

Google Hotels provides aggregated hotel data, such as ratings, reviews, and prices, from various sources. If you are a single-time user, you can just find and book hotel rooms by comparing room rates. But what if you need large datasets to perform market research and make informed decisions? Then you may consider web scraping for Google Hotels.
This article is a step-by-step guide for web scraping Google Hotels using Python. It helps you harness hotel data for analyzing trends, comparing pricing across different hotels, and gaining valuable insights into the hospitality industry. Let’s begin.
How to Scrape Google Hotels
Google Hotels allows you to search for hotels in a particular area, say New York. When you search for a particular query, you will get the data on the hotels that get listed.
You can see the data visible on the listing page, which includes the name of the hotel, price, star rating, review count, and amenities provided by the hotel. Various steps for scraping Google Hotels are mentioned in the upcoming sections.
Installing Dependencies
pip install requests
pip install lxml
-
Importing Required Packages
import csv # For saving data import requests # For sending request to websites from lxml import html # For parsing dataThese are the libraries that you will use for your scraper. The final data is saved to a CSV file, and for this, you can use the csv module. For sending HTTP requests, use the requests module. The response received from the HTTP requests can be parsed using the lxml module.
-
Sending HTTP Request
Initialize a function named get_response, which accepts a query string as an argument, for sending HTTP requests. Now, find the request that fetches the data about hotels by using the developer tools of Chrome/Firefox.
Also Read: The Essential HTTP Headers for Web Scraping
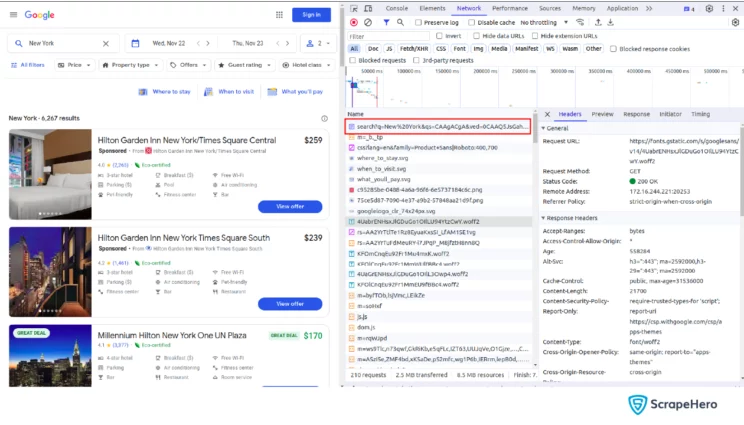
The highlighted request in the image has all the details shown on the web page. You can get the details of this request using the developer tools themselves. With this, you initialize the URL, headers, and params for the request.
url = "https://www.google.com/travel/search" headers = {...} params = { 'q': query_string, }Then you can use the ‘get’ method of the requests module to send the HTTP request with the said parameters.
response = requests.get(url=url, headers=headers, params=params)The full function will be:
def get_response(query_string): url = "https://www.google.com/travel/search" headers = {...} params = { 'q': query_string, } response = requests.get(url=url, headers=headers, params=params) return response -
Parsing HTML Response and Getting Data
To get the data on hotels, parse the HTML response returned by the ‘get_response’ function. For this, you can use the fromstring method of the HTML module of the LXML library.
parser = html.fromstring(response.text)You can use XPATH to find the section where each hotel’s data is present.
hotels_list = parser.xpath("//div[@jsname='mutHjb']")‘hotels_list’ is now a list where each element of the list represents a hotel shown on the web page.
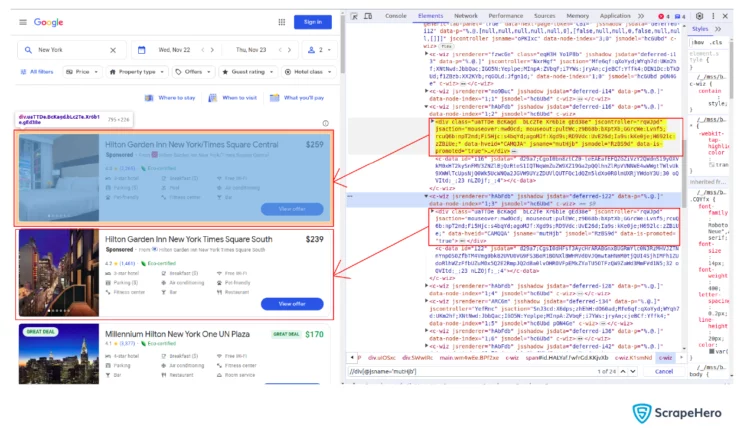
You can then get the specific data points of each hotel by using relative XPATH on the elements in the ‘hotels_list’ list. Data points include the name of the hotel, price, star rating, review count, and amenities provided by the hotel.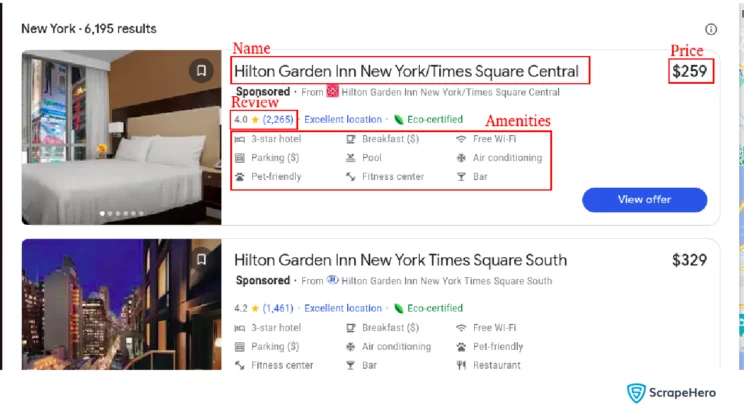
name = hotel.xpath(".//h2[@class='BgYkof ogfYpf ykx2he']/text()") price = hotel.xpath( ".//span[@jsaction='mouseenter:JttVIc;mouseleave:VqIRre;']//text()" )[0] rating = hotel.xpath(".//span[@class='ta47le ']/@aria-label") amenities = get_amenities(hotel) hotel_data = { "name": convert_list_to_str(name), "price": price, "rating": convert_list_to_str(rating), "amenities": convert_list_to_str(amenities, " | ") }The code mentioned gets the details of hotels using XPATH from the HTML element that represents each hotel. This data is saved as a dictionary.
The details of the hotel amenities are not directly accessible. So you have to define a utility function named get_amenities that takes the HTML content of the response as an argument and returns the amenities as a list.
def get_amenities(hotel_html): amenities = hotel_html.xpath(".//span[@class='lXJaOd']/text()") amenities_str = convert_list_to_str(amenities) amenities_list = amenities_str.split(":")[1].split(",") return amenities_listWhen you take data from the HTML using XPATH, you usually get a list. Convert this list to a string before saving the data. convert_list_to_str is responsible for doing this. This function takes a list of strings and joins them using a separator. The default separator is a space character, but it can be modified as needed.
def convert_list_to_str(input_list, separator=" "): cleaned_elements = [] for element in input_list: if element == " ": continue cleaned_element = element.replace("\\", "") cleaned_elements.append(cleaned_element) return separator.join(cleaned_elements)Use a for loop to iterate through all the hotels in the hotels_list and append the data of each hotel to another list named hotels_data. The parse_response function returns this list. So the final parse_response function will be:
def parse_response(response): parser = html.fromstring(response.text) hotels_data = [] hotels_list = parser.xpath("//div[@jsname='mutHjb']") for hotel in hotels_list: name = hotel.xpath(".//h2[@class='BgYkof ogfYpf ykx2he']/text()") price = hotel.xpath( ".//span[@jsaction='mouseenter:JttVIc;mouseleave:VqIRre;']//text()")[0] rating = hotel.xpath(".//span[@class='ta47le ']/@aria-label") amenities = get_amenities(hotel) hotel_data = { "name": convert_list_to_str(name), "price": price, "rating": convert_list_to_str(rating), "amenities": convert_list_to_str(amenities, " | ")} hotels_data.append(hotel_data) return hotels_data -
Saving Data to a CSV File
Save the final data to a CSV file. Since you are returning the hotel data as a list of dictionaries from the parse_response, you can use the ‘DictWriter’ class of the ‘csv’ module for writing the data to a file.
def save_data(data): if not data: return fields = data[0].keys() with open("Hotels.csv", "w") as file: dict_writer = csv.DictWriter(file, fields) dict_writer.writeheader() dict_writer.writerows(data)Putting together all the functions into a main function, you will get:
def main(): query_string = "New York" response = get_response(query_string) if response.status_code == 200: data = parse_response(response) save_data(data) else: print("Invalid Response")Access the full code for Web Scraping Google Hotels Using Python
The Need for Web Scraping Google Hotels
Web scraping Google Hotels is much more than staying updated with the latest information on hotels. In fact, it offers a lucrative solution for individuals as well as businesses to analyze and compare the data from different perspectives. Here are some reasons why you need to scrape Google Hotels:

-
Data Aggregation and Comparison
By web scraping Google Hotels, businesses obtain an extensive amount of data, such as prices, ratings, reviews, and amenities, which helps them give users a comprehensive overview of their options.
-
Competitive Intelligence
Web scraping Google Hotels can provide business intelligence on competitive pricing strategies, customer reviews, and marketing approaches. Businesses can use this information to stay ahead of the competition and make strategic decisions.
-
Price Monitoring and Dynamic Pricing
Businesses can monitor price changes in real time by using Google Hotels scraping data, which makes it easier to develop dynamic pricing strategies. This ensures that businesses remain competitive and responsive to market conditions.
-
Enhanced User Experience
By web scraping Google Hotels, developers can integrate the extracted data into their own applications, providing users with a seamless and enriched experience. Customers can make decisions about their travel plans when they can access precise and thorough information.
-
Market Research and Trends Analysis
Researchers and analysts can conduct in-depth market research and identify emerging trends with Google Hotels web scraping. Businesses can then adapt and cater to changing consumer preferences, making use of this information.
Wrapping Up
To gain a competitive edge and make informed decisions based on hotel data, it is essential to scrape Google Hotels. But a scraper cannot be a final solution if what you require is web scraping on a much larger scale, as you may need to crawl and scrape millions of data points.
ScrapeHero Cloud can serve your purpose as it offers prebuilt crawlers and APIs. If you need affordable alternatives specifically to scraping Google Hotels, then try ScrapeHero Hotel Data Scrapers like Airbnb scraper and Tripadvisor scraper. They are instant, easy-to-use, have predefined data points, and no coding on your part is involved. You will even get 25 free credits during your sign-up.
For enterprise grade scraping, we recommend ScrapeHero Hotel Data Scraping services, which are bespoke, custom, more advanced, and provide for your hotel data requirements.


