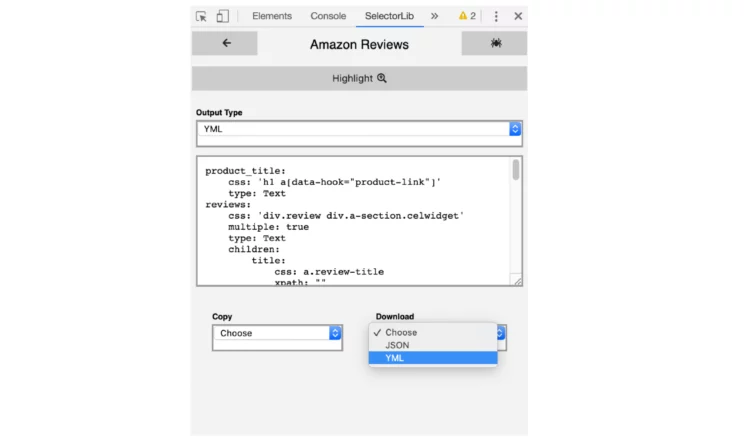
Here is how the template (selectors.yml) file looks:
product_title:
css: 'h1 a[data-hook="product-link"]'
type: Text
reviews:
css: 'div.review div.a-section.celwidget'
multiple: true
type: Text
children:
title:
css: a.review-title
type: Text
content:
css: 'div.a-row.review-data span.review-text'
type: Text
date:
css: span.a-size-base.a-color-secondary
type: Text
variant:
css: 'a.a-size-mini'
type: Text
images:
css: img.review-image-tile
multiple: true
type: Attribute
attribute: src
verified:
css: 'span[data-hook="avp-badge"]'
type: Text
author:
css: span.a-profile-name
type: Text
rating:
css: 'div.a-row:nth-of-type(2) > a.a-link-normal:nth-of-type(1)'
type: Attribute
attribute: title
next_page:
css: 'li.a-last a'
type: Link
The Code
Let’s create a file called reviews.py and paste the Python code into it.
from selectorlib import Extractor
import requests
import json
from time import sleep
import csv
from dateutil import parser as dateparser
# Create an Extractor by reading from the YAML file
e = Extractor.from_yaml_file('selectors.yml')
def scrape(url):
headers = {
'authority': 'www.amazon.com',
'pragma': 'no-cache',
'cache-control': 'no-cache',
'dnt': '1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (X11; CrOS x86_64 8172.45.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.64 Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'sec-fetch-site': 'none',
'sec-fetch-mode': 'navigate',
'sec-fetch-dest': 'document',
'accept-language': 'en-GB,en-US;q=0.9,en;q=0.8',
}
# Download the page using requests
print("Downloading %s"%url)
r = requests.get(url, headers=headers)
# Simple check to check if page was blocked (Usually 503)
if r.status_code > 500:
if "To discuss automated access to Amazon data please contact" in r.text:
print("Page %s was blocked by Amazon. Please try using better proxies\n"%url)
else:
print("Page %s must have been blocked by Amazon as the status code was %d"%(url,r.status_code))
return None
# Pass the HTML of the page and create
return e.extract(r.text)
with open("urls.txt",'r') as urllist, open('data.csv','w') as outfile:
writer = csv.DictWriter(outfile, fieldnames=["title","content","date","variant","images","verified","author","rating","product","url"],quoting=csv.QUOTE_ALL)
writer.writeheader()
for url in urllist.readlines():
data = scrape(url)
if data:
for r in data['reviews']:
r["product"] = data["product_title"]
r['url'] = url
if 'verified' in r:
if 'Verified Purchase' in r['verified']:
r['verified'] = 'Yes'
else:
r['verified'] = 'Yes'
r['rating'] = r['rating'].split(' out of')[0]
date_posted = r['date'].split('on ')[-1]
if r['images']:
r['images'] = "\n".join(r['images'])
r['date'] = dateparser.parse(date_posted).strftime('%d %b %Y')
writer.writerow(r)
# sleep(5)
Get the complete code for scraping Amazon reviews on GitHub
Running the Amazon Review Scraper
Now you should add the URLs you need to scrape into a text file called urls.txt in the same folder where you saved the code. Then run the scraper using the command:
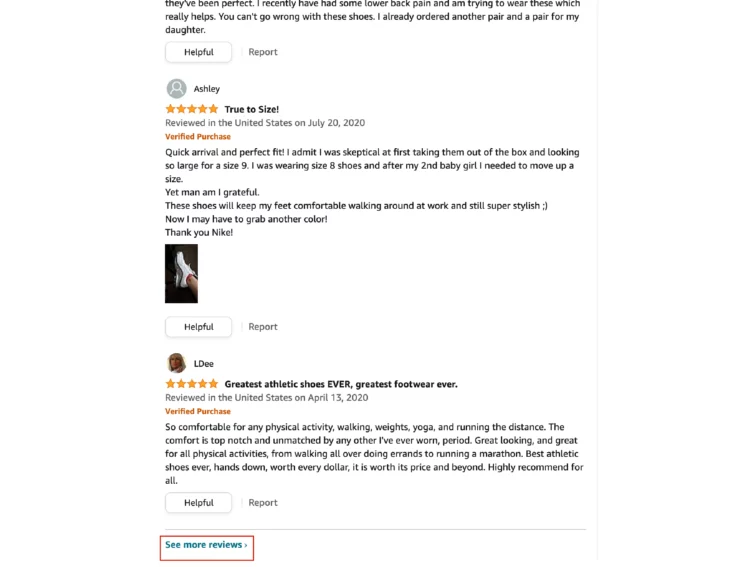
python3 reviews.pyAs mentioned earlier, the Amazon page for Nike Women’s Reax Run 5 Running Shoes is considered here. You can get this URL by clicking on “See more reviews” near the bottom of the product page.
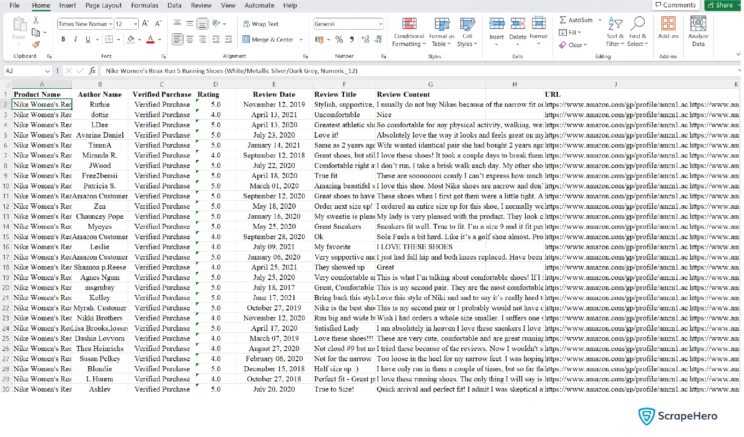
The results obtained after scraping Amazon reviews using Python:
Use Cases for Scraping Amazon Reviews
The data that you gather from scraping Amazon reviews can help you:
- Monitoring customer opinions on products that you sell or manufacture using data analysis
- Monitor product quality sold by third-party sellers
- Create Amazon review datasets for educational purposes and research
ScrapeHero Amazon Product Reviews Scraper and Amazon Review API
Using ScrapeHero Cloud can be a better alternative to a Python Amazon product review scraper that you have created. This is because the structure of the Amazon website may change over time, and the current Python scraper you have created may have to be updated.
In such scenarios, prebuilt scrapers such as ScrapeHero Amazon Product Reviews Scraper can save you time and money. All you have to do is provide ASINs or product page URLs. That’s it. Moreover, our prebuilt scrapers allow you to configure your needs and fetch the data without any dedicated teams or hosting infrastructure.
You can also try using the ScrapeHero Amazon Product Reviews and Ratings API, which can be easily integrated into your application and stream extracted data seamlessly. It can also avoid the IP bans and captchas that Amazon implements when detecting web crawlers.
If you want to explore our scrapers related to scraping Amazon, try out:
- ScrapeHero Amazon Product Details and Pricing Scraper
- ScrapeHero Amazon Search Results Scraper
- ScrapeHero Amazon Best Sellers Scraper
- ScrapeHero Amazon Product Offers and Third Party Sellers Scraper
- ScrapeHero Amazon Customer FAQ Scraper
Wrapping Up
Creating a scraper for Amazon product reviews in Python can be challenging for beginners, especially when dealing with complex issues like dynamic content and anti-scraping measures. But you can also scrape Amazon reviews without any coding on your part.
Keep in mind that the scraper discussed in this article is used to scrape Amazon reviews of a relatively small number of ASINs for your personal web scraping needs.
If you plan on running web scrapers on a larger scale, then ScrapeHero web scraping services would be more suitable. Businesses can rely on ScrapeHero to meet their data scraping needs effectively and efficiently as we manage data volume, providing clean, structured, and relevant data.
Frequently Asked Questions
Yes, you can scrape Amazon reviews using Python. You can do it either with libraries such as BeautifulSoup, Selenium, or Requests or with APIs such as ScrapeHero’s Amazon reviews API.
Web scraping Amazon reviews using Python with BeautifulSoup includes installing the BeautifulSoup4 and Requests libraries, sending HTTP requests to the Amazon product page, parsing the HTML content, and extracting the desired information.
Scraping Amazon product reviews using Python with Selenium involves automating a web browser to interact with the Amazon website, navigating through the product reviews, and extracting the data. It is better to use Selenium when dealing with JavaScript-generated dynamic content, which is standard on Amazon’s review pages.
An Amazon review scraper Chrome extension is a browser add-on designed to extract reviews from Amazon product pages. It can collect review data, such as ratings and comments, which is later used for analysis or monitoring purposes.
You will get a free Amazon review scraper from ScrapeHero Cloud, which you can avail of using the 25 free credits that you get during signup. ScrapeHero scrapers are fast, reliable, easy to use, and do not require coding on the user side. Apart from that, you can also find free code to scrape Amazon reviews in Python on GitHub.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data


