

Odds Portal is a dynamic, JavaScript-rendered website that aggregates betting odds across sports like NBA basketball and NFL football. The site oddsportal.com is highly dynamic, which means, to build an odds portal scraper, you need a browser automation tool like Selenium to render JavaScript.
What Is OddsPortal and Why Scrape It?
OddsPortal pulls real-time and historical odds from over 80 bookmakers across sports including basketball, football, tennis, and cricket. It displays each bookmaker’s opening and closing odds side by side, line movement, over/under totals, Asian handicap lines, and final scores. In short, you get odds data without a paywall or API subscription.
That makes it a high-value scraping target for several types of users:
- Sports bettors and arbitrage hunters can use scraped OddsPortal data to compare odds across bookmakers in real time.
- Data scientists and quantitative analysts can scrape OddsPortal for historical odds data to train and backtest predictive models.
- Line movement analysts can scrape the same game repeatedly at timed intervals to track how odds shift from open to close.
The demand behind all these use cases is only growing. The global sports betting market was valued at $100.9 billion in 2024 and is projected to reach $187.39 billion by 2030. The data infrastructure behind that market runs on real-time odds feeds, and OddsPortal is one of the most accessible public entry points into that data.
Is Scraping OddsPortal Legal?
Scraping OddsPortal sits in a legal gray area, and the answer depends on what you do with the data.
OddsPortal’s Terms of Service restrict commercial reuse of their data. Using scraped odds for research, academic work, or building private models is generally considered low-risk. Selling the data, embedding it in a commercial product, or redistributing it at scale is where you cross into territory their ToS explicitly prohibits.
However, scraping publicly accessible data is not inherently illegal. The 2022 hiQ v. LinkedIn ruling affirmed that scraping publicly available data does not violate the Computer Fraud and Abuse Act. OddsPortal odds are publicly visible without a login, which puts the data in the same category as other public web content.
That said, two practical limits apply regardless of legality:
- OddsPortal actively deploys bot detection and will block scrapers that send too many requests too quickly. Aggressive scraping can get your IP banned.
- The bookmaker odds displayed on OddsPortal originate from the bookmakers themselves, who have their own data licensing terms. Downstream commercial use of that odds data may implicate those terms independently of OddsPortal’s ToS.
The short version: scraping OddsPortal for personal use, research, or model training is low-risk. Commercial use of the data at scale warrants a closer look at their ToS and, if in doubt, legal advice.
If you need odds data at scale, working with a professional data scraping company like ScrapeHero is a cleaner path. We handle the infrastructure and deliver the data under a proper service agreement, keeping the legal risk off your plate.
What Data Can You Actually Get using an OddsPortal Scraper?
Before writing any code, it helps to know what OddsPortal actually exposes. The site aggregates several distinct data types across its pages, and what you can scrape depends on which page you target.
Match Odds by Market Type
OddsPortal covers multiple betting markets per match. The most commonly scraped are:
- 1X2 (home win, draw, away win): the default view on most pages
- Over/Under totals: points or goals thresholds set by bookmakers
- Asian Handicap: spread-adjusted odds popular in Asian markets
- Draw No Bet: a variant that removes the draw outcome and adjusts odds accordingly
Bookmaker-Specific Odds
Each market page shows odds from individual bookmakers side by side. You can scrape odds from specific bookmakers like Bet365, Pinnacle, and 1xBet, which is useful if you are tracking a particular bookmaker’s line rather than the aggregate.
Opening and Closing odds
OddsPortal stores both the odds at market open and the final odds before the match starts. These are not always visible in the default DOM and require additional handling, covered in the next section.
Historical odds by season
OddsPortal maintains historical results pages organized by sport, league, and season. These pages contain final odds, scores, and bookmaker data going back several years, making them the primary target for anyone building training datasets for predictive models.
Live Scores and Results
Match results are embedded alongside the odds on results pages. You can scrape final scores, match dates, and team names in the same pass as the odds data.
This tutorial below only covers 1X2 NBA odds as a starting point—specifically Team 1 odds, Team 2 odds. Each additional market type and data category listed above follows a similar scraping approach but requires adapting the code to that page’s specific HTML structure.
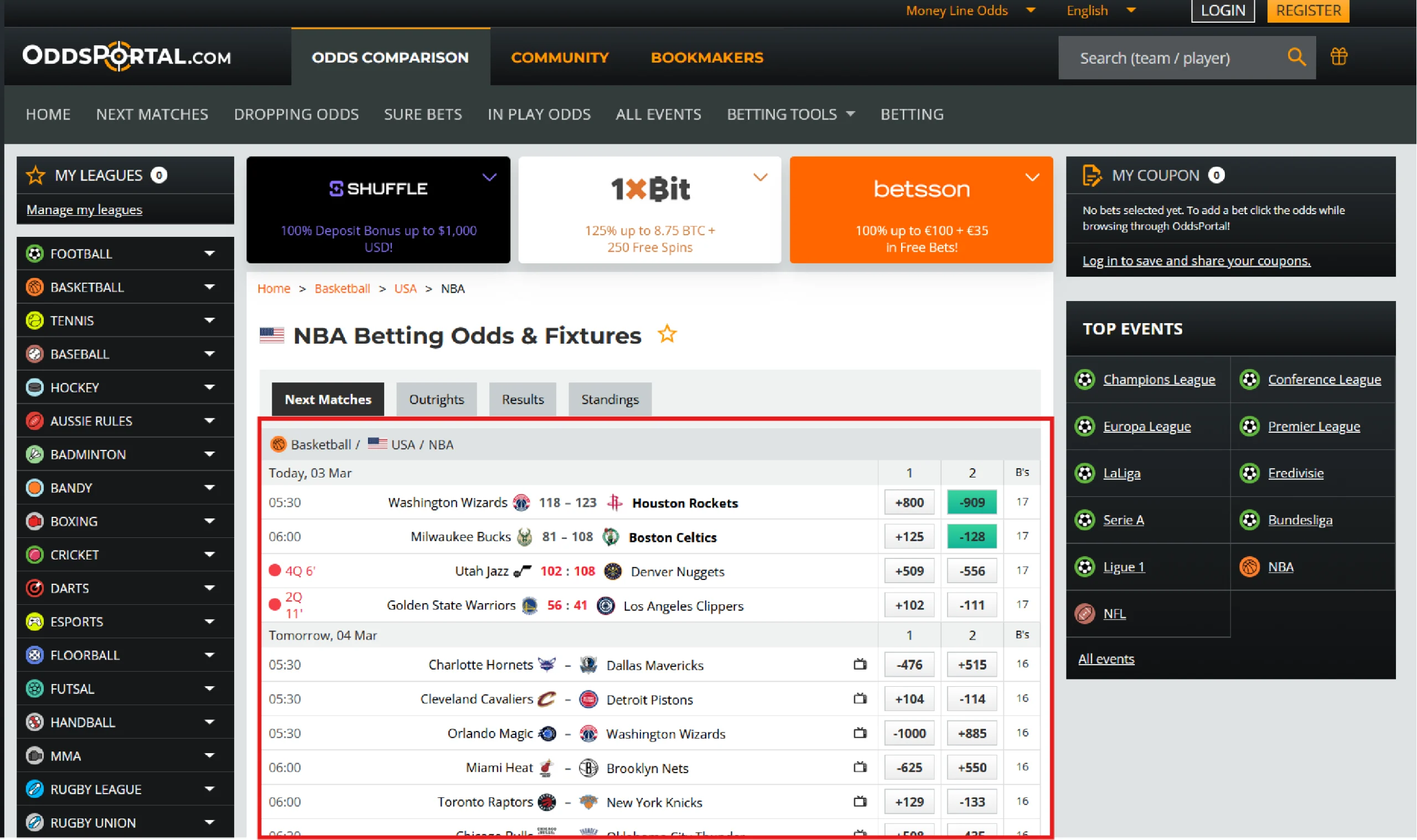
OddsPortal’s structure also varies by sport, so expect to inspect and adjust selectors for each new target.
Tools & Libraries You Need for the Oddsportal Scraper
The script uses Selenium, which is an external Python library used for web scraping dynamic content. Therefore, install Selenium using Python pip.
pip install selenium
The script also uses json and sleep, but since they are in-built Python modules, you don’t need to install them separately.
The Code for Web Scraping OddsPortal.com Betting Odds

If you want to start right away, here’s the full code to scrape OddsPortal.com:
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
import json
driver = webdriver.Chrome()
driver.get("https://www.oddsportal.com/matches/basketball/")
sleep(5)
gameRows = driver.find_elements(By.XPATH, '//div[contains(@class,"eventRow")]')
data = []
date = ""
for row in gameRows:
try:
date = row.find_element(By.XPATH, './/div[@data-testid="date-header"]').text
except:
date = date
time = row.find_element(By.XPATH, './/div[@data-testid="time-item"]').text
participants_row = row.find_element(By.XPATH, './/div[@data-testid="event-participants"]')
participants = participants_row.find_elements(By.XPATH, './/p')
try:
odds = (
row.find_elements(By.XPATH, './/div[@data-testid="odd-container-default"]')
if time != "FIN"
else row.find_elements(By.XPATH, './/div[@data-testid="odd-container-default"]')
+ row.find_elements(By.XPATH, './/div[@data-testid="odd-container-winning"]')
)
team1Odds = odds[0].text
team2Odds = odds[1].text
except:
team1Odds = None
team2Odds = None
data.append({
"Date": date,
"Game State": time,
"Participants": participants[0].text + " Vs." + participants[1].text,
"Team1 Odds": team1Odds,
"Team2 Odds": team2Odds
})
with open("NBA.json", "w") as jsonFile:
json.dump(data, jsonFile, indent=4)
driver.quit()
This script uses the json module to write the extracted data after scraping OddsPortal. It also needs selenium and time.
It only imports two modules from the Selenium library:
- The WebDriver module lets you launch the browser and interact with the website.
By specifies how you will locate elements.
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
import json
After importing the packages, launch a Chrome browser instance and navigate to the OddsPortal basketball matches page.
driver = webdriver.Chrome()
driver.get("https://www.oddsportal.com/matches/basketball/")
sleep(5)
Before scraping a website, you need to identify exactly where the data lives in the page’s code. Here’s how:
- Open DevTools: Right-click on any element on the page and select Inspect (or press F12).
- Locate the element: Hover over items in the Elements panel to highlight the corresponding part of the page, or use the selector tool (the cursor icon) to click directly on the data you want.
- Find the pattern: Look at the HTML tag, class name, or ID associated with that element. For example, a product price might sit inside a <span class=”price”> tag.
- Check for consistency: Verify that the same tag/class pattern repeats across similar items on the page. Consistent patterns are what scrapers rely on.
- Watch for dynamic data: If the element doesn’t appear in the HTML, the data might be loaded via JavaScript. Switch to the Network tab and filter by XHR/Fetch to find the underlying API call instead.
The page may take some time to load, so sleep(5) gives it a moment before you start locating elements.
You can now select each event row using its data-testid attribute.
gameRows = driver.find_elements(By.XPATH, '//div[contains(@class,"eventRow")]')
For finished matches (time == “FIN”), the code looks for both default and winning odd containers to capture the final odds correctly.
Start with an empty list to hold all match records and an empty string to track the current date.
data = []
date = ""
Loop through each event row. Some rows are date headers that group matches by day, and some are individual match rows. The code handles both in the same loop.
for row in gameRows:
Extracting the Date
Not every row contains a date. OddsPortal displays the date once as a header above a group of matches, not on each individual match row.
The try/except handles this: if a date header exists in the current row, update date. If it does not, keep the previous value. This way, every match row inherits the date of the header above it.
try:
date = row.find_element(By.XPATH, './/div[@data-testid="date-header"]').text
except:
date = dateExtracting the Game State and Participants
Extracting the game state is straightforward. Each row has a time-item div that tells you whether the match is upcoming, going on, or already finished; scrape that you get the game state.
For extracting the participants, you need two steps. The team names are both inside a single event-participants div as separate <p> tags. You first grab the parent div, then pull all the <p> tags inside it as a list so you can reference each team by index.
time = row.find_element(By.XPATH, './/div[@data-testid="time-item"]').text
participants_row = row.find_element(By.XPATH, './/div[@data-testid="event-participants"]')
participants = participants_row.find_elements(By.XPATH, './/p')
Extracting the odds
OddsPortal uses different containers for upcoming and finished matches. For upcoming matches, odds sit in odd-container-default. For finished matches, the winning team’s odds move into odd-container-winning while the losing team’s stay in odd-container-default. Combining both containers for finished matches ensures you capture odds for both teams regardless of outcome.
try:
odds = (
row.find_elements(By.XPATH, './/div[@data-testid="odd-container-default"]')
if time != "FIN"
else row.find_elements(By.XPATH, './/div[@data-testid="odd-container-default"]')
+ row.find_elements(By.XPATH, './/div[@data-testid="odd-container-winning"]')
)
team1Odds = odds[0].text
team2Odds = odds[1].text
except:
team1Odds = None
team2Odds = None
If no odds are found, both values are set to None rather than crashing the loop. This handles matches where odds are unavailable or have not yet been posted.
Each iteration also appends one dict to the data list with all five extracted fields.
data.append({
"Date": date,
"Game State": time,
"Participants": participants[0].text + " Vs." + participants[1].text,
"Team1 Odds": team1Odds,
"Team2 Odds": team2Odds
})
Finally, save the extracted data as a JSON file and close the browser.
with open("NBA.json", "w") as jsonFile:
json.dump(data, jsonFile, indent=4)
driver.quit()
Sample Output
[
{
"Date": "Today, 26 May 2026",
"Game State": "19:00",
"Participants": "Memphis Grizzlies Vs. Charlotte Hornets",
"Team1 Odds": "2.14",
"Team2 Odds": "1.74"
},
{
"Date": "Today, 26 May 2026",
"Game State": "FIN",
"Participants": "Dallas Mavericks Vs. Golden State Warriors",
"Team1 Odds": "1.28",
"Team2 Odds": "3.78"
}
]
Code Limitations and Handling Anti-Scraping Measures
This code can scrape dynamically generated NBA odds but might fail for other match odds. The structure of the odds table varies by sport, and the NBA page itself can change. When OddsPortal updates its HTML, your XPaths break and the scraper returns nothing until you manually find the new selectors.
Beyond structure changes, OddsPortal actively rate-limits and blocks scrapers. A standard Selenium setup with default ChromeDriver will get flagged quickly. Here is what you need to handle before running your scraper in any sustained way.
Use Undetected-Chromedriver Instead of Standard ChromeDriver
Standard ChromeDriver exposes browser properties that bot detection scripts check for, like navigator.webdriver being set to true. undetected-chromedriver patches these so the browser fingerprint looks closer to a real user session.
import undetected_chromedriver as uc
driver = uc.Chrome()
Run in Headed Mode, Not Headless
Headless Chrome is easier to detect because several browser properties behave differently without a display. Launch the browser in headed mode while developing and testing your scraper.
Randomize Your Wait Times
Fixed sleep intervals are a bot signal. Replace sleep(5) with a randomized range so your request timing looks less mechanical.
import random
from time import sleep
sleep(random.uniform(3, 7))Rotate User Agents
Sending the same user agent string on every request is another easy flag. Maintain a list of realistic browser user agents and rotate between them across sessions.
from selenium import webdriver
import random
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 Chrome/123.0.0.0 Safari/537.36",
]
options = webdriver.ChromeOptions()
options.add_argument(f"user-agent={random.choice(user_agents)}")
Use a Proxies for Volume
If you are scraping across many matches or running your scraper continuously, a single IP will get rate-limited or banned. Rotating residential proxies distribute your requests across multiple IP addresses. You can pass a proxy into your Selenium session like this:
options.add_argument("--proxy-sesrver=http://your.proxy.address:port")
Want to know more about handling anti-scraping measures? Read this article on how to ethically avoid anti-scraping measures.
When Your Scraper Breaks
OddsPortal redesigns its frontend periodically. When it does, class names change, DOM structure shifts, and XPaths that worked last week return nothing. There is no changelog and no warning.
The signs of a broken scraper are usually one of three things:
- The scraper runs without errors but returns empty data
- The row structure no longer matches your index assumptions and you get key errors
- Bot detection has flagged your IP and you are hitting a Cloudflare block instead of the actual page.
Diagnosing which of these has happened takes time.
Fixing it means opening DevTools, finding the new selectors, updating your code, and retesting. If OddsPortal has made deeper structural changes, the fix can take hours. If you are running this on a schedule and do not notice the break immediately, you have a gap in your data that you cannot backfill.
This is the maintenance reality of scraping a live, actively maintained website. For a personal project or a one-time data pull, it is manageable. For a production data pipeline where continuity matters, it is a recurring cost that compounds over time.
If your use case cannot afford that kind of interruption, a data scraping company is the more reliable path. ScrapeHero monitors, maintains, and updates scrapers on your behalf, so a frontend change on OddsPortal’s end does not become a gap in your dataset.
Fed up with frequent web scraping failures? Read our article on the most common web scraping challenges and how to solve them.
Wrapping Up: Enterprise Scraping with ScrapeHero
The tutorial above works well for personal projects and small-scale data pulls. At enterprise scale, the challenges multiply fast.
OddsPortal serves odds from 80+ bookmakers updating in real time across dozens of sports and thousands of matches simultaneously. Scraping that at volume means managing browser farms, rotating proxies, handling CAPTCHAs, and keeping your scraper updated every time OddsPortal changes its HTML structure.
That maintenance burden adds up quickly, and a broken scraper during a live match window means lost data you cannot recover.
ScrapeHero is your #1 web scraping service that handles all of that for you. We build and maintain enterprise-grade scrapers customized to your exact data requirements, run them on our infrastructure, and deliver clean, structured data on a schedule that works for you. You get the data without the engineering overhead.
If your use case has outgrown a DIY scraper, talk to us.
FAQs
Before scraping a website, you must check three things.
1. Is the data public? You can only scrape public data that isn’t behind a login page or a paywall. Scraping public data doesn’t violate privacy laws or terms of service, but scraping personal information without consent is illegal.
2. Is the website dynamic? Dynamic websites need to render JavaScript before displaying information, meaning standard HTTP request libraries won’t work—you’ll need browser automation tools like Selenium or Playwright.
Odds Portal is a JavaScript-rendered (dynamic) website. The betting odds are not present in the raw HTML response returned by an HTTP request—they are injected into the DOM by JavaScript after the page loads. Libraries like requests and BeautifulSoup do not execute JavaScript, so they will return an empty or incomplete page. You need a browser automation tool like Selenium or Playwright that actually launches a browser and waits for the JavaScript to run.
This is increasingly common as of 2025–2026. Odds Portal’s bot detection identifies standard headless Chrome instances via navigator properties. To mitigate this, use undetected-chromedriver instead of the default ChromeDriver, launch the browser in non-headless mode, add a realistic user-agent string, and randomize your wait times between requests.
No, OddsPortal does not provide an official API for public or commercial access to their odds data. They are a premiere source for odds comparison and historical data, but they do not offer a developer portal, documentation, or an official subscription-based API feed.


