

Google Play, operated by Google, is the official app store for Android, offering a wide range of apps, games, and media for download. You can scrape Google Play Store reviews of any app using a scraper.
This article will give you an idea of how to scrape customer reviews from Google Play Store by creating a Python scraper using LXML.
Steps To Scrape Google Play Store Reviews
Install the dependencies
pip install requests
pip install lxml
Import the required packages
import re
import csv
import json
from datetime import datetime
import requests
from lxml import htmlThe libraries and modules that are used to scrape Google Play Store reviews include:
- re – Used for doing regex matching to get the required data.
- csv – The final data is saved to a CSV file using the csv module.
- json – Used for parsing JSON objects.
- datetime – This module is used to convert datetime in timestamps to an actual datetime representation.
- requests – Used for sending HTTP requests.
- lxml – The responses received from the HTTP requests are parsed using LXML.
Sending HTTP Request To Get Reviews
In order to get Google Play Store reviews, you can:
- Send a POST request to the URL play.google to obtain the reviews.
- Copy the curl command of a request by right-clicking on it in the network tab of the browser’s developer tool.
- Convert this curl command into any programming language using software like curlconverter.
The above-mentioned request has the parameters:
url = "https://play.google.com/_/PlayStoreUi/data/batchexecute"
headers = {...}
params = {
'hl': 'en',
'gl': 'US'}
data = 'f.req=%5B%5B%5B%22CLXjtf%............'When looking at the payload for this request with different configurations, it is observed that the general format of the data string is:
f"f.req=%5B%5B%5B%22oCPfdb%22%2C%22%5Bnull%2C%5B2%2C{sort}%2C%5B{count}%5D%2Cnull%2C%5Bnull%2C{star_count}%2Cnull%2Cnull%2Cnull%2Cnull%2Cnull%2Cnull%2C{device_id}%5D%5D%2C%5B%5C%22{app_id}%5C%22%2C7%5D%5D%22%2Cnull%2C%22generic%22%5D%5D%5D%0A"This is the format for getting the first set of reviews. If more reviews are present, you will get a token in response to this request. Using this token, you’ll get the next set of reviews. In that case, the format of the data string will be:
f"f.req=%5B%5B%5B%22oCPfdb%22%2C%22%5Bnull%2C%5B2%2C{sort}%2C%5B{count}%2Cnull%2C%5C%22{pagination_token}%5C%22%5D%2Cnull%2C%5Bnull%2C{star_count}%2Cnull%2Cnull%2Cnull%2Cnull%2Cnull%2Cnull%2C{device_id}%5D%5D%2C%5B%5C%22{app_id}%5C%22%2C7%5D%5D%22%2Cnull%2C%22generic%22%5D%5D%5D%0A"You can change these parameters in the payload:
- sort – An integer that represents in what order the reviews should be sorted. Available options are:
sort = { "MOST_RELEVANT": 1, "NEWEST": 2, "RATING": 3 } - count – The number of reviews that you should get in response to a request.
- pagination_token – Used when requesting for succeeding sets of reviews. It can be accessed from the response of a request to the review url.
Note: The first request doesn’t need a token. If there are extra reviews, you’ll get a pagination token for more. If not, it means that there are no more reviews. - star_count – This integer will be used to determine the star count of reviews to be returned in the response. Available options are:
star_count = { "all": "null", "1_star": 1, "2_star": 2, "3_star": 3, "4_star": 4, "5_star": 5 } - device_id – This integer will indicate from which device the reviews should be retrieved in the response. Available options are:
device_id = { "mobile": 2, "tablet": 3, "watch": 4, "chromebook": 5, "tv": 6 } - app_id – Each app has a unique app ID that isn’t based on its name. To find this id, you can search for the app on Google Play and extract the id from the HTML response of this request.
For this, you must create a ‘get_app_id’ function using the app name as the argument; it returns the app_id if a matching app is found; otherwise, it won’t return anything.
The final ‘get_app_id’ function will be:def get_app_id(search_query: str) -> str: url = "https://play.google.com/store/search" params = { 'q': search_query, 'c': 'apps', 'hl': 'en', 'gl': 'US', } headers = {...} response = requests.get(url=url, headers=headers, params=params) parser = html.fromstring(response.text) try: app_id = parser.xpath("//a[@class='Qfxief']/@href")[0].split("id=")[1] return app_id except Exception: print("No matching apps were found")
Now you have understood how you can extract the reviews from the response to the request.
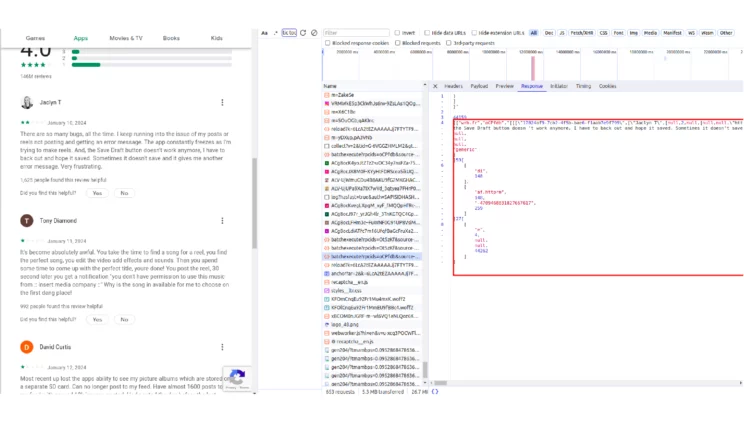
This is the response as seen in the developer tools. The highlighted portion is where all the details are present. This portion forms a nested list, and this list can be extracted using a regex.
review_response_cleaned = re.findall(r"\)]}'\n\n([\s\S]+)", review_response.text)[0]From the nested list, you can extract all the reviews as well as the pagination token required for sending the succeeding request using list indexing.
raw_reviews = json.loads(json.loads(review_response_cleaned)[0][2])[0]
pagination_token = json.loads(json.loads(review_response_cleaned)[0][2])[-2][-1]Now the raw_reviews list has n reviews in it, where n is the count you gave in the payload. Each of these review elements will contain the full details of that review. You can extract only the required fields by iterating through the raw_reviews list.
reviews = []
for raw_review in raw_reviews:
review = {
"reviewer_name": raw_review[1][0],
"review_content": raw_review[4],
"review_date": datetime.fromtimestamp(raw_review[5][0]),
"star_count": raw_review[2],
"review_likes": raw_review[6]
}
reviews.append(review)With all these details, you can implement a get_reviews function. For simplicity of code, let’s give some default values for the parameters in the payload, except for app_id.
Let’s write a get_reviews function that will get the latest 50 requests for an application.
def get_reviews(app_id: str, count: int = 50,device_id: int = 2,
pagination_token: str = None, sort: int = 2, star_count: int = None) -> list[dict]:
if not star_count:
star_count = 'null'
url = "https://play.google.com/_/PlayStoreUi/data/batchexecute"
headers = {...}
params = {
'hl': 'en',
'gl': 'US'
}
if pagination_token:
data = f'f.req=%5B%5B%5B%22oCPfdb%22%2C%22%5Bnull%2C%5B2%2C{sort}%2C%5B{count}%2Cnull%2C%5C%22{pagination_token}%5C%22%5D%2Cnull%2C%5Bnull%2C{star_count}%2Cnull%2Cnull%2Cnull%2Cnull%2Cnull%2Cnull%2C{device_id}%5D%5D%2C%5B%5C%22{app_id}%5C%22%2C7%5D%5D%22%2Cnull%2C%22generic%22%5D%5D%5D%0A'
else:
data = f'f.req=%5B%5B%5B%22oCPfdb%22%2C%22%5Bnull%2C%5B2%2C{sort}%2C%5B{count}%5D%2Cnull%2C%5Bnull%2C{star_count}%2Cnull%2Cnull%2Cnull%2Cnull%2Cnull%2Cnull%2C{device_id}%5D%5D%2C%5B%5C%22{app_id}%5C%22%2C7%5D%5D%22%2Cnull%2C%22generic%22%5D%5D%5D%0A'
review_response = requests.post(url=url, headers=headers,
params=params, data=data, timeout=30)
if review_response.status_code != 200:
print('There was an issue with the request')
return
review_response_cleaned = re.findall(
r"\)]}'\n\n([\s\S]+)", review_response.text)[0]
raw_reviews = json.loads(json.loads(review_response_cleaned)[0][2])[0]
pagination_token = json.loads(
json.loads(review_response_cleaned)[0][2])[-2][-1]
reviews = []
for raw_review in raw_reviews:
review = {
'reviewer_name': raw_review[1][0],
'review_content': raw_review[4],
'review_datetime': datetime.fromtimestamp(
raw_review[5][0]).isoformat(),
'star_count': raw_review[2],
'review_likes': raw_review[6]
}
reviews.append(review)
return (reviews, pagination_token)You’ve implemented the get reviews function that fetches the latest 50 reviews for the mobile version of the app using its ID. It returns a list of dictionaries representing the reviews along with the pagination token to get the next 50 reviews.
To demonstrate how this pagination token works, let’s create a function called review_pagination and scrape it so that it fetches the first 1000 reviews of an app. This function takes the app_id and number of pages as its arguments and uses the get reviews function.
The function will be:
def review_pagination(app_id: str, page_count: int = 20) -> list[dict]:
all_reviews = []
pagination_token = None
current_page = 1
while True:
reviews, pagination_token = get_reviews(
app_id, pagination_token=pagination_token)
all_reviews.extend(reviews)
if not pagination_token or current_page == page_count:
break
current_page += 1
return all_reviewsThe all_reviews list will have the first 1000 reviews of the app. You can save this final data to a CSV file. Since the reviews are returning a list of dictionaries, you can use the ‘DictWriter’ class of the ‘csv’ module for writing the data to a file.
def save_data(data: list[dict]):
if not data:
return
fields = data[0].keys()
with open('app_reviews.csv', 'w') as file:
dict_writer = csv.DictWriter(file, fields)
dict_writer.writeheader()
dict_writer.writerows(data)
Access the complete code for scraping reviews from the Play Store on GitHub.
Use Cases of Scraping Google Play Reviews
1. User Feedback Analysis
Scraping reviews from Play Store helps developers and product managers analyze user feedback in bulk to understand sentiments, identify issues, and measure app satisfaction.
2. Feature Improvement
Developers can scrape Google Play Store reviews and analyze them to identify what users like or dislike about the app, guiding them to improve or add features accordingly.
3. Bug Detection
A Google Play App Review Scraper can quickly spot and help fix bugs or technical issues reported in reviews by offering a consolidated view of the problems.
4. Competitive Analysis
When you scrape Google Play Store reviews, you can compare your product with those of your competitors‘. This gives you insights into market trends, customer expectations, and opportunities for your app to excel.
5. Customer Satisfaction Tracking
Monitoring reviews over time allows developers to see how updates affect customer satisfaction and adjust the app based on user feedback.
6. Reputation Management
A scraper helps in managing an app’s reputation by quickly responding to negative reviews and appreciating positive ones, helping to maintain a favorable user perception.
7. Marketing Insights
Analyzing user reviews offers insights for marketing, using positive feedback for promotion, and addressing negatives to enhance the app’s reputation.
8. Enhanced Decision-Making
When you scrape Google Play Store, the data obtained is used to make informed decisions. The developers can then focus on updates and improvements that users most frequently request.
9. Product Iteration
Scraping reviews from the Play Store aids in continuous customer feedback, which must be analyzed for an iterative development process. This enables the developers to refine the product based on user reactions to updates.
10. Automated Monitoring
A scraper created to scrape Google Play Store reviews can automate collecting reviews, saving time and keeping developers updated with user feedback continuously.
Wrapping Up
Scraping reviews from Play Store can provide valuable insights, but the challenges that come with it cannot be ignored completely. This includes IP blocking, legal issues, and data accuracy. In most cases, storing large volumes of review data may also become a challenge.
To overcome these challenges and scrape hassle-free, you may make use of the ScrapeHero Cloud. It offers scrapers specifically designed for scraping Google, from the Google Reviews Scraper to the Google Maps Search Results. ScrapeHero ready-made web scrapers are easy to use, free of charge up to 25 initial credits, and no coding is involved from your side.
For enterprise-scale web scraping needs, you consider ScrapeHero Web Scraping Services. We can offer you tailored solutions that cater to your specific needs with our expertise in technologies, skills, and experience.
Frequently Asked Questions
Yes, you can scrape Google Play Store. You can either manually scrape web pages using libraries like LXML or BeautifulSoup, or else you can use third-party libraries such as google-play-scraper in Node.js or google-play-scraper in Python. You can also rely on the Google Play Apps Store APIs available online.
Different methods can be used to analyze Play Store reviews that could provide valuable insights into user satisfaction, preferences, and issues regarding mobile apps. These reviews are especially useful in sentiment analysis, topic modeling, competitor analysis, and anomaly detection.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



