
Lazy loading websites reduce the main content’s load time by loading certain elements only when required. Infinite scrolling is an example of lazy loading of a page. Here, the page loads new content only when you reach the bottom, making it impossible to scrape lazy loading pages with HTTP requests.
However, you can use Selenium to scrape such websites. It is a Python library that can control a browser, interact with websites, and perform functions like scrolling and clicking. In this tutorial, you will learn to scrape lazy-loading websites with Selenium.
Environment Setup
You must have Python and install the necessary packages for scraping lazy-loading websites.
This code uses three external Python libraries.
- Selenium helps you control a browser and interact with the webpage to trigger JavaScript.
- BeautifulSoup4 provides intuitive ways to locate and extract HTML elements.
- Pandas can save the extracted data to a CSV file.
You can use Python’s pip to install these libraries.
pip install selenium beautifulsoup4 pandasData Scraped from the Website
In this tutorial, you will scrape the name and the URL of NFT (non-fungible token) collections from the URL “https://raritysniper.com/nft-collections”. The site uses lazy loading.
To locate each NFT, you must understand the tag and attributes that hold the NFT element. In this case, it is the anchor tag with the class “focus-visible:outline-none.”. You can use the developer options to know these.
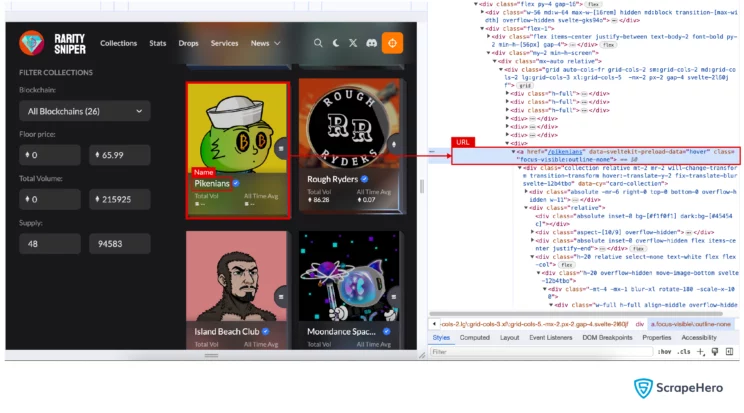
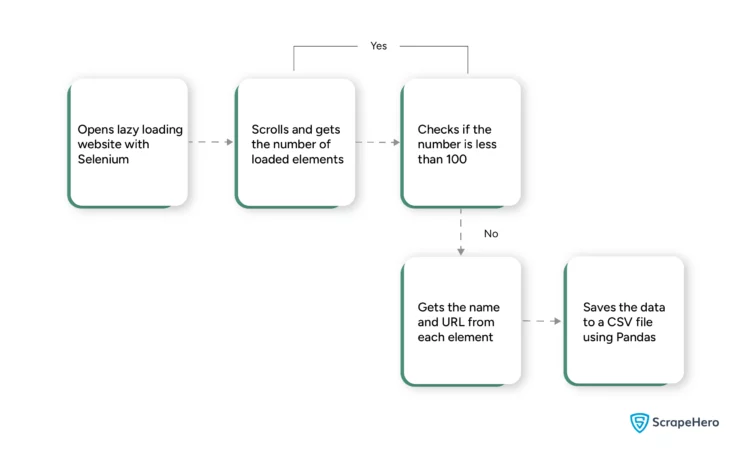
There will be five rows of five NFTs in the beginning. Each time you reach the bottom of the page, five more rows will load. This code scrolls until around 100 NFTs are on the webpage.
After each scroll,
- The code gets the total number of NFTs on the page
- Scrolls again if the number is less than 100
Here is a flow chart that shows how scraping lazy loading pages with Selenium Python works.
The Code to Scrape Lazy Loading Websites
The first step is to import the libraries and modules. You need
- Webdriver to launch the browser
- By to find elements
- Keys to interact with the webpage using keyboard actions
- Pandas to save the file
- BeautifulSoup to extract HTML elements
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
import pandas
import time
The next step is to launch the Chrome browser with the webdriver.Chrome() method. You use a Chrome browser in this tutorial. However, you can use other browsers, including Safari and Firefox.
chrome = webdriver.Chrome()You can visit a webpage using get(). The get() method takes the URL as an argument.
page = chrome.get("https://raritysniper.com/nft-collections")Next, you must scroll to the bottom of the webpage to begin loading new elements. There are several methods to scroll; here, you will use the END key to scroll and reach the end of the page. To press the END key, you can use the send_keys() method.
elem = chrome.find_element(By.TAG_NAME,"html")
elem.send_keys(Keys.END)
time.sleep(3)
elem.send_keys(Keys.HOME)You can see that the code also uses a HOME key after waiting some time. The reason is that the site didn’t start loading the elements after the first execution of the END key. It needed additional interaction.
The above requirement is specific to this site and may not be necessary every time.
After the new elements load, the code
- Gets the page source from the page_source attribute
- Parses using BeautifulSoup
- Gets all the loaded elements with BeautifulSoup’s find_all
- Gets the number of elements
- Continues scrolling until the number of loaded elements is greater than 100.
source = chrome.page_source
soup = BeautifulSoup(source,"html.parser")
a = soup.find_all("a",{"class":"focus-visible:outline-none"})
while(len(a)<100):
elem.send_keys(Keys.END)
source = chrome.page_source
soup = BeautifulSoup(source,"html.parser")
a = soup.find_all("a",{"class":"focus-visible:outline-none"})The scrolling will stop after the page loads around 100 NFTs. You will then extract the name and the URL from each loaded NFT.
To extract the text, you can use the find() method of BeautifulSoup and then get the text attribute.
You can directly get the URL using the syntax to get the attributes. For example, if you want to get the class of an h1 tag, you can use h1[‘class’].
After extracting the name and the URL from each, the code will append them to an array.
file = []
for nft in a:
name = nft.find("div",{"class":"truncate"}).text
url = nft['href']
file.append([name,"https://raritysniper.com/"+url])
df = pandas.DataFrame(file,columns=("name","URL"))Finally, you will use the to_csv() method of Pandas to save the extracted data to a CSV file. You must first convert the file array to a Pandas DataFrame before using to_csv().
df = pandas.DataFrame(file,columns=("name","URL"))
print(df)
df.to_csv("lazy.csv")Limitations of the Code
Although this code will work fine, you must consider some points:
- The identifiers (attributes, tags, etc.) used to locate HTML elements are unique to each website. They depend on the website’s structure, and you must understand them by studying the source code. Moreover, you may have to repeat this process again whenever the site updates the code.
- This code for lazy loading page scraping also does not consider anti-scraping measures such as IP blocking, making it unsuitable for large-scale data extraction.
- The code may also fail to perform because of site-specific reasons. And you need to figure out the cause by trial and error. For example, you had to use additional interactions here to make the code work.
Conclusion
You can scrape lazy-loading pages with Selenium. However, you must update the code as and when the website changes its structure. This means you must analyze the structure and figure out new ways to locate elements.
Moreover, the code is unfit for large-scale data extraction. It would be better to use professional web scraping services like ScrapeHero.
ScrapeHero is an enterprise-grade web scraping service provider capable of large-scale web scraping and crawling. Our massive browser farms can extract data from dynamic websites, including those using lazy loading.


