Wouldn’t it be great if you could build your own FREE API to get product reviews from Amazon? That’s exactly what you will be able to do once you follow this tutorial using Python Flask, Selectorlib and Requests.
What can you do with the Amazon Product Review API?
An API lets you automatically gather data and process it. Some of the uses of this API could be:
- Getting the Amazon Product Review Summary in real-time
- Creating a Web app or Mobile Application to embed reviews from your Amazon products
- Integrating Amazon reviews into your Shopify store, Woocommerce or any other eCommerce store
- Monitoring reviews for competitor products in real-time
The possibilities for automation using an API are endless so let’s get started.
Why build your own API?
You must be wondering if Amazon provides an API to get product reviews and why you need to build your own.
APIs provided by companies are usually limited and Amazon is no exception. They no longer allow you to get a full list of customers reviews for a product on Amazon through their Product Advertising API. Instead, they provide an iframe which renders the reviews from their web servers – which isn’t really useful if you need the full reviews.
How to Get Started
In this tutorial, we will build a basic API to scrape Amazon product reviews using Python and get data in real-time with all fields, that the Amazon Product API does not provide.
We will use the API we build as part of this exercise to extract the following attributes from a product review page. (https://www.amazon.com/Nike-Womens-Reax-Running-Shoes/product-reviews/B07ZPL752N/ref=cm_cr_dp_d_show_all_btm?ie=UTF8&reviewerType=all_reviews)
- Product Name
- Number of Reviews
- Average Rating
- Rating Histogram
- Reviews
- Author
- Rating
- Title
- Content
- Posted Date
- Variant
- Verified Purchase
- Number of People Found Helpful
Installing the required packages for running this Web Scraper API
We will use Python 3 to build this API. You just need to install Python 3 from Python’s Website.
We need a few python packages to setup this real-time API
- Python Flask, a lightweight server will be our API server. We will send our API requests to Flask, which will then scrape the web and respond back with the scraped data as JSON
- Python Requests, to download Amazon product review pages’ HTML
- Selectorlib, a free web scraper tool to markup data that we want to download
Install all these packages them using pip3 in one command:
pip3 install flask selectorlib requests
The Code
You can get all the code used in this tutorial from Github – https://github.com/scrapehero-code/amazon-review-api
In a folder called amazon-review-api, let’s create a file called app.py with the code below.
Here is what the code below does:
- Creates a web server to accept requests
- Downloads a URL and extracts the data using the Selectorlib template
- Formats the data
- Sends data as JSON back to requester
from flask import Flask, request, jsonify
import selectorlib
import requests
from dateutil import parser as dateparser
app = Flask(__name__)
extractor = selectorlib.Extractor.from_yaml_file('selectors.yml')
def scrape(url):
headers = {
'authority': 'www.amazon.com',
'pragma': 'no-cache',
'cache-control': 'no-cache',
'dnt': '1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (X11; CrOS x86_64 8172.45.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.64 Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'sec-fetch-site': 'none',
'sec-fetch-mode': 'navigate',
'sec-fetch-dest': 'document',
'accept-language': 'en-GB,en-US;q=0.9,en;q=0.8',
}
# Download the page using requests
print("Downloading %s"%url)
r = requests.get(url, headers=headers)
# Simple check to check if page was blocked (Usually 503)
if r.status_code > 500:
if "To discuss automated access to Amazon data please contact" in r.text:
print("Page %s was blocked by Amazon. Please try using better proxies\n"%url)
else:
print("Page %s must have been blocked by Amazon as the status code was %d"%(url,r.status_code))
return None
# Pass the HTML of the page and create
data = extractor.extract(r.text,base_url=url)
reviews = []
for r in data['reviews']:
if 'verified_purchase' in r:
if 'Verified Purchase' in r['verified_purchase']:
r['verified_purchase'] = True
else:
r['verified_purchase'] = False
r['rating'] = r['rating'].split(' out of')[0]
date_posted = r['date'].split('on ')[-1]
if r['images']:
r['images'] = "\n".join(r['images'])
r['date'] = dateparser.parse(date_posted).strftime('%d %b %Y')
reviews.append(r)
histogram = {}
for h in data['histogram']:
histogram[h['key']] = h['value']
data['url'] = url
data['histogram'] = histogram
data['average_rating'] = float(data['average_rating'].split(' out')[0])
data['reviews'] = reviews
data['number_of_reviews'] = int(data['number_of_reviews'].split(' customer')[0])
return data
@app.route('/')
def api():
url = request.args.get('url',None)
if url:
data = scrape(url)
return jsonify(data)
return jsonify({'error':'URL to scrape is not provided'}),400
Free web scraper tool – Selectorlib
You will notice in the code above that we used a file called selectors.yml. This file is what makes this tutorial so easy to scrape Amazon reviews. The magic behind this file is a tool called Selectorlib.
Selectorlib is a powerful and easy to use tool that makes selecting, marking up, and extracting data from web pages visual and simple. The Selectorlib Chrome Extension lets you mark data that you need to extract, and creates the CSS Selectors or XPaths needed to extract that data, then previews how the data would look like. You can learn more about Selectorlib and how to use it here
If you just need the data we have shown above, you don’t need to use Selectorlib because we have done that for you already and generated a simple “template” that you can just use. However, if you want to add a new field, you can use Selectorlib to add that field to the template.
Here is how we marked up the fields in the code for all the data we need from Amazon Product Reviews Page using Selectorlib Chrome Extension.
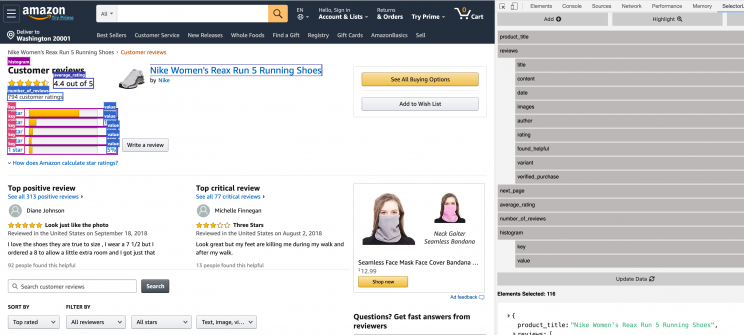
Once you have created the template, click on ‘Highlight’ to highlight and preview all of your selectors. Finally, click on ‘Export’ and download the YAML file and that file is the selectors.yml file.
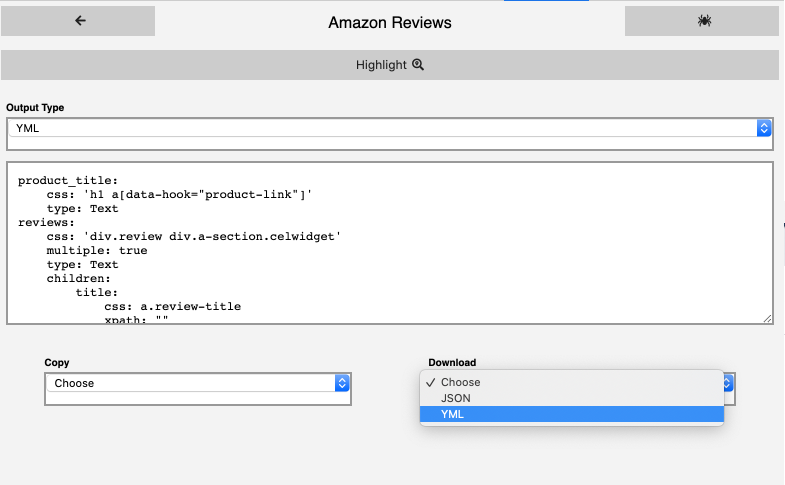
Here is how our selectors.yml looks like
product_title:
css: 'h1 a[data-hook="product-link"]'
type: Text
reviews:
css: 'div.review div.a-section.celwidget'
multiple: true
type: Text
children:
title:
css: a.review-title
type: Text
content:
css: 'div.a-row.review-data span.review-text'
type: Text
date:
css: span.a-size-base.a-color-secondary
type: Text
images:
css: img.review-image-tile
multiple: true
type: Attribute
attribute: src
author:
css: span.a-profile-name
type: Text
rating:
css: 'div.a-row:nth-of-type(2) > a.a-link-normal:nth-of-type(1)'
type: Attribute
attribute: title
found_helpful:
css: 'span[data-hook="review-voting-widget"] span.a-size-base'
type: Text
variant:
css: a.a-size-mini
type: Text
verified_purchase:
css: 'span[data-hook="avp-badge"]'
type: Text
next_page:
css: 'li.a-last a'
type: Link
average_rating:
css: 'span[data-hook="rating-out-of-text"]'
type: Text
number_of_reviews:
css: 'div[data-hook="total-review-count"] span.a-size-base'
type: Text
histogram:
css: tr.a-histogram-row
multiple: true
type: Text
children:
key:
css: 'td.aok-nowrap a.a-link-normal'
type: Text
value:
css: 'td.a-text-right a.a-link-normal'
type: Text
You need to put this selectors.yml in the same folder as your app.py
Running the Web Scraping API
To run the flask API, type and run the following commands into a terminal:
export FLASK_APP=app.py flask run
Then you can test the API by opening the following link in a browser or using any programming language.
http://localhost:5000/?url=https://www.amazon.com/Nike-Womens-Reax-Running-Shoes/product-reviews/B07ZPL752N/ref=cm_cr_dp_d_show_all_btm?ie=UTF8&reviewerType=all_reviews
Your response should be similar to this:
{
"product_title": "Nike Women's Reax Run 5 Running Shoes",
"average_rating": 4.4,
"histogram": {
"1 star": "5%",
"2 star": "4%",
"3 star": "6%",
"4 star": "11%",
"5 star": "73%"
},
"next_page": "https://www.amazon.com/Nike-Womens-Reax-Running-Shoes/product-reviews/B07ZPL752N/ref=cm_cr_arp_d_paging_btm_2?ie=UTF8&pageNumber=2",
"url": "https://www.amazon.com/Nike-Womens-Reax-Running-Shoes/product-reviews/B07ZPL752N/ref=cm_cr_dp_d_show_all_btm?ie=UTF8",
"number_of_reviews": 794,
"reviews": [
{
"author": "Diane Johnson",
"content": "I love the shoes they are true to size , I wear a 7 1/2 but I ordered a 8 to allow a little extra room and I got just that",
"date": "18 Sep 2018",
"found_helpful": "92 people found this helpful",
"images": "https://images-na.ssl-images-amazon.com/images/I/81wdRdaAfmL._SY88.jpg",
"rating": "5.0",
"title": "Look just like the photo",
"variant": "Size: 8 Color: White/Metallic Silver/Dark Grey",
"verified_purchase": true
},
{
"author": "sherlain miranda",
"content": "Just writing a rare review on these . I love Nike\u2019s but my feet don\u2019t usually. So I\u2019ve ordered and returned a lot. Tried again lol and these ARE AMAZING comfortable. So much that I may order 3 more this year just to have them. The color is so cute and clean and sporty. I\u2019m 99.9% sure I\u2019ve dinally found a pair of Nikes I\u2019m not going to return , fingers crossed \ud83e\udd1e\ud83d\ude0a",
"date": "08 May 2019",
"found_helpful": "63 people found this helpful",
"images": "https://images-na.ssl-images-amazon.com/images/I/717EKthL0BL._SY88.jpg",
"rating": "4.0",
"title": "After 20 returns",
"variant": "Size: 10 Color: White/Metallic Silver/Dark Grey",
"verified_purchase": true
}
]
}
This API should work for to scrape Amazon reviews for your personal projects. You can also deploy it to a server if you prefer.
However, if you want to scrape websites for thousands of pages, learn about the challenges here Scalable Large Scale Web Scraping – How to build, maintain and run scrapers. If you need help your web scraping projects or need a custom API you can contact us.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



