

Google reviews are easy to read—but surprisingly hard to collect at scale.
You can manually check a few listings. But the moment you want to:
- track sentiment across multiple locations
- monitor competitors consistently
- or build a usable dataset
manual workflows stop being practical.
Google doesn’t provide a straightforward way to export reviews in bulk, and its APIs only return a limited subset of data. That’s where scraping becomes necessary—but also introduces its own challenges.
In this guide, you’ll see two ways to get Google review data:
By the end, you’ll not only know how to extract the data—but also which approach actually makes sense for your situation.
Why Scrape Google Reviews? Top Business Use Cases
Businesses across industries rely on review data to make faster, better-informed decisions. Here are the most common use cases of scraping Google reviews at scale.
- Reputation monitoring lets brands track what customers are saying in near real time, flagging negative sentiment before it compounds. Instead of manually checking listings, teams can pipe extracted reviews into dashboards or alerting systems.
- Competitor analysis is one of the clearest wins. If you can pull reviews from your competitors’ Google listings regularly, you start to see patterns: recurring complaints, praised features, and service gaps you can exploit.
- Sentiment analysis and NLP pipelines need large volumes of real-world text. Google reviews, being short, opinionated, and topic-specific, are ideal training data or inference inputs for classification models.
- Local SEO and listing audits benefit from structured review data. Agencies managing multiple client listings use scraped reviews to benchmark rating trends over time and identify listings that need attention.
- Market research firms use review data to understand consumer preferences across geographies, categories, and price points without running surveys.
The Google Places API 5-Review Limit—and Why It’s a Problem
If you’ve tried using the Google Places API to collect reviews, you’ve probably run into a hard limitation: it only returns up to 5 reviews per place.
Google prioritizes what it considers the “most relevant” or “most helpful” reviews, which is useful for display but not for analysis.
Why This Becomes a Bottleneck
For most real-world use cases, 5 reviews isn’t enough:
- You can’t run meaningful sentiment analysis on such a small sample
- You miss recurring complaints or patterns
- You can’t track how reviews change over time
- Competitor comparisons become unreliable
In other words, the API is designed for quick lookups, not data collection at scale.
How to Get Around It
To access a larger volume of reviews, you need to go beyond the API and extract data directly from the rendered review interface.
That’s where scraping-based approaches come in:
- A custom Python script can automate the browser and extract reviews
- A ready-made solution like ScrapeHero Cloud handles this process at scale without requiring you to maintain the Google review scraper
- A web scraping company can extract reviews at scale, managing infrastructure and anti-bot challenges so you don’t have to
If your goal is to analyze hundreds or thousands of reviews the API alone won’t get you there.

Scrape Google Reviews Using Python
When you scrape Google Map reviews for a business or place, each review entry typically contains the following fields:
- Author name is the display name of the person who left the review. This is useful for deduplication and tracking repeat reviewers.
- Review text is the written feedback from the reviewer. This is the primary data point for sentiment analysis, topic extraction, and competitive intelligence.
- Star rating is the numerical rating associated with the review, usually expressed as a label like “Rated 4 out of 5.” This makes it easy to segment reviews by satisfaction level.
Depending on the target page, you can also find review dates, reviewer profile links, and helpfulness votes, though the script in this guide focuses on the three core fields above.
Setting Up the Environment
This script uses Playwright, an async browser automation library, as its core dependency. You will also need Python 3.8 or later.
Install the required packages by running the following in your terminal:
pip install playwright
playwright install
Playwright downloads browser binaries during installation. By default it includes Chromium, Firefox, and WebKit. The script uses Microsoft Edge specifically, so make sure Edge is installed on your machine. If Edge is not available, you can switch the channel argument to “chromium” in the browser context setup.
No additional libraries beyond the Python standard library are required. The script uses asyncio, json, and pathlib, all of which ship with Python.
Code to Scrape Google Reviews With Python
Before diving into the implementation, here’s a simplified view of how the scraper works end-to-end:
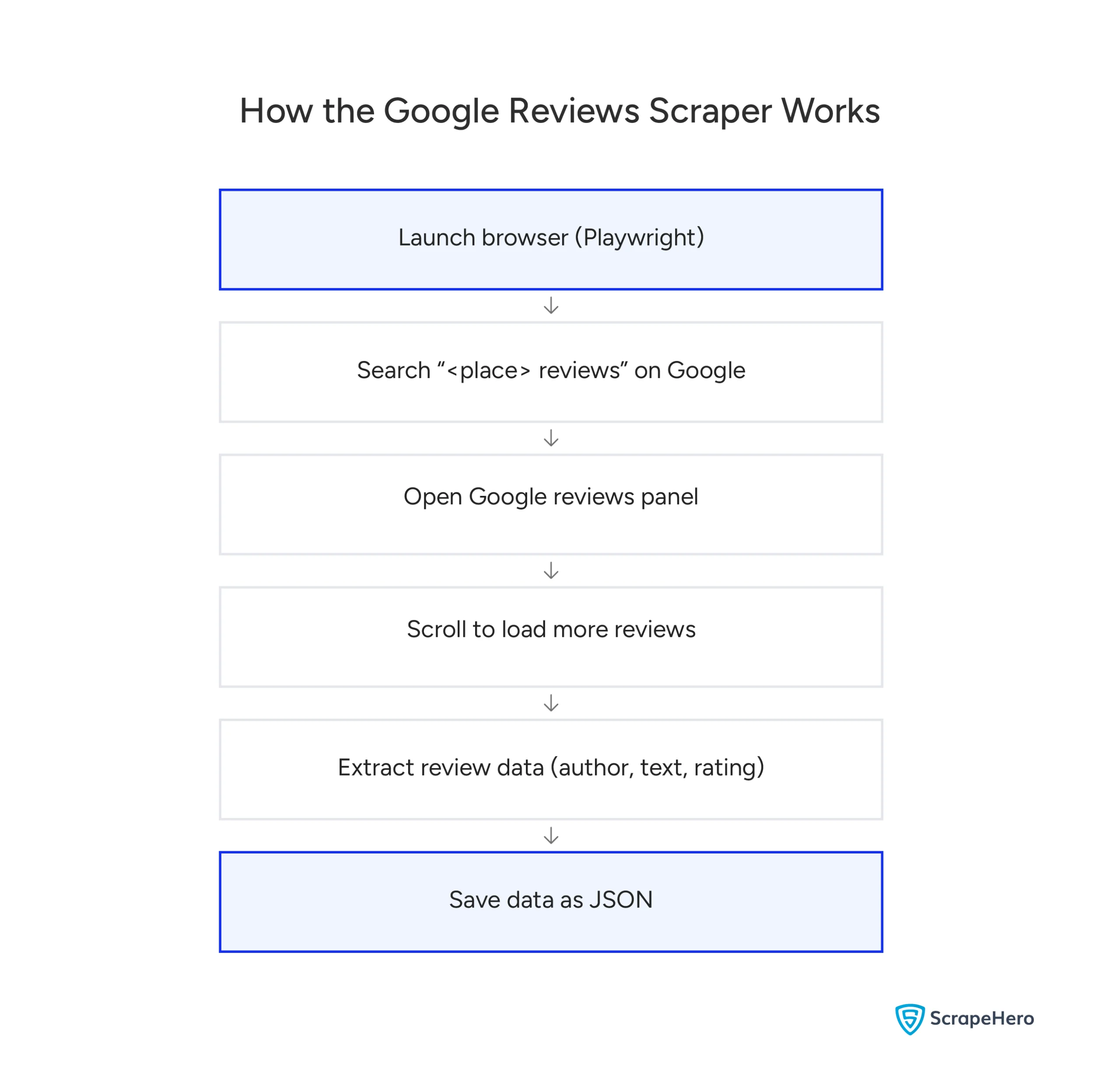
If you’re in a hurry, here’s the complete code.
import asyncio
import json
from pathlib import Path
from playwright.async_api import Playwright, async_playwright
USER_DATA_DIR = Path(__file__).with_name("user_data")
USER_AGENT = (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/120.0.0.0 Safari/537.36"
)
async def wait_if_captcha(page) -> None:
"""
Gives the user time to solve Google's CAPTCHA/unusual-traffic page manually.
"""
body_text = await page.locator("body").inner_text()
captcha_terms = (
"unusual traffic",
"not a robot",
"captcha",
"our systems have detected",
)
if any(term in body_text.lower() for term in captcha_terms):
print("Google CAPTCHA detected. Solve it in the browser window.")
print("The script will wait up to 2 minutes before continuing.")
for _ in range(24):
await page.wait_for_timeout(5000)
body_text = await page.locator("body").inner_text()
if not any(term in body_text.lower() for term in captcha_terms):
return
async def extract_data(page) -> list:
"""
Extracts the results information from the page
Args:
page: Playwright page object
Returns:
A list containing details of results as a dictionary. The dictionary
has title, review count, rating, address of various results
"""
review_box = page.locator("div.bwb7ce")
await review_box.first.wait_for(timeout=30000)
data = []
for result_elem in await review_box.all():
more_button = result_elem.get_by_role("button",name="More")
count = await more_button.count()
if count:
await more_button.click()
await result_elem.wait_for(timeout=3000)
review_locator = result_elem.locator("div.OA1nbd")
author_locator = result_elem.locator("div.Vpc5Fe").first
rating_locator = result_elem.locator("div.dHX2k")
review = await review_locator.inner_text() if await review_locator.count() else ""
author_name = (
await author_locator.inner_text() if await author_locator.count() else None
)
rating = (
await rating_locator.get_attribute("aria-label")
if await rating_locator.count()
else None
)
rating = rating.strip(", ") if rating else None
data.append(
{
"author_name": author_name,
"review": review,
"rating": rating,
}
)
return data
async def run(playwright: Playwright) -> None:
"""
Main function which launches browser instance and performs browser
interactions
Args:
playwright: Playwright instance
"""
USER_DATA_DIR.mkdir(exist_ok=True)
context = await playwright.chromium.launch_persistent_context(
user_data_dir=str(USER_DATA_DIR),
headless=False,
user_agent=USER_AGENT,
viewport={"width": 1920, "height": 1080},
java_script_enabled=True,
locale="en-US",
timezone_id="America/New_York",
permissions=["geolocation"],
bypass_csp=True,
ignore_https_errors=True,
channel="msedge",
args=[
"--disable-blink-features=AutomationControlled",
"--disable-automation",
"--disable-infobars",
"--disable-dev-shm-usage",
"--no-sandbox",
"--disable-gpu",
"--disable-setuid-sandbox",
],
)
page = await context.new_page()
# Go to https://www.google.com/
await page.goto("https://www.google.com/", wait_until="domcontentloaded")
await wait_if_captcha(page)
# Type search query
search_term = "eiffel tower"
await page.locator('textarea[name="q"], input[name="q"]').first.type(search_term+" reviews")
# Press enter to search in google
await page.keyboard.press("Enter")
await page.wait_for_load_state("domcontentloaded")
await wait_if_captcha(page)
reviews_button = page.get_by_role('button',name="Google reviews").first
await reviews_button.click()
await asyncio.sleep(4)
await wait_if_captcha(page)
# Load reviews using infinite scroll
max_reviews = 25 # Set the maximum number of reviews to load
previous_count = 0
while previous_count < max_reviews: reviews = page.locator("div.bwb7ce") current_count = await reviews.count() if current_count == previous_count or current_count >= max_reviews:
break
if current_count > 0:
await reviews.last.scroll_into_view_if_needed()
await reviews.last.hover()
await page.mouse.wheel(0, 100000)
await page.wait_for_timeout(10000)
previous_count = current_count
# Extract all displayed reviews
data = await extract_data(page)
# Save all extracted data as a JSON file
with open("google_reviews.json", "w", encoding="utf-8") as f:
json.dump(data, f, indent=2, ensure_ascii=False)
# ---------------------
await context.close()
async def main() -> None:
async with async_playwright() as playwright:
await run(playwright)
asyncio.run(main())
The script follows the same flow shown above, broken down into four logical parts: configuration, CAPTCHA handling, data extraction, and the main browser automation routine.
Let’s walk through each part to see how the scraper works in practice.
Start by importing the necessary modules and defining the constants the script will use throughout.
import asyncio
import json
from pathlib import Path
from playwright.async_api import Playwright, async_playwright
USER_DATA_DIR = Path(__file__).with_name("user_data")
USER_AGENT = (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/120.0.0.0 Safari/537.36"
)
USER_DATA_DIR points to a folder called user_data in the same directory as the script. Playwright uses this as a persistent profile, which means cookies, localStorage, and login state are preserved between runs. The USER_AGENT string mimics a real Windows Chrome browser so that the requests look more like organic traffic.
Next, define the function that detects and waits out Google CAPTCHAs.
async def wait_if_captcha(page) -> None:
body_text = await page.locator("body").inner_text()
captcha_terms = (
"unusual traffic",
"not a robot",
"captcha",
"our systems have detected",
)
if any(term in body_text.lower() for term in captcha_terms):
print("Google CAPTCHA detected. Solve it in the browser window.")
print("The script will wait up to 2 minutes before continuing.")
for _ in range(24):
await page.wait_for_timeout(5000)
body_text = await page.locator("body").inner_text()
if not any(term in body_text.lower() for term in captcha_terms):
return
This function reads the full text of the page body and checks it against a list of phrases commonly associated with Google’s bot detection pages. If a match is found, the script pauses in five-second intervals for up to two minutes, giving you time to solve the CAPTCHA manually in the open browser window. This is one of the more practical design decisions in a google review scraper meant for personal or low-volume use.
Want to solve CAPTCHA automatically, read our article on solving CAPTCHA using Python Tesseract.
Now define the function that reads the review elements from the DOM and structures the data.
async def extract_data(page) -> list:
review_box = page.locator("div.bwb7ce")
await review_box.first.wait_for(timeout=30000)
data = []
for result_elem in await review_box.all():
more_button = result_elem.get_by_role("button", name="More")
count = await more_button.count()
if count:
await more_button.click()
await result_elem.wait_for(timeout=3000)
review_locator = result_elem.locator("div.OA1nbd")
author_locator = result_elem.locator("div.Vpc5Fe").first
rating_locator = result_elem.locator("div.dHX2k")
review = await review_locator.inner_text() if await review_locator.count() else ""
author_name = (
await author_locator.inner_text() if await author_locator.count() else None
)
rating = (
await rating_locator.get_attribute("aria-label")
if await rating_locator.count()
else None
)
rating = rating.strip(", ") if rating else None
data.append(
{
"author_name": author_name,
"review": review,
"rating": rating,
}
)
return dataThe function waits up to 30 seconds for the first review card to appear before proceeding, which prevents errors when the page is slow to load. For each review card, it checks for a “More” button and clicks it if present, which expands truncated review text before extraction. The three CSS class selectors target the review text, author name, and rating label respectively. These class names are specific to Google’s current DOM structure and are the most fragile part of the script as they can change without notice.
Now write the main browser automation function, starting with launching the browser context.
async def run(playwright: Playwright) -> None:
USER_DATA_DIR.mkdir(exist_ok=True)
context = await playwright.chromium.launch_persistent_context(
user_data_dir=str(USER_DATA_DIR),
headless=False,
user_agent=USER_AGENT,
viewport={"width": 1920, "height": 1080},
java_script_enabled=True,
locale="en-US",
timezone_id="America/New_York",
permissions=["geolocation"],
bypass_csp=True,
ignore_https_errors=True,
channel="msedge",
args=[
"--disable-blink-features=AutomationControlled",
"--disable-automation",
"--disable-infobars",
"--disable-dev-shm-usage",
"--no-sandbox",
"--disable-gpu",
"--disable-setuid-sandbox",
],
)
The context is launched with headless=False, meaning you can see the browser window. This is important for CAPTCHA handling. The –disable-blink-features=AutomationControlled flag removes a JavaScript property that some sites use to detect Playwright-driven browsers. The combination of locale, timezone, geolocation permissions, and a realistic viewport helps the browser fingerprint look more human.
With the browser open, navigate to Google and submit a search query.
page = await context.new_page()
await page.goto("https://www.google.com/", wait_until="domcontentloaded")
await wait_if_captcha(page)
search_term = "eiffel tower"
await page.locator('textarea[name="q"], input[name="q"]').first.type(search_term + " reviews")
await page.keyboard.press("Enter")
await page.wait_for_load_state("domcontentloaded")
await wait_if_captcha(page)
reviews_button = page.get_by_role('button', name="Google reviews").first
await reviews_button.click()
await asyncio.sleep(4)
await wait_if_captcha(page)
The script navigates to Google’s homepage and types the search term into the search box, appending “reviews” to trigger the reviews panel in the knowledge graph. After the results load, it clicks the “Google reviews” button, which opens a scrollable panel of reviews. The four-second sleep gives the panel time to render before the next step.
With the reviews panel open, use infinite scrolling to load more reviews before extracting them.
max_reviews = 25
previous_count = 0
while previous_count < max_reviews: reviews = page.locator("div.bwb7ce") current_count = await reviews.count() if current_count == previous_count or current_count >= max_reviews:
break
if current_count > 0:
await reviews.last.scroll_into_view_if_needed()
await reviews.last.hover()
await page.mouse.wheel(0, 100000)
await page.wait_for_timeout(10000)
previous_count = current_count
This loop checks the number of loaded review cards on each iteration. If the count stops growing or reaches the max_reviews limit, the loop exits. Otherwise it scrolls the last visible card into view, hovers over it, and dispatches a large mouse wheel event to trigger lazy-loading of additional reviews. The 10-second wait gives the page time to fetch and render the next batch.
Finally, call the extraction function and save the results to disk.
data = await extract_data(page)
with open("google_reviews.json", "w", encoding="utf-8") as f:
json.dump(data, f, indent=2, ensure_ascii=False)
await context.close()
async def main() -> None:
async with async_playwright() as playwright:
await run(playwright)
asyncio.run(main())
The extracted list of dictionaries is written to a google_reviews.json file in the working directory. Setting ensure_ascii=False preserves non-ASCII characters like accented letters and emoji, which frequently appear in user-generated review text.
The main function wraps everything in an async context manager and serves as the entry point.
Code Limitations
This script works well as a proof of concept but has meaningful constraints you should understand before relying on it in production.
- CSS class selectors break with DOM updates. Google frequently changes its frontend markup. The class names bwb7ce, OA1nbd, Vpc5Fe, and dHX2k are tied to a specific version of Google’s rendered HTML. When these change, the script stops extracting data correctly until someone manually inspects the page and updates the selectors.
- It runs in a single browser tab sequentially. The script processes one search term and one review panel per run. Scaling to hundreds of business listings requires significant refactoring, including concurrency management and rotating browser contexts.
- CAPTCHAs require human intervention. The wait logic gives you time to solve CAPTCHAs manually, but this is not a sustainable pattern for automated pipelines. Any unattended run that hits a CAPTCHA will stall.
- No proxy support is included. Running this script repeatedly from the same IP will trigger rate limiting and CAPTCHA challenges faster. Adding proxy rotation is necessary for any volume above a handful of searches per session.
At this point, you have a working understanding of how to scrape Google reviews using Python.
For one-off projects or small datasets, this approach works well. You control the logic, the extraction, and the output format.
But as soon as you move beyond that the tradeoffs start to show:
- Selectors break when Google updates its UI
- CAPTCHAs interrupt automated runs
- Scaling requires proxies, concurrency, and infrastructure
What starts as a script quickly turns into a system you have to maintain.
If you’d rather skip that layer entirely, there’s a simpler way to get the same data.
Scrape Google Reviews Without Coding (No-Code Method)
If you don’t want to build and maintain a scraping pipeline yourself, tools like ScrapeHero Cloud’s Google Review Scraper can handle most of the work for you.
Instead of writing scripts, debugging selectors, and dealing with CAPTCHAs, you provide a Google Reviews URL or Place ID, and the system takes care of extraction, scaling, and delivery.
What You Get
The output is a structured dataset that’s ready for analysis, reporting, or integration into your systems.
Each record collected by ScrapeHero Cloud includes:
- Review content: review body, original text, images, response from owner
- Reviewer details: author name, local guide status
- Ratings data: review rating, maximum rating, aggregate rating
- Business context: business name, address, place ID, business URL
- Metadata & tracking: review URL, review source, input query
- Time data: posted date, accurate date, review count
This structure makes it easy to:
- run sentiment analysis or NLP pipelines
- track rating trends over time
- compare locations or competitors
- audit responses from business owners
Instead of cleaning and enriching the data yourself, you get a dataset that’s already usable.
Sample Data from ScrapeHero Cloud’s Google Review Scraper
| author | isLocalGuide | reviewBody | reviewRating | ratingMaxvalue | reviewTags | dateCreated | accurateDate | images | reviewUrl | reviewSource | originalText | responseFromOwner | name | reviewCount | aggregateRating | address | place_id | input | businessUrl |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Romuald Duplat | True | 5.0 | 5.0 | Order type: Take out | Price per person: $10–20 | Food: 5 | Service: 5 | Atmosphere: 5 | Wait time: No wait | Seating type: Indoor dining area | a week ago | 2026-05-14 | https://www.google.com/maps/reviews/data=!4m8!14m7!1m6!2m5!1sCi9DQUlRQUNvZENodHljRjlvT21KSVJtZGtUbVJzVG1KQlgzSm1iMmRYZDI4MGJGRRAB!2m1!1s0x0:0x6e3298283c775bb0!3m1!1s2@1:CAIQACodChtycF9oOmJIRmdkTmRsTmJBX3Jmb2dXd280bFE%7C%7C?hl=en | www.google.com | KFC | 1077 | 3.1 | 798-812 4th Ave, Brooklyn, NY 11232 | ChIJIwnh7ulawokRsFt3PCiYMm4 | https://www.google.com/search?newwindow=1&sca_esv=cb0ef06c41fe51d8&cs=0&output=search&kgmid=/g/1trxfm7c&q=KFC&shem=rimspwouoe&shndl=30&source=sh/x/loc/uni/m1/1&kgs=5d1cba8489df35b1&utm_source=rimspwouoe,sh/x/loc/uni/m1/1#lrd=0x89c25ae9eee10923:0x6e3298283c775bb0,1,,,, | https://www.google.com/maps/place/KFC,+798-812+4th+Ave,+Brooklyn,+NY+11232/@40.6592293,-73.9998152,3027a,13.1y/data=!4m2!3m1!1s0x89c25ae9eee10923:0x6e3298283c775bb0 | ||||
| Gregory | False | Bad attitude during drive through along with them waiting until you arrive to start making the food. Makes no sense at all. | 1.0 | 5.0 | Order type: Take out | Meal type: Dinner | Price per person: $20–30 | Food: 5 | Service: 1 | Atmosphere: 1 | Wait time: Up to 10 min | a week ago | 2026-05-08 | https://www.google.com/maps/reviews/data=!4m8!14m7!1m6!2m5!1sCi9DQUlRQUNvZENodHljRjlvT25sdU9YVjJkblJUYVZWQ1psTmFWREZKWmsxVWEwRRAB!2m1!1s0x0:0x6e3298283c775bb0!3m1!1s2@1:CAIQACodChtycF9oOnluOXV2dnRTaVVCZlNaVDFJZk1Ua0E%7C%7C?hl=en | www.google.com | Bad attitude during drive through along with them waiting until you arrive to start making the food. Makes no sense at all. | KFC | 1077 | 3.1 | 798-812 4th Ave, Brooklyn, NY 11232 | ChIJIwnh7ulawokRsFt3PCiYMm4 | https://www.google.com/search?newwindow=1&sca_esv=cb0ef06c41fe51d8&cs=0&output=search&kgmid=/g/1trxfm7c&q=KFC&shem=rimspwouoe&shndl=30&source=sh/x/loc/uni/m1/1&kgs=5d1cba8489df35b1&utm_source=rimspwouoe,sh/x/loc/uni/m1/1#lrd=0x89c25ae9eee10923:0x6e3298283c775bb0,1,,,, | https://www.google.com/maps/place/KFC,+798-812+4th+Ave,+Brooklyn,+NY+11232/@40.6592293,-73.9998152,3027a,13.1y/data=!4m2!3m1!1s0x89c25ae9eee10923:0x6e3298283c775bb0 | ||
| Sanae A | True | 2.0 | 5.0 | Food: 3 | Service: 3 | Atmosphere: 3 | Edited 14 hours ago | 2026-05-21 | https://www.google.com/maps/reviews/data=!4m8!14m7!1m6!2m5!1sChdDSUhNMG9nS0VJQ0FnSURLLWEzUG93RRAB!2m1!1s0x0:0x6e3298283c775bb0!3m1!1s2@1:CIHM0ogKEICAgIDK-a3PowE%7C%7C?hl=en | www.google.com | KFC | 1077 | 3.1 | 798-812 4th Ave, Brooklyn, NY 11232 | ChIJIwnh7ulawokRsFt3PCiYMm4 | https://www.google.com/search?newwindow=1&sca_esv=cb0ef06c41fe51d8&cs=0&output=search&kgmid=/g/1trxfm7c&q=KFC&shem=rimspwouoe&shndl=30&source=sh/x/loc/uni/m1/1&kgs=5d1cba8489df35b1&utm_source=rimspwouoe,sh/x/loc/uni/m1/1#lrd=0x89c25ae9eee10923:0x6e3298283c775bb0,1,,,, | https://www.google.com/maps/place/KFC,+798-812+4th+Ave,+Brooklyn,+NY+11232/@40.6592293,-73.9998152,3027a,13.1y/data=!4m2!3m1!1s0x89c25ae9eee10923:0x6e3298283c775bb0 | ||||
| Kevin Christian | False | Today I went to KFC 11:15pm online shows closing time 12min night But they say we closed | 1.0 | 5.0 | Order type: Take out | Meal type: Lunch | Price per person: $1–10 | Edited a week ago | 2026-05-15 | https://www.google.com/maps/reviews/data=!4m8!14m7!1m6!2m5!1sChdDSUhNMG9nS0VJQ0FnSUR4NE5UeDZ3RRAB!2m1!1s0x0:0x6e3298283c775bb0!3m1!1s2@1:CIHM0ogKEICAgIDx4NTx6wE%7C%7C?hl=en | www.google.com | Today I went to KFC 11:15pm online shows closing time 12min night But they say we closed | KFC | 1077 | 3.1 | 798-812 4th Ave, Brooklyn, NY 11232 | ChIJIwnh7ulawokRsFt3PCiYMm4 | https://www.google.com/search?newwindow=1&sca_esv=cb0ef06c41fe51d8&cs=0&output=search&kgmid=/g/1trxfm7c&q=KFC&shem=rimspwouoe&shndl=30&source=sh/x/loc/uni/m1/1&kgs=5d1cba8489df35b1&utm_source=rimspwouoe,sh/x/loc/uni/m1/1#lrd=0x89c25ae9eee10923:0x6e3298283c775bb0,1,,,, | https://www.google.com/maps/place/KFC,+798-812+4th+Ave,+Brooklyn,+NY+11232/@40.6592293,-73.9998152,3027a,13.1y/data=!4m2!3m1!1s0x89c25ae9eee10923:0x6e3298283c775bb0 | ||
| oscar hernandez | True | 5.0 | 5.0 | Food: 5 | Service: 5 | Atmosphere: 5 | a week ago | 2026-05-10 | https://www.google.com/maps/reviews/data=!4m8!14m7!1m6!2m5!1sCi9DQUlRQUNvZENodHljRjlvT2tSbVpXMU1aWEV6TkVKc1gwWjZSVEV3WTA5VFRtYxAB!2m1!1s0x0:0x6e3298283c775bb0!3m1!1s2@1:CAIQACodChtycF9oOkRmZW1MZXEzNEJsX0Z6RTEwY09TTmc%7C%7C?hl=en | www.google.com | KFC | 1077 | 3.1 | 798-812 4th Ave, Brooklyn, NY 11232 | ChIJIwnh7ulawokRsFt3PCiYMm4 | https://www.google.com/search?newwindow=1&sca_esv=cb0ef06c41fe51d8&cs=0&output=search&kgmid=/g/1trxfm7c&q=KFC&shem=rimspwouoe&shndl=30&source=sh/x/loc/uni/m1/1&kgs=5d1cba8489df35b1&utm_source=rimspwouoe,sh/x/loc/uni/m1/1#lrd=0x89c25ae9eee10923:0x6e3298283c775bb0,1,,,, | https://www.google.com/maps/place/KFC,+798-812+4th+Ave,+Brooklyn,+NY+11232/@40.6592293,-73.9998152,3027a,13.1y/data=!4m2!3m1!1s0x89c25ae9eee10923:0x6e3298283c775bb0 | ||||
| felix soto | True | It ws my 2nd time in 20 yrs...not a friendly staff member, especially the mgr. | 1.0 | 5.0 | Order type: Dine in | Price per person: $10–20 | Food: 2 | Service: 2 | Atmosphere: 2 | 3 weeks ago | 2026-04-30 | https://www.google.com/maps/reviews/data=!4m8!14m7!1m6!2m5!1sCi9DQUlRQUNvZENodHljRjlvT21NMlRHWkRTbVJ1V0dsQ1dEWXRVblpTUzBVdFluYxAB!2m1!1s0x0:0x6e3298283c775bb0!3m1!1s2@1:CAIQACodChtycF9oOmM2TGZDSmRuWGlCWDYtUnZSS0UtYnc%7C%7C?hl=en | www.google.com | It ws my 2nd time in 20 yrs...not a friendly staff member, especially the mgr. | KFC | 1077 | 3.1 | 798-812 4th Ave, Brooklyn, NY 11232 | ChIJIwnh7ulawokRsFt3PCiYMm4 | https://www.google.com/search?newwindow=1&sca_esv=cb0ef06c41fe51d8&cs=0&output=search&kgmid=/g/1trxfm7c&q=KFC&shem=rimspwouoe&shndl=30&source=sh/x/loc/uni/m1/1&kgs=5d1cba8489df35b1&utm_source=rimspwouoe,sh/x/loc/uni/m1/1#lrd=0x89c25ae9eee10923:0x6e3298283c775bb0,1,,,, | https://www.google.com/maps/place/KFC,+798-812+4th+Ave,+Brooklyn,+NY+11232/@40.6592293,-73.9998152,3027a,13.1y/data=!4m2!3m1!1s0x89c25ae9eee10923:0x6e3298283c775bb0 | ||
| Begaiym | False | 5.0 | 5.0 | Food: 5 | Service: 5 | Atmosphere: 5 | 4 days ago | 2026-05-18 | https://www.google.com/maps/reviews/data=!4m8!14m7!1m6!2m5!1sCi9DQUlRQUNvZENodHljRjlvT21sb05saE5NemhwUVZaSGJXWnBWRGM1UTFJME5VRRAB!2m1!1s0x0:0x6e3298283c775bb0!3m1!1s2@1:CAIQACodChtycF9oOmloNlhNMzhpQVZHbWZpVDc5Q1I0NUE%7C%7C?hl=en | www.google.com | KFC | 1077 | 3.1 | 798-812 4th Ave, Brooklyn, NY 11232 | ChIJIwnh7ulawokRsFt3PCiYMm4 | https://www.google.com/search?newwindow=1&sca_esv=cb0ef06c41fe51d8&cs=0&output=search&kgmid=/g/1trxfm7c&q=KFC&shem=rimspwouoe&shndl=30&source=sh/x/loc/uni/m1/1&kgs=5d1cba8489df35b1&utm_source=rimspwouoe,sh/x/loc/uni/m1/1#lrd=0x89c25ae9eee10923:0x6e3298283c775bb0,1,,,, | https://www.google.com/maps/place/KFC,+798-812+4th+Ave,+Brooklyn,+NY+11232/@40.6592293,-73.9998152,3027a,13.1y/data=!4m2!3m1!1s0x89c25ae9eee10923:0x6e3298283c775bb0 | ||||
| Emeil A. | False | 5.0 | 5.0 | 54 minutes ago | 2026-05-22 | https://www.google.com/maps/reviews/data=!4m8!14m7!1m6!2m5!1sCi9DQUlRQUNvZENodHljRjlvT2xBNGRFeEtXSEpMUzBOVVREWkxaa052TUVaVllsRRAB!2m1!1s0x0:0x6e3298283c775bb0!3m1!1s2@1:CAIQACodChtycF9oOlA4dExKWHJLS0NUTDZLZkNvMEZVYlE%7C%7C?hl=en | www.google.com | KFC | 1077 | 3.1 | 798-812 4th Ave, Brooklyn, NY 11232 | ChIJIwnh7ulawokRsFt3PCiYMm4 | https://www.google.com/search?newwindow=1&sca_esv=cb0ef06c41fe51d8&cs=0&output=search&kgmid=/g/1trxfm7c&q=KFC&shem=rimspwouoe&shndl=30&source=sh/x/loc/uni/m1/1&kgs=5d1cba8489df35b1&utm_source=rimspwouoe,sh/x/loc/uni/m1/1#lrd=0x89c25ae9eee10923:0x6e3298283c775bb0,1,,,, | https://www.google.com/maps/place/KFC,+798-812+4th+Ave,+Brooklyn,+NY+11232/@40.6592293,-73.9998152,3027a,13.1y/data=!4m2!3m1!1s0x89c25ae9eee10923:0x6e3298283c775bb0 |
Get Data in Minutes, Not Hours
Unlike custom scripts that require setup, debugging, and retries, this approach is designed for speed.
Once configured, you can retrieve review data within minutes.
Built as a Data Pipeline (Not Just a Scraper)
This isn’t just a one-time extraction tool. It’s designed for ongoing data workflows:
- Schedule runs automatically to keep your dataset continuously updated
- Access data via APIs for integration with internal tools or dashboards
- Push data directly to cloud storage like dropbox or other destinations
Instead of manually exporting files, the data can flow directly into your analytics or monitoring systems.
What This Replaces
Compared to the Python approach, this method removes the most fragile parts of scraping:
- No dependency on changing CSS selectors
- No manual CAPTCHA handling
- No browser or environment setup
- No need to manage proxies, retries, or scaling logic
In other words, most of the infrastructure work is already handled.
How It Works
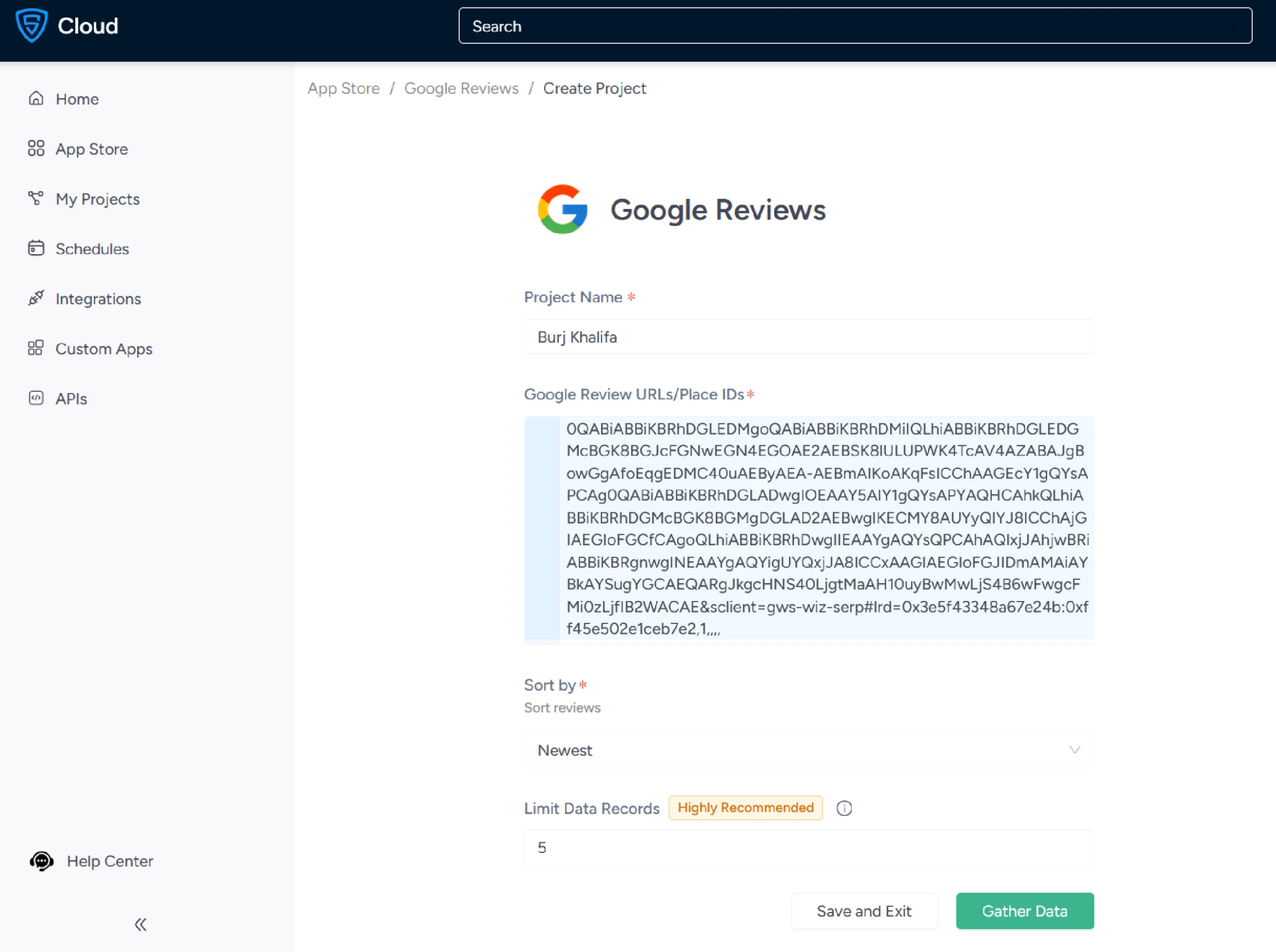
1. Log in to your ScrapeHero Cloud account.

2. Navigate to the Google Reviews Scraper App in the ScrapeHero App Store.
3. Click on “Create New Project”.
4. Provide Google Review URL or place ID into the Input field of this crawler.
5. Specify the number of the data records you want to gather from the project run.
6. Click “Gather Data” to begin the data extraction process.
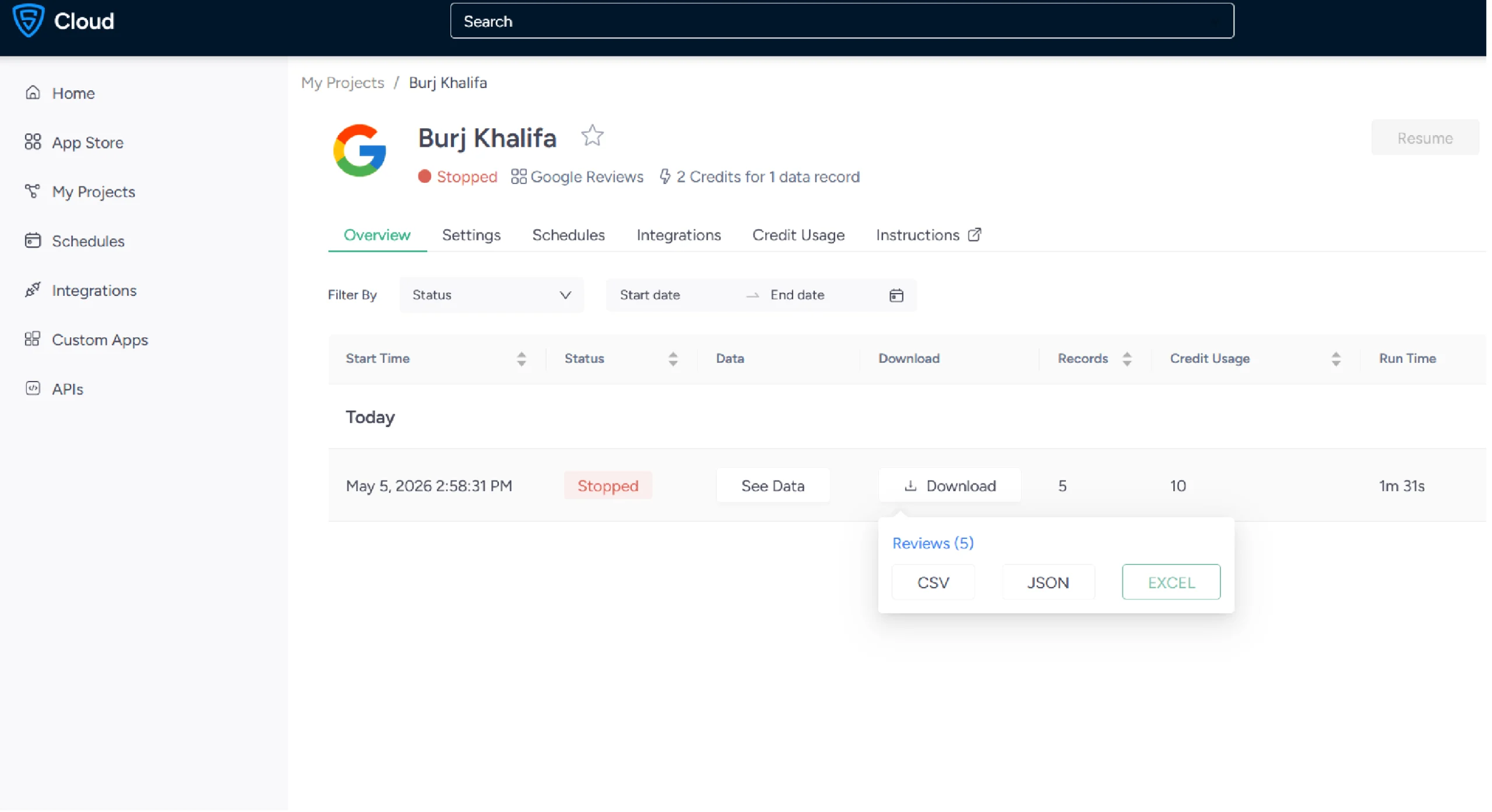
Once complete, download your data in your preferred format (CSV, JSON, or Excel) or connect any of the available integrations to get seamless access to the scraped data.
When This Approach Makes More Sense
This method is a better fit if you:
- Don’t want to code
- Require integration with existing data pipelines
- Prefer automated delivery instead of manual exports
For example, a brand tracking reviews across dozens of locations can schedule daily runs and push the data directly into a dashboard without maintaining any scraping code.
Python vs No-Code vs Managed Service: Which Should You Use?
There are multiple ways to web scrape Google reviews, but the right choice depends on your scale, technical comfort, and how often you need the data.
Here’s a practical comparison:
| Approach | Setup Effort | Maintenance | Scalability | Best For |
| Python (Playwright) | High | High (selectors, CAPTCHAs, updates) | Limited without major engineering | Developers, one-off projects, small datasets |
| No-Code Tool (ScrapeHero Cloud) | Low | Low | High | Business users, recurring data collection, multi-location tracking |
| Managed Service | Very Low | None | Very High | Teams needing large-scale, reliable, production-grade data |
How to Decide
Use Python if:
- You’re comfortable with code
- You need a small dataset or a one-time scrape
- You want full control over the extraction logic
Use a no-code tool if:
- You need data regularly (daily/weekly)
- You’re working across multiple locations
- You want structured data without maintaining infrastructure
Use a managed service if:
- You need data at scale (hundreds or thousands of listings)
- Reliability and uptime matter
- You don’t want to deal with scraping at all
The Tradeoff to Keep in Mind
Custom scripts give you flexibility, but they also require ongoing maintenance.
Tools and services reduce flexibility slightly, but in return, they handle:
- DOM changes
- CAPTCHA challenges
- scaling and retries
So the decision comes down to this: Do you want to build and maintain a scraper, or use the data without worrying about how it’s collected?
Wrapping Up: Why You Need a Web Scraping Service
Scraping Google reviews with Python is a great way to understand how the process works, and it’s perfectly fine for small, controlled use cases.
But the moment you need reliability, scale, or consistency, the problem shifts from “getting data” to “keeping the pipeline running.”
That includes, handling DOM changes, avoiding blocks and CAPTCHAs, managing infrastructure and retries. If you find yourself debugging broken selectors or rerunning failed jobs, you’re maintaining a data system instead of just scraping.
A managed web scraping service, like ScrapeHero, can handle that entire layer for you. Instead of worrying about how the data is collected, you can focus on using it—whether that’s for competitor tracking, sentiment analysis, or SEO monitoring.
ScrapeHero is your #1 web scraping service provider. Our data-as-a-service can handle your entire data pipeline, from extraction to building custom RPA solutions and AI models. Contact ScrapeHero today.
FAQs
Yes. Google Reviews is extracting customer feedback from the Google Knowledge Panel associated with a specific business or locale. You can scrape Google Reviews using different methods.
ScrapeHero provides a comprehensive pricing plan for both Scrapers and APIs. To know more about the pricing, visit our pricing page.
The legality of web scraping depends on the legal jurisdiction, i.e., laws specific to the country and the locality. Gathering or scraping publicly available information is not illegal.
Generally, Web scraping is legal if you are scraping publicly available data.
Please refer to our Legal Page to learn more about the legality of web scraping.



