
Large-scale web scraping is crucial for businesses to automate the process of data collection, tracking market trends, and fueling machine learning models. But is it just confined to data extraction or trend analysis? No. Effective large-scale data scraping requires planning, skilled personnel, and robust infrastructure.
This article will give you insights on large-scale web scraping, how it is different from regular web scraping, and how you can build, run, and maintain scrapers on a large-scale. It also addresses major challenges that often come with web scraping at scale.
Large-Scale Web Scraping vs. Regular Web Scraping
-
What Is Large-Scale Web Scraping?
Large-scale web scraping is the automatic extraction of vast amounts of data from multiple websites. Specialized software navigates web pages, extracts relevant information, and stores the data for later analysis.
Businesses that require extensive datasets to monitor market trends and competitor activities or train machine learning models rely on web scraping on a large scale. It needs infrastructure, skilled developers, and careful planning to manage challenges like rate limiting and CAPTCHA solving.
-
What Is Regular Web Scraping?
Regular web scraping is the extraction of data from a relatively small number of web pages. It uses simple tools to extract specific information, such as Amazon product offers, sellers, prices, or contact information. It is mainly used for specific tasks, personal projects, academic research, or small business needs.
Regular web scraping, when compared to large-scale scraping, is a simpler process that doesn’t handle massive amounts of data. It’s a more accessible option that doesn’t require advanced techniques like IP rotation or CAPTCHA solving, making it ideal for smaller tasks and projects.
How To Build Web Scrapers in Large-Scale
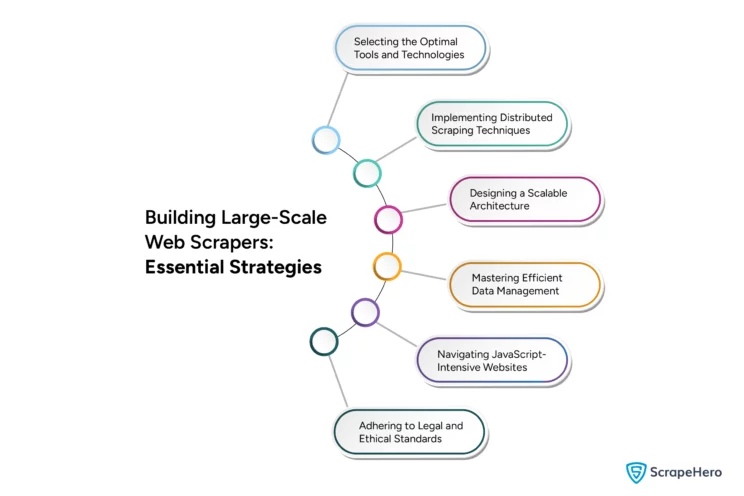
Choose a reliable framework such as urllib (Python) or Puppeteer (JavaScript), to build a web scraper. When considering scalability, managing large data volumes and request loads is crucial.
For this, some essential strategies for evading blocks by target websites or ensuring robustness to handle various scraping challenges need to be carried out. Here are A few key strategies that can help you build scalable and efficient web scrapers that can handle large-scale operations.
1. Choose the Right Tools and Technologies
Python is the most popular programming language for web scraping. It extensively provides third-party libraries like BeautifulSoup for web scraping and Selenium and Playwright for handling complex websites with JavaScript.
Even though Node.js is adequate for asynchronous web scraping tasks, Python is chosen mainly for simple and complex scraping needs. Also, Python’s extensive community support provides valuable resources and troubleshooting assistance for scrapers.
The choice of tools or frameworks should depend on a few factors, such as the website(s) you plan to scrape. Some tools are better than others at handling the complexity of the sites. Generally speaking, the more flexible the tool, the more the learning curve, and conversely, the easy-to-use tools may not handle complex sites or logic.
What Is a Complex Website?
Any website built using advanced JavaScript frameworks such as React or Angular is usually complex if you are extracting a lot of data from it. To scrape the data, you will need a real web browser such as Puppeteer or Selenium. Alternatively, you can check and reverse engineer the website’s REST API if it exists.
What Is Complex Logic?
Here are some examples of complex logic:
- Scrape details from a listing website, search with the listing name in another site, combine this data, and save it to a database.
- Take a list of keywords, perform a search in Google Maps for each keyword, go to the result, extract contact details, repeat the same process on Yelp and a few other websites, and finally combine all this data.
2. Distributed Scraping
Employing a proxy pool to rotate IP addresses can minimize the risk of getting blocked. Implementing rate limiting and throttling can also simulate human behavior and evade anti-scraping systems. For this, you should add delays and random intervals between requests.
In addition, if you use load balancing by distributing the scraping tasks across multiple servers or instances, you can maintain smooth operation and avoid bot detection by websites, enhancing efficiency and preventing overload.
3. Scalable Architecture
It would help to use microservices to manage and scale different parts of your scrapers independently. When demand rises, utilize cloud services such as AWS, Azure, or Google Cloud and dynamically scale resources based on these demands.
You can also use message queues, such as RabbitMQ or Kafka, to manage tasks and data flow between components, making them more reliable and ensuring that the scraping system can handle varying loads and maintain stability.
4. Efficient Data Management
It would be best if you choose the appropriate database for your data. For example, select SQL databases for structured data and NoSQL for unstructured or semi-structured data. You can use caching mechanisms to store frequently accessed data and reduce the load on both the scraper and the target website.
Automate data cleaning and processing to efficiently manage large datasets, which ensures data integrity and usability and optimizes web scraping operations by enhancing data storage, access speed, and quality.
5. Handling JavaScript-Heavy Sites
Use headless browsers such as Puppeteer or Selenium to handle JavaScript-intensive websites or mimic real user behaviors. You can also opt for official APIs or reverse-engineer site API requests to retrieve data directly in a structured format.
These methods can facilitate web scraping of dynamic content. They can also streamline the data acquisition process, ensure efficiency, and avoid being blocked by websites.
6. Legal and Ethical Considerations
When web scraping large amounts of data, it is essential to ensure legal compliance with the website’s relevant laws and terms of service. Design scrapers in such a way that they minimize the impact on the website’s servers.
You must avoid making excessive requests or scraping during a website’s peak traffic hours. Adhere to ethical scraping practices to reduce the risk of legal repercussions and promote a more sustainable interaction with web resources.
How To Run Web Scrapers at Large-Scale
Large-scale web scraping requires a robust infrastructure that can handle millions of pages across thousands of websites daily. So, some insights and strategies must be followed to effectively run such scrapers.
-
Efficient Resource Management
It is critical to manage resources efficiently, especially when handling extensive scraping tasks is needed. Refine your code to use minimal CPU and memory. You can also use scalable cloud services for your operations without physical hardware.
-
Scheduling and Automation
Automate and schedule your scrapers to run during off-peak hours to lessen the load on your infrastructure and target websites. Tools like Apache Airflow can help you plan and manage multiple scraping tasks.
-
Analytics and Monitoring
For smooth running of scrapers ongoing monitoring is essential. Using tools such as Splunk or the ELK Stack you can continuously track the performance of your scrapers. Also implement robust logging and analytics in order to identify bottlenecks and optimize performance of the scraper.
-
Distributed Web Scraping Architecture
A distributed architecture is necessary to handle vast volumes of data. You can use brokers like Redis to manage URLs and data queues across different servers. Ensure that the scrapers can restart automatically if interrupted. Handle and store the extracted data in queues and manage data flows efficiently.
-
Databases for Large Data Storage
You must choose a suitable database for managing extensive records. Databases like MongoDB, Cassandra, or HBase are suited for the high-speed and frequency demands of large-scale scraping. Once the data is stored, integrate it with your business processes, ensuring data quality through Quality Assurance tests.
-
Handling Anti-Scraping Measures
Several strategies, such as IP rotation, proxies, and reverse engineering, can be implemented to handle anti-scraping tools. A large pool of private or geo-specific proxies can avoid IP bans and overcome other scraping barriers. Reverse engineering makes it easier to understand and analyze the server-side scripts and then bypass the mechanisms that restrict scraping.
-
Data Validation and Quality Control
The data extracted from various websites must be accurate and complete. Ensure data accuracy through quality checks on every piece of data. Use Python-based tools such as Pandas, Cerebrus, or Schema to validate data. You can also incorporate multiple stages in your data pipeline and verify data integrity using ETL tools.
How To Maintain Large-Scale Web Scrapers

To effectively maintain large-scale web scrapers, it is essential to adapt to the changing structures of target websites. So, to prevent data loss or inaccuracies caused by website structure changes, regular updates and monitoring mechanisms are needed for scrapers.
-
Regular Monitoring and Logging
Monitor the health and performance of your scrapers using tools like Prometheus, Grafana, or custom scripts. Implementing detailed logging of all scraper activities is also essential, as this will help diagnose issues and understand scraper behavior over time.
-
Error Handling and Alerts
Scrapers should handle errors like connection timeouts, HTTP errors, and content changes in the target website. You should also set up automated alerts using Slack, email, or SMS services for critical issues that require immediate attention.
-
Continuous Code Updates
The structure or technology of target websites may change. Therefore, update the scraping code regularly to accommodate such changes. If possible, use version control systems like Git to manage changes.
-
Scalability Adjustments
Cloud services allow you to scale resources automatically based on the workload, which includes increasing the number of scraper instances to handle high-demand times and reducing them when less capacity is needed. Perform load testing periodically to understand the limits of the scrapers and infrastructure and adjust as necessary.
-
Proxies and IP Rotation Management
You can avoid IP bans by managing your proxy pool and regularly updating it. Implementing IP rotation reduces the risk of being detected by websites. This approach enables continuous data collection without interruption and helps maintain the effectiveness of your web scraping by preventing IP addresses from being blocked.
-
Data Validation and Quality Checks
Implementing automated scripts ensures the accuracy and completeness of the extracted data. Establish a feedback loop to identify data errors and adjust error handling. Data validation and quality checks can minimize errors and maintain the integrity of the data collected.
-
Legal Compliance Review
Acquire legal information and comply with data privacy laws and the terms of service of websites. Adhere to the regulations to operate within legal boundaries and maintain ethical scraping practices. This approach can help safeguard you against any legal repercussions when web scraping large amounts of data.
-
Documentation and Training
When web scraping on a large-scale, detailed documentation of the scraper architecture, code, and maintenance procedures is vital, especially in facilitating onboarding and troubleshooting. All team members should be trained regularly on the technical and legal aspects of web scraping, which enhances the overall effectiveness and compliance of the scraping operations.
-
Infrastructure Maintenance
To enhance the scrapers’ performance, guard against vulnerabilities, regularly update all software and infrastructure components. Robust backup systems can also safeguard against data loss due to hardware failures. By following these practices, you can ensure that your scraping infrastructure always remains secure, efficient, and capable of recovering quickly from disruptions.
What Are the Challenges That Come Along With Large-Scale Web Scraping?
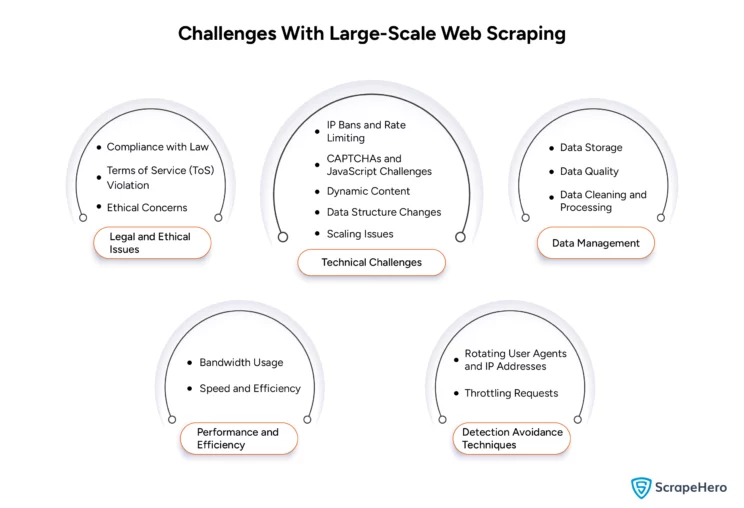
Large-scale web scraping has many advantages but comes with several technical and legal challenges. Here are some key issues to consider:
-
Legal and Ethical Issues
- Compliance with Laws – Scraping personal information leads to legal issues, and different countries follow different laws regarding data protection—for example, GDPR in Europe and CCPA in California.
- Terms of Service (ToS) Violation – Many websites have their terms of service that restrict web scraping, which, if violated, can lead to lawsuits or bans.
- Ethical Concerns—There are many ethical considerations in web scraping including respecting user privacy and the intent of the website. Sending more requests and overloading a website’s server are also seen as disruptive or damaging.
-
Technical Challenges
- IP Bans and Rate Limiting—If an IP makes too many requests in a short period or shows non-human behavior, websites ban such IPs.
- CAPTCHAs and JavaScript Challenges—These are used to block automated access and are often complex to bypass.
- Dynamic Content—Websites with content loaded either through JavaScript or based on user interactions are difficult to scrape without essential tools.
- Data Structure Changes – The existing scrapers may not work if the Websites update their layout.
- Scaling Issues—Large-scale web scaling requires efficient management of scrapers, task distribution, failure handling, and retrying failed requests.
-
Data Management
- Data Storage – In large-scale web scraping, vast amounts of data are extracted, and these should be stored efficiently.
- Data Quality – The extracted data should be accurate, complete, and relevant, which is challenging.
- Data Cleaning and Processing—The extracted data must be cleaned and transformed into a usable format before use.
-
Performance and Efficiency
- Bandwidth Usage – High-volume scraping requires substantial bandwidth, which can increase operational costs.
- Speed and Efficiency—Managing request timing and volume is also challenging. The speed of scraping must be balanced to avoid detection or IP banning.
-
Detection Avoidance Techniques
- Rotating User Agents and IP Addresses—Additional infrastructure may be needed to mimic browsers and rotate IPs to help avoid detection.
- Throttling Requests—Making requests at a random pace or during off-peak hours reduces the chances of being flagged as a bot, but this may be time-consuming.
Wrapping Up
Large-scale web scraping is not just complex, it’s also incredibly resource-intensive. To build, run, and maintain a scraper on this scale, you would need to constantly update your scraping infrastructure and stay on top of best practices and legal standards.
Advanced techniques and solutions may pose a challenge for small businesses or businesses that do not have a technical team to handle scrapers. With an expert team, ScrapeHero provides web scraping at scale for our customers.
You can depend on ScrapeHero web scraping services, as we can handle the challenges of web scraping large amounts of data. As a leader in Web crawling services for enterprises, we help you propel your enterprise forward with sufficient data.
Frequently Asked Questions
You need a robust infrastructure developed using distributed scraping techniques and cloud-based resources to handle web scraping on a large-scale effectively. You should also automate data validation and ensure legal compliance and ethical practices.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



