
This article outlines a few methods to scrape Shopify by building a Shopify scraper and more. This could effectively export Shopify product data to Excel or other formats for easier access and use.
There are two methods to scrape Shopify stores:
- Build a Shopify product Scraper in Python or JavaScript
- Using the ScrapeHero Cloud, Shopify Scraper, a no-code tool

Building a Shopify Scraper in Python/JavaScript
This section will guide you on how to scrape Shopify using either Python or JavaScript. We will utilize the browser automation framework called Playwright to emulate browser behavior in our code.
One of the key advantages of this approach is its ability to bypass common blocks often put in place to prevent scraping. However, familiarity with the Playwright API is necessary to use it effectively.
You could also use Python Requests, LXML, or BeautifulSoup to build a Shopify scraper without using a browser or a browser automation library. But bypassing the anti scraping mechanisms put in place can be challenging and is beyond the scope of this article.
Here are the steps to scrape Shopify product data using Playwright:
Step 1: Choose Python or JavaScript as your programming language.
Step 2: Install Playwright for your preferred language:
JavaScript
Python
JavaScript
npm install playwright@latest
Python
pip install playwright # to download the necessary browsers playwright install
Step 3: Write your code to emulate browser behavior and extract the desired data from Shopify using the Playwright API. You can use the code provided below:
JavaScript
Python
JavaScript
// importing required modules
const fs = require('fs');
const playwright = require('playwright');
const searchKeyword = "furniture"
const pageLimit = 3
productData = []
/**
* Validates whether the Locator contains any data.
* Returns the innerHTML if its a valid one, other wise returns null
* @param{locator}data
* @returns
*/
async function processData(data) {
count = await data.count()
if (count) {
data = await data.innerText()
} else {
data = null;
}
return data
}
/**
* This function used to save the data as json file.
* @param {[object]} data the data to be write as json file.
*/
function saveData() {
let dataStr = JSON.stringify(data, null, 2)
fs.writeFile("shopifyData.json", dataStr, 'utf8', function (err) {
if (err) {
console.log("An error occured while writing JSON Object to File.");
return console.log(err);
}
console.log("JSON file has been saved.");
});
}
/**
* This function will extract the data from the product page
* and store it to a global variable
* @param{*}page
* @returns page
*/
async function parseProductPage(page) {
// Initializing necessary xpaths
const xpathTitle = "//h1[contains(@class, 'product-title')]"
const xpathSubtitle = "//h1[contains(@class, 'product-title')]/following-sibling::h2/a"
const xpathSalePrice = "//span[@class='c__sale']"
const xpathListingPrice = "//span[@class='c__sale']/../s"
// Locating the elements
let productTitle = page.locator(xpathTitle)
let subtitle = page.locator(xpathSubtitle)
let salePrice = page.locator(xpathSalePrice)
let listingPrice = page.locator(xpathListingPrice)
//Extracting the necessary data
productTitle = await processData(productTitle)
subtitle = await processData(subtitle)
salePrice = await processData(salePrice)
listingPrice = await processData(listingPrice)
url = page.url
const dataToSave = {
"title": productTitle,
"subtitle": subtitle,
"sale_price": salePrice,
"listing_price": listingPrice,
"url": url
}
// Saving to a global variable
productData.push(dataToSave)
return page
}
/**
* This function will parse the listing page and click each products
Also this fuction will handle the pagination of the listing page
* @param {page} page Page object
* @param {int} currentPage Current page number
* @param {int} pageLimit Number of pages that need to be paginated
* @returns
*/
async function parseListingPage(page, currentPage, pageLimit) {
const xpathProducts = "//div[@class='link--product']"
const xpathNextPageButton = "//span[@class='sp-nav-arrow-right']"
let allProducts = page.locator(xpathProducts)
let nextPageButton = page.locator(xpathNextPageButton)
const allProductsCount = await allProducts.count();
// Clicking each product and passing the page object to
// the parseProduct Function.
for (var index = 0; index < allProductsCount; index++) {
const product = await allProducts.nth(index);
await product.click()
await page.waitForLoadState()
await parseProductPage(page)
await page.goBack()
await page.waitForLoadState()
}
// Pagination usng recursion
if (currentPage < pageLimit && await nextPageButton.count()) {
currentPage += 1
await nextPageButton.click()
await page.waitForLoadState()
await parseListingPage(page, currentPage, pageLimit)
} else {
return page;
}
}
/**
* Open browser, goto given url and collect data
*/
async function run() {
const browser = await playwright.chromium.launch({
headless: false
});
const context = await browser.newContext({
#Note: replace with your proxy provider here
proxy: { server: 'http://<server:port>' }
});
// Initializing necessary xpaths
const xpathSearchButtonIcon = "//span[@class='sp sp-search']"
const xpathSearchBox = "//input[@id='SearchInput']"
const xpathViewAll = "//li[@class='search-results--more']/a"
// Open new page
let page = await context.newPage()
// Navigating to the home page
await page.goto('https://hauslondon.com/', { waitUntil: 'load', timeout: 0 });
// Clicking the search button
await page.locator(xpathSearchButtonIcon).click()
// Clicking the search box
await page.locator(xpathSearchBox).click({ waitUntil: 'load' })
// Typing the keyword
await page.locator(xpathSearchBox).type(searchKeyword, delay = 200)
await page.waitForLoadState()
await page.waitForTimeout(30000);
// Clicking view all button
await page.locator(xpathViewAll).click()
await page.waitForLoadState()
// parsing the listing page
page = await parseListingPage(page = page, currentPage = 1, pageLimit = pageLimit)
// Saving the data
saveData();
// Closing browser context after use
await context.close();
await browser.close();
};
run();
Python
import asyncio
import json
from playwright.async_api import Playwright, async_playwright
search_keyword = "furniture"
page_limit = 3
data = []
def save_data():
"""Save the data as a json file"""
with open("shopify_scraper.json", "w") as file:
json.dump(data, file, indent=2)
async def parse_product_page(page):
"""
This function will extract the data from the product page
Args:
page (page object): The product page object to extract the data
Returns:
Save the extracted data to a global object
"""
xpath_title = "//h1[contains(@class, 'product-title')]"
xpath_subtitle = "//h1[contains(@class, 'product-title')]/following-sibling::h2/a"
xpath_sale_price = "//span[@class='c__sale']"
xpath_listing_price = "//span[@class='c__sale']/../s"
title = page.locator(xpath_title)
subtitle = page.locator(xpath_subtitle)
sale_price = page.locator(xpath_sale_price)
listing_price = page.locator(xpath_listing_price)
title = await title.inner_text() if await title.count() else None
title = title.encode("ascii", errors="ignore").decode()
subtitle = await subtitle.inner_text() if await subtitle.count() else None
sale_price = await sale_price.inner_text() if await sale_price.count() else None
listing_price = (
await listing_price.inner_text() if await listing_price.count() else None
)
url = page.url
data_to_save = {
"title": title,
"subtitle": subtitle,
"sale_price": sale_price,
"listing_price": listing_price,
"url": url,
}
data.append(data_to_save)
return page
async def parse_listing_page(page, current_page, page_limit):
"""
This function will parse the listing page and click each products
Also this fuction will handle the pagination of the listing page
Args:
page (page object): The listig page object
current_page (int): Current page number
page_limit (_type_): Number of pages that need to be paginated
Returns:
page: current page obejct
"""
# Initializing necessary xpaths
xpath_products = "//div[@class='link--product']"
xpath_next_page_button = "//span[@class='sp-nav-arrow-right']"
all_products = page.locator(xpath_products)
next_page_button = page.locator(xpath_next_page_button)
# Iterating thorough each products and clicking it
for product_index in range(await all_products.count()):
product = all_products.nth(product_index)
await product.click()
await page.wait_for_load_state()
await parse_product_page(page)
await page.go_back()
await page.wait_for_load_state()
# Pagninating
if current_page < page_limit and await next_page_button.count():
current_page += 1
await next_page_button.click()
await page.wait_for_load_state()
await parse_listing_page(page, current_page=current_page, page_limit=page_limit)
else:
return page
async def run(playwright: Playwright) -> None:
"""
This function will create a browser and page object
Args:
playwright (Playwright): Playwright object
"""
# Initiating a browser instance and getting a new page
browser = await playwright.chromium.launch(headless=False, proxy={
#Note: replace with your proxy credentials here
"server": "http://myproxy.com:3128",
"username": "usr",
"password": "pwd"
})
context = await browser.new_context()
page = await context.new_page()
# Initialising necessary xpath locators
xpath_search_button_icon = "//span[@class='sp sp-search']"
xpath_search_box = "//input[@id='SearchInput']"
xpath_view_all = "//li[@class='search-results--more']/a"
# Navigating to homepage
await page.goto("https://hauslondon.com/")
# Clicking the search icon
await page.locator(xpath_search_button_icon).click()
# Clicking the input search box
await page.locator(xpath_search_box).click()
# Typing the search keyword
await page.locator(xpath_search_box).type(search_keyword, delay=200)
await page.wait_for_load_state(timeout=10)
# Clicking the viewall button for getting into the listing page
await page.locator(xpath_view_all).click()
await page.wait_for_timeout(10000)
page = await parse_listing_page(page=page, current_page=1, page_limit=page_limit)
save_data()
# ---------------------
await context.close()
await browser.close()
async def main() -> None:
async with async_playwright() as playwright:
await run(playwright)
asyncio.run(main())
This code shows how to build and run a Shopify scraper using the Playwright library in Python and JavaScript.
The corresponding scripts have two main functions:
- run function: This function takes a Playwright instance as an input and performs the scraping process. The function launches a Chromium browser instance, navigates to the homepage of the Shopify store, fills in a search query, clicks the search button, and waits for the results to be displayed on the page. The save_data function is then called to extract the review details and store the data in the shopify_scraper.json file.
- parse_product_page function: This function takes a Playwright page object as input and returns a list of dictionaries containing product details. The details include each product’s title, subtitle, sale price, listing price, and URL.
Finally, the main function uses the async_playwright context manager to execute the run function. A JSON file containing the listings of the Shopify script you just executed would be created.
Step 4: Run your code for the Shopify Scraper and collect the scraped data.
Also Read: Web Scraping using Playwright in Python and JavaScript
Using No-Code Shopify Scraper by ScrapeHero Cloud
The Shopify Scraper by ScrapeHero Cloud is convenient for scraping product data from Shopify. It provides an easy, no-code method for scraping data, making it accessible for individuals with limited technical skills.
This section will guide you through the steps to set up and use the Shopify scraper.
- Sign up or log in to your ScrapeHero Cloud account.
- Go to the Shopify scraper by ScrapeHero Cloud in the marketplace.
- Add the scraper to your account. (Don’t forget to verify your email if you haven’t already.)
- You need to add the Shopify store URL to start the scraper. If it’s just a single query, enter it in the field provided and choose the number of pages to scrape.
You can get the Shopify store URL from the website’s address bar.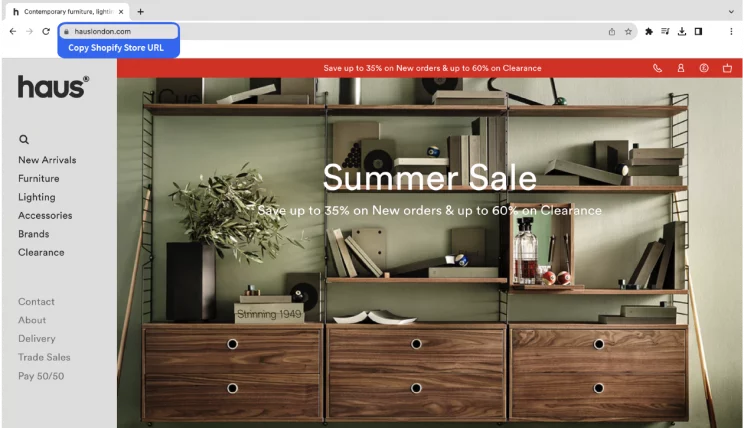
- To scrape results for multiple queries, switch to Advance Mode, and in the Input tab, add the Shopify store URL to the SearchQuery field and save the settings.
- To start the scraper, click on the Gather Data button.
- The scraper will start fetching data for your queries, and you can track its progress under the Jobs tab.
- Once finished, you can view or download the data from the same.
- You can also export the Shopify product data into an Excel spreadsheet from here. Click on the Download Data, select “Excel,” and open the downloaded file using Microsoft Excel.
Also Read: Web Scraping using Playwright in Python and JavaScript
Uses Cases of Shopify Scraper
If you’re unsure as to why you should scrape Shopify, here are a few use cases where this data would be helpful:
Pricing Comparison
You can comprehensively understand your competitors’ pricing strategies by scraping product data. You’ll see what they’re charging for similar products, allowing you to benchmark your prices against theirs.
This information can help you develop a pricing strategy that’s both competitive and profitable.
Lead Generation
Scraped product data can reveal shopping patterns, preferred products, and purchasing frequencies of customers. By identifying and understanding these behaviors, you can tailor your marketing efforts to attract new customers.
Whether offering similar products, running targeted promotions, or simply understanding customers’ interests, scraped data can fuel effective lead-generation campaigns.
Market Trend Analysis
Data scraping allows you to identify what products are in demand and popular among consumers. This is achieved by observing the frequency of purchases and the number of reviews for different products.
By aligning your product offerings with these trends, you can better cater to customer demand and optimize your inventory.
Product Performance Monitoring
Scraped data provides an efficient way to track product performance across multiple Shopify stores. It allows you to monitor variables like sales volume, frequency of purchases, and customer reviews.
This information can provide insights into how your products perform compared to others and help you make informed decisions regarding inventory management, pricing, and marketing strategies.
SEO Improvement
Scraping competitors’ Shopify sites can yield valuable information about their SEO practices. This includes elements like meta descriptions, headlines, and keyword usage. Understanding what works for top-ranking products can guide your own SEO strategies.
You can use similar techniques to optimize your product listings, improve your site’s visibility, drive more traffic, and ultimately increase sales.
Frequently Asked Questions
Shopify scraping extracts product data from a Shopify website selling any range of products. This process facilitates pricing comparison, product performance monitoring, lead generation, etc.
What is the subscription fee for the Shopify Scraper by ScrapeHero?
To know more about the pricing, visit the pricing page.
Is it legal to scrape Shopify?
Legality depends on the legal jurisdiction, i.e., laws specific to the country and the locality. Gathering or scraping publicly available information is not illegal.
Generally, Web scraping is legal if you are scraping publicly available data.
Please refer to our Legal Page to learn more about the legality of web scraping.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



