

You might have already heard about Google News that curates news from various sources based on user interests. But are you aware that the extraction of news data is possible from Google News with a scraper? If not, you are at the right place to learn web scraping Google News using Python.
This article is a step-by-step guide that helps you create a Google News scraper from scratch. You will also learn to mitigate the potential anti-bot scraping challenges that may occur in between.
Understanding Google News
Before you begin web scraping Google News using Python, it’s important to understand the structure and the HTML elements of Google News. Since it gathers news articles from different sources, this step is crucial before scraping.
- Google News pages consist of multiple news articles displayed in a structured format.
- The HTML structure of the page contains data such as publication dates, headlines, article links, etc.
- Be aware of Google News’ terms of service and scraping guidelines to ensure you’re in compliance with their policies.
Prerequisites
Set up your environment and gather the necessary tools to scrape Google News Results with Python. A virtual environment for your project is essential in order to maintain project dependencies and prevent conflicts. You can use tools like venv or pyenv for setting up virtual environments.
-
Python Installation
Make sure you have installed Python on your system. If not, you can download it from the official Python website. Here, Python version 3.10 is used.
-
Install Third Party Libraries
You need to install the Python libraries– Requests and LXML.
- Requests– For sending HTTP requests and retrieving web content. It is often used for web scraping and interacting with web APIs.
Installation:pip install requests - LXML– Used for parsing and manipulating XML and HTML documents. It is also used for web scraping and working with structured data from web pages.
Installation:
pip install lxml
- Requests– For sending HTTP requests and retrieving web content. It is often used for web scraping and interacting with web APIs.
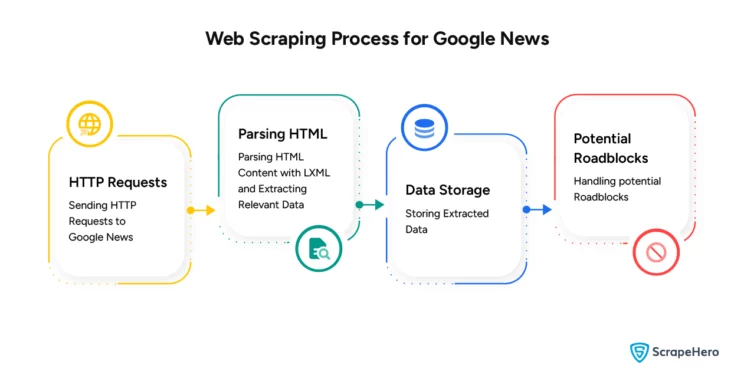
Web Scraping Process for Google News
Web scraping Google News using Python involves a few steps that you need to know. Let’s understand this in detail, from sending HTTP requests to handling the potential roadblocks that may happen when web scraping.
-
Sending HTTP Requests to Google News
The Requests library is used to send HTTP GET requests to Google News. You can then retrieve the HTML content of the pages you want to scrape.
-
Parsing HTML Content with LXML and Extracting Relevant Data
For parsing and navigating HTML, you can use LXML. It can extract the data you need, such as headlines, article links, and publication dates, from the HTML.
-
Data Storage
After web scraping Google News using Python, you can store the data in various formats, like CSV, JSON, or databases, for further analysis.
You will be able to perform data cleaning and preprocessing or conduct analyses like word frequency analysis once the data is stored.
-
Handling Potential Roadblocks
Google implements measures such as rate limiting or user agent restrictions in order to prevent web scraping. But you can scrape websites without getting blocked.
Code Implementation
Now let’s start implementing the code
-
Import Required Libraries
import json import base64 import csv import requests from lxml.html import fromstring -
Making HTTP Request for the Required Search Keyword
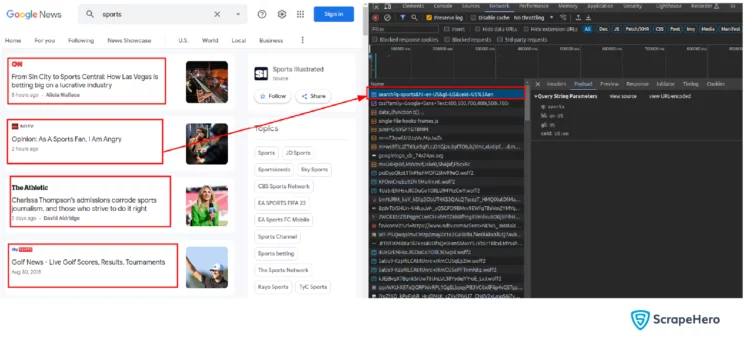
Let’s create a Python function, fetch_html_response, that accepts a keyword and retrieves the HTML response for it.
Before that, let’s find the request that contains the required data. In the screenshot, you are able to see the request, which contains all the required data.
Setting Request Parameters
params = { 'q': search_keyword, 'hl': 'en-US', 'gl': 'US', 'ceid': 'US:en', }Here, create a dictionary called params to store the query parameters for the HTTP request. The parameters include:
‘q’: The search keyword provided as an argument to the function.
‘hl’: Language parameter set to ‘en-US.’
‘gl’: Geographic location parameter set to ‘US.’
‘ceid’: A custom identifier, ‘US:en,’ indicating the region and language.
Making the GET Request
response = requests.get('https://news.google.com/search', params=params, headers=headers)To make an HTTP GET request, the requests.get method is used. The target URL is set to ‘https://news.google.com/search‘. You must provide ‘params’ and ‘headers’ as arguments to the request. This is where the actual HTTP request is made to Google News, with the specified search query and custom headers.
Function
def fetch_html_response(search_keyword): params = { "q": search_keyword, "hl": "en-US", "gl": "US", "ceid": "US:en", } headers = {...} # refer code for complete headers response = requests.get( "https://news.google.com/search", params=params, headers=headers ) return response -
Parsing HTML Content and Extracting Data
Now create a function that takes an HTML response as input and extracts valuable data from it. The function ‘extract_data_from_html’ can parse the HTML content and retrieve specific information like article titles, publication times, and article URLs. This function uses ‘lxml’ along with XPath expressions to navigate and extract data from the HTML structure.
Also Read: XPaths and their relevance in Web ScrapingParsing HTML Response
parser = fromstring(response.text)Extracting HTML Elements with XPath
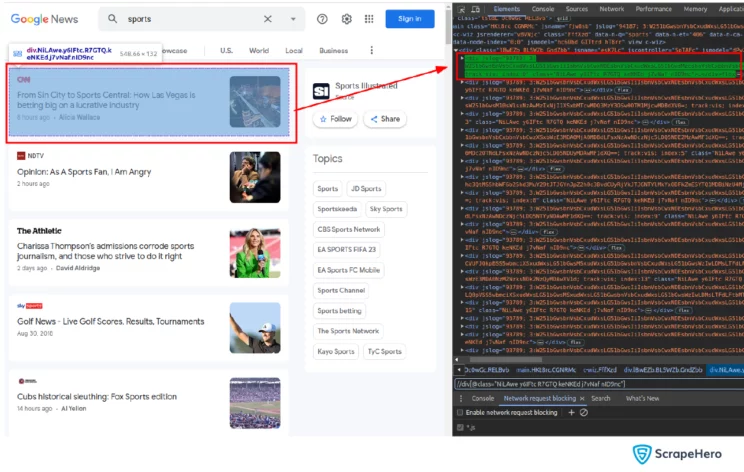
news_tags = parser.xpath('//div[@class="NiLAwe y6IFtc R7GTQ keNKEd j7vNaf nID9nc"]')Here, XPath is used to extract news articles. news_tags is a list of elements containing individual news articles.
Iterating Over News Articles and Extracting Required Data Points
The required data points are highlighted in the screenshot. URL is extracted from the HTML tag.
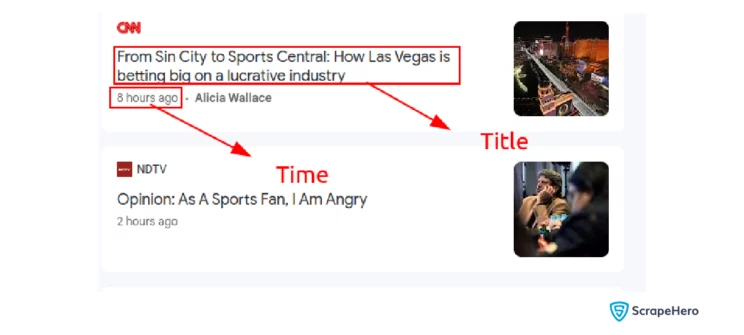
for news_tag in news_tags: title = news_tag.xpath('.//h3[@class="ipQwMb ekueJc RD0gLb"]/a/text()')[0] time = news_tag.xpath('.//time[@class="WW6dff uQIVzc Sksgp slhocf"]/text()')[0] url = news_tag.xpath('.//a[@class="VDXfz"]/@jslog')[0]This loops through the news articles, allowing you to extract the data one by one. Within the loop, you can use relative XPath to extract the article title, time, and URL from each news element.
Decoding URL
The URLs are hidden by Google inside an anchor tag’s jslog property using base64 encoding. To extract these URLs, you can follow the steps mentioned.
The raw data you receive from the website will be similar to:
url = '95014; 5:W251bGwsbnVsbCxudWxsLG51bGwsbnVsbCxudWxsLG51bGwsbnVsbCwiaHR0cHM6Ly93d3cud2FzaGluZ3RvbnBvc3QuY29tL3dvcmxkLzIwMjMvMTEvMjAvaW5kaWEtbmV0ZmxpeC1hbWF6b24tbW92aWVzLXNlbGYtY2Vuc29yc2hpcC8iXQ==; track:click,vis'It has multiple values separated by a semicolon. After splitting with a semicolon, you will get the list:
print(url.split('; ')) # output ['95014', '5:W251bGwsbnVsbCxudWxsLG51bGwsbnVsbCxudWxsLG51bGwsbnVsbCwiaHR0cHM6Ly93d3cud2FzaGluZ3RvbnBvc3QuY29tL3dvcmxkLzIwMjMvMTEvMjAvaW5kaWEtbmV0ZmxpeC1hbWF6b24tbW92aWVzLXNlbGYtY2Vuc29yc2hpcC8iXQ==', 'track:click,vis']The data you need is in the second position.
'5:W251bGwsbnVsbCxudWxsLG51bGwsbnVsbCxudWxsLG51bGwsbnVsbCwiaHR0cHM6Ly93d3cud2FzaGluZ3RvbnBvc3QuY29tL3dvcmxkLzIwMjMvMTEvMjAvaW5kaWEtbmV0ZmxpeC1hbWF6b24tbW92aWVzLXNlbGYtY2Vuc29yc2hpcC8iXQ=='The value has two sections, separated by a colon. You will get the output after splitting it with a colon:
raw_url_data = '5:W251bGwsbnVsbCxudWxsLG51bGwsbnVsbCxudWxsLG51bGwsbnVsbCwiaHR0cHM6Ly93d3cud2FzaGluZ3RvbnBvc3QuY29tL3dvcmxkLzIwMjMvMTEvMjAvaW5kaWEtbmV0ZmxpeC1hbWF6b24tbW92aWVzLXNlbGYtY2Vuc29yc2hpcC8iXQ==' print(raw_url_data.split(':')) # output ['5', 'W251bGwsbnVsbCxudWxsLG51bGwsbnVsbCxudWxsLG51bGwsbnVsbCwiaHR0cHM6Ly93d3cud2FzaGluZ3RvbnBvc3QuY29tL3dvcmxkLzIwMjMvMTEvMjAvaW5kaWEtbmV0ZmxpeC1hbWF6b24tbW92aWVzLXNlbGYtY2Vuc29yc2hpcC8iXQ==']What you need is the second part of it. After extracting the value, you can decode it using the base64 algorithm.
encoded_url'W251bGwsbnVsbCxudWxsLG51bGwsbnVsbCxudWxsLG51bGwsbnVsbCwiaHR0cHM6Ly93d3cud2FzaGluZ3RvbnBvc3QuY29tL3dvcmxkLzIwMjMvMTEvMjAvaW5kaWEtbmV0ZmxpeC1hbWF6b24tbW92aWVzLXNlbGYtY2Vuc29yc2hpcC8iXQ=='After decoding the URL, the mentioned JSON array can be found. You can load it using the JSON library and extract the last string from it.
article_url'[null,null,null,null,null,null,null,null,"https://www.washingtonpost.com/world/2023/11/20/india-netflix-amazon-movies-self-censorship/"]'Now you have created two functions, extract_base64_string and decode_base_64 with the logic mentioned above. You can find the code for the functions here:
Function
def decode_base64(encoded_url): # Decode the base64-encoded URL and convert it to a UTF-8 string decoded_string = base64.b64decode(encoded_url).decode("utf-8") # The line `return json.loads(decoded_string)[-1]` is decoding a JSON string and returning the # last element of the resulting list. return json.loads(decoded_string)[-1] def extract_base64_string(url): # Split the URL by semicolon, then further split the second part by colon to extract the base64 string return url.split(";")[1].split(":")[1]def extract_data_from_html(response): # Initialize an empty list to store extracted data data_scraped = [] parser = fromstring(response.text) news_tags = parser.xpath('//div[@class="NiLAwe y6IFtc R7GTQ keNKEd j7vNaf nID9nc"]') for news_tag in news_tags: title = news_tag.xpath('.//h3[@class="ipQwMb ekueJc RD0gLb"]/a/text()')[0] time = news_tag.xpath('.//time[@class="WW6dff uQIVzc Sksgp slhocf"]/text()')[0] url = news_tag.xpath('.//a[@class="VDXfz"]/@jslog')[0] encoded_url = extract_base64_string(url) article_url = decode_base64(encoded_url) data = { "article_title": title, "time": time, "article_url": article_url, } data_scraped.append(data) return data_scraped -
Save the Extracted Data
Now, proceed by introducing a new function that will enable you to store the extracted data. The function, write_to_csv, takes the data_scraped list, which contains the extracted data, and writes it to a CSV file.
Function
def write_to_csv(data_scraped): csv_file = "news_articles.csv" with open(csv_file, "w", newline="") as csvfile: fieldnames = data_scraped[0].keys() writer = csv.DictWriter(csvfile, fieldnames=fieldnames) writer.writeheader() for row in data_scraped: writer.writerow(row) -
Bypassing Website Blocking Mechanisms Implemented By Google
To bypass the blocking while scraping Google News, you can:
-
Use Proxies
Proxies disguise your IP address and location. It also handles rate limiting, which is often implemented by websites to control the frequency of requests.
-
Go for Header Rotation
Another simple measure is header rotation which makes it harder for the bot-detection services to detect the scraper.
Also Read: HTTP Headers for Web-scraping
-
-
Combining All
# Define the search keyword for web scraping search_keyword = "Sports" # Send an HTTP request and get the HTML response response = fetch_html_response(search_keyword) # Checks response is valid if response.status_code == 200: # Extract data from the HTML and store it in 'data_scraped' data_scraped = extract_data_from_html(response) # Write the extracted data to a CSV file write_to_csv(data_scraped) else: print('Invalid Response')Get the complete code for this article on how to scrape Google News using Python from GitHub.
Use Cases of Google News Scraping
The information scraped from Google News can be turned into insights. Let’s now explore some of the other use cases of Google News Scraping.
-
To Track Brand Mentions
Scraping Google News can help you identify where your brand is mentioned online. It can be used for business intelligence as well.
-
To Monitor Competitor Activity
When you scrape Google News Results with Python, you are updated with industry shifts and emerging trends, which helps in making informed decisions.
-
For Research and Journalism
Web scraping Google News using Python can be considered a gold mine when it comes to research and journalism as it opens up a vast reservoir of up-to-date data.
Wrapping Up
Web scraping Google News using Python can lead to a multitude of opportunities in data analysis, research, and automation. The data that is scraped can be analyzed and utilized for various purposes, including research and journalism.
Using a scraper for Google News is a temporary solution for your web scraping needs on a small scale. You can even make use of our News API, which is a better alternative that allows you to search for articles using multiple combinations of query, sentiment, source, and category. Also, it is hassle-free, and you can integrate it with your application easily.
As far as large-scale news scraping is concerned, better go for ScrapeHero’s services, as we can build custom solutions for you, meeting all your specific needs and ensuring quality.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data


