

Web scraping refers to getting information from the internet, and sentiment analysis means analyzing the tone behind the text. Therefore, sentiment analysis with web scraping can extract sentiment data from websites.
In this article, you will learn how to scrape data from the internet and perform sentiment analysis using Python.
Advantages of Using Web Scraping for Sentiment Analysis
Sentiment analysis using web scraping has several advantages. You can
- Get ample amounts of publicly available data.
- Get contextual information for a more precise analysis.
- Automatically collect and update the database for sentiment analysis.
- Reduce the cost related to database maintenance.
Web Scraping for Sentiment Analysis: The Code
This article uses Python to perform sentiment analysis using web scraping. The Python code in this article will scrape headlines and excerpts from “https://www.theatlantic.com/world/” and performs sentiment analysis on it.
Packages to Import
The code uses
- Python requests to get HTML code from the URL
- BeautifulSoup to parse and extract data
- Textblob, NLTK, Pytorch, and Transformers to perform sentiment analysis
- Matplotlib and Seaborn for plotting
- The re module for using RegEx
code>import requests
from bs4 import BeautifulSoup
import re
from nltk.corpus import stopwords
from nltk.stem import SnowballStemmer
from nltk.tokenize import word_tokenize
import nltk
#nltk.download("punkt")
from textblob import TextBlob
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import torch
from transformers import pipeline
Functions to Define
The code uses four functions:
- getText() to scrape data
- clean() to prepare data for sentiment analysis
- sentiment_analysis() performs the analysis
- plot() generates the histograms based on the analysis
getText
This function extracts the required text from the URL mentioned above.
It sends an HTTP request and accepts the response. This response will have the HTML content of the web page, which it parses using BeautifulSoup.
response = requests.get("https://theatlantic.com/world")
soup = BeautifulSoup(response.text,"lxml")BeautifulSoup extracts the text of each article listings in two steps:
- Locate the article tags that contain the headlines and the excerpts.
articles = soup.find_all("article") - Iterate through the articles and get the text.
text = [] for article in articles: data = "" if article.h1: data = data + article.h1.text + " " if article.h2: data = data + article.h2.text + " " if article.div.a: if article.div.a.h3: data = data + article.div.a.h3.text + " " if article.p: data = data + article.p.text text.append(data)
clean
The clean function calls getText(), gets the scraped text, and prepares it for sentiment analysis.
Preparation is necessary as sentiment analysis does not consider punctuation or stopwords. Stopwords are common words that are not important for determining the sentiment.
Moreover, it is also better to make the case of the entire text similar to avoid similar words.
To clean the text:
- Convert the text to lowercase
t = t.lower() - Remove everything except alphanumeric characters, underscores, and white spaces.
t = re.sub(r"[^ws]"," ",t) - Remove stopwords
tokens = word_tokenize(t) tokens = [snowball .stem(word) for word in tokens if word not in stop_words ]
Here, the snowball.stem(word) reduces the word to its basic form to simplify the analysis. For example, ‘running’ becomes ‘run,’ which is easier to analyze.
sentiment_analysis
This function calls clean() and performs sentiment analysis on the text returned. It uses two popular libraries for the analysis: transformers and textblob.
Both Textblob and Transformers are open-source libraries. However, the organization Hugging Face actively maintains the Transformers library, while the Textblob library needs more active maintenance.
Textblob gives two metrics for sentiment analysis: polarity and subjectivity.

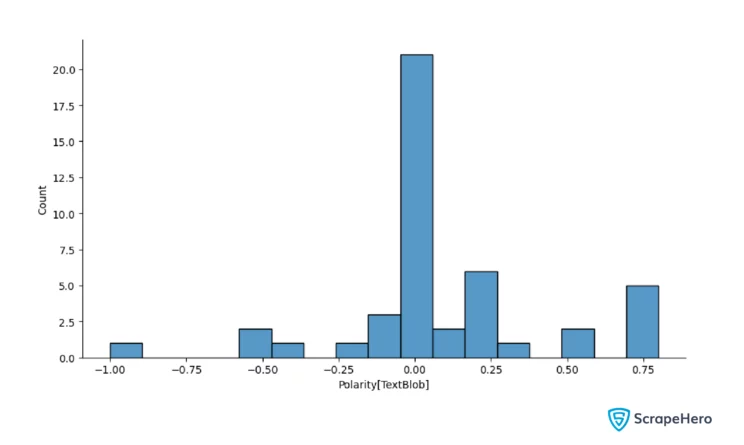
Polarity tells you how positive a text is. You get a rating from -1 to 1 in Textblob, where 1 is positive, and -1 is negative.
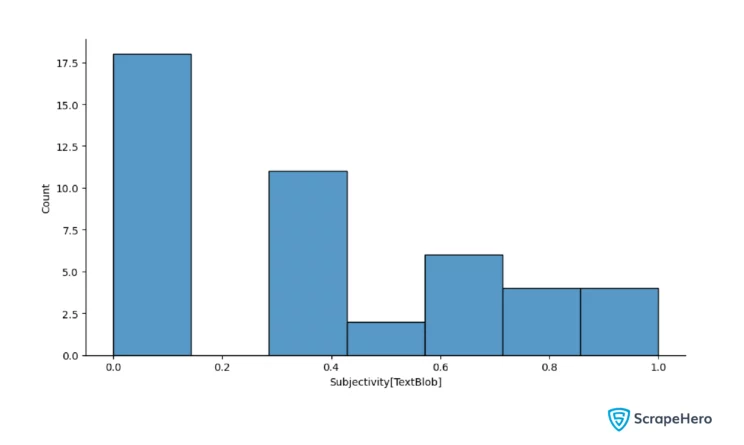
Subjectivity tells you how opinionated the text is. Textblob gives values ranging from 0 to 1 for subjectivity, where 0 is factual, and 1 is subjective.
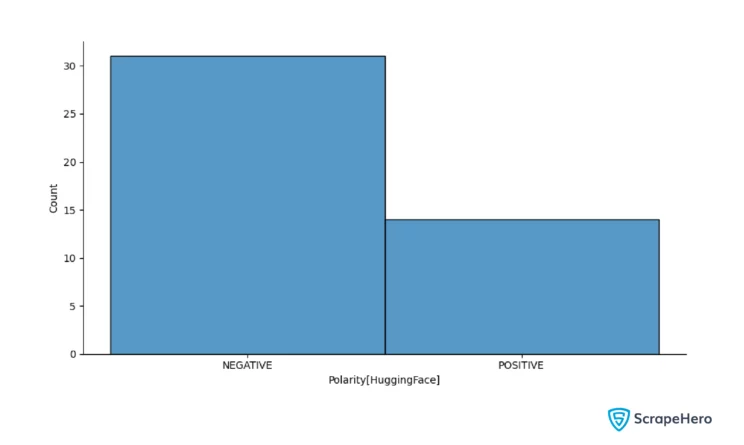
The model distilbert−base−uncased−finetuned−sst−2−english used by the Transformers library classifies the text as positive or negative and provides a probability of that classification.
To use Textblob, loop through the article text. For each, create a Textblob object and get polarity and subjectivity.
for t in text:
blob = TextBlob(t)
subjectivity = blob.subjectivity
polarity = blob.polarity
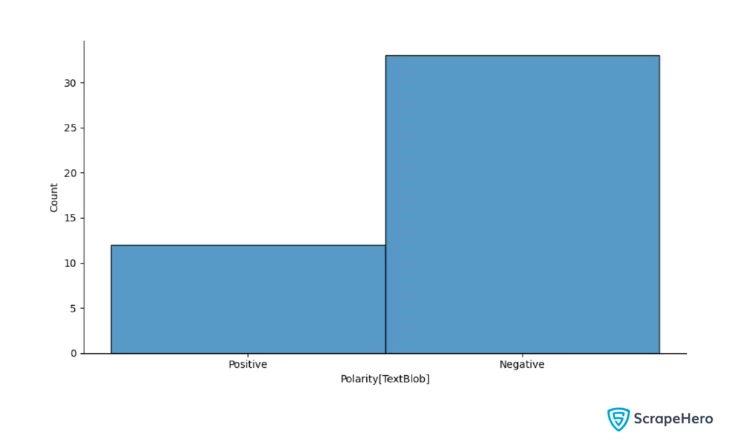
label = "Positive" if polarity >0 else "Negative"
sentiment.append([t,polarity,subjectivity,label])To use the transformers library, create a sentiment-analysis pipeline.
sentiment_pipeline = pipeline("sentiment-analysis",model="distilbert/distilbert-base-uncased-finetuned-sst-2-english")Then, iterate through the text, but use the pipeline you created in the earlier step.
huggingSentiment = []
for t in text:
huggingSentiment.append(sentiment_pipeline(t)[0])plot
This function plots the analyzed data as a histogram. The plot() function
- Calls sentiment_analysis and gets the analyzed data
- Converts the analyzed data into a Pandas data frame
- Uses the displot() method to plot a histogram
Here is the complete code for scraping data for sentiment analysis.
import requests
from bs4 import BeautifulSoup
import re
from nltk.corpus import stopwords
from nltk.stem import SnowballStemmer
from nltk.tokenize import word_tokenize
import nltk
#nltk.download("punkt")
from textblob import TextBlob
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import torch
from transformers import pipeline
def getText():
response = requests.get("https://theatlantic.com/world")
soup = BeautifulSoup(response.text,"lxml")
articles = soup.find_all("article")
text = []
for article in articles:
data = ""
if article.h1: data = data + article.h1.text + " "
if article.h2: data = data + article.h2.text + " "
if article.div.a:
if article.div.a.h3: data = data + article.div.a.h3.text + " "
if article.p: data = data + article.p.text
text.append(data)
return text
def clean():
snowball = SnowballStemmer("english")
stop_words = set(stopwords.words("english"))
text = getText()
clean_text = []
for t in text:
t = t.lower()
t = re.sub(r"[^ws]"," ",t)
tokens = word_tokenize(t)
tokens = [snowball.stem(word) for word in tokens if word not in stop_words ]
t = " ".join(tokens)
clean_text.append(t)
return clean_text
def sentiment_analysis():
sentiment =[]
text = clean()
for t in text:
blob = TextBlob(t)
subjectivity = blob.subjectivity
polarity = blob.polarity
label = "Positive" if polarity >0 else "Negative"
sentiment.append([t,polarity,subjectivity,label])
sentiment_pipeline = pipeline("sentiment-analysis",model="distilbert/distilbert-base-uncased-finetuned-sst-2-english")
huggingSentiment = []
for t in text:
huggingSentiment.append(sentiment_pipeline(t)[0])
print(huggingSentiment)
return {"textblob":sentiment,"huggingFace":huggingSentiment}
def plot():
analyzed = sentiment_analysis()
textblob = analyzed["textblob"]
df_textblob = pd.DataFrame(textblob,columns=["Text","Polarity","Subjectivity","Label"])
huggingFace = analyzed["huggingFace"]
df_hugging = pd.DataFrame(huggingFace)
sns.displot(df_textblob["Polarity"], height= 5, aspect=1.8)
plt.xlabel("Polarity Score[TextBlob]")
plt.show()
sns.displot(df_textblob["Label"], height= 5, aspect=1.8)
plt.xlabel("Polarity Classification[TextBlob]")
plt.show()
sns.displot(df_textblob["Subjectivity"], height= 5, aspect=1.8)
plt.xlabel("Subjectivity[TextBlob]")
plt.show()
sns.displot(df_hugging["label"],height=5, aspect=1.8,)
plt.xlabel("Polarity[HuggingFace]")
plt.show()
plot()And here are the plots.
Code Limitations
This code only scrapes headlines and excerpts, which are insufficient to accurately determine an article’s tone. You need the complete article text for that.
Moreover, you must watch The Atlantic website for changes in its HTML structure as this code relies on it. If the structure changes, the code will fail to locate and extract the required text. And you must update the getText() function if that happens.
Sentiment Analysis Using Web Scraping: Use Cases
Here are some situations where sentiment analysis using web scraping would be helpful.
- Scraping blogs of competitors to watch their tone
- Scraping and performing sentiment analysis on reviews of your product on Amazon
- Determining your company’s employee satisfaction by scraping data from sites such as Glassdoor
Wrapping Up
Web scraping and sentiment analysis can be pretty powerful when used together. This article showed you how to perform sentiment analysis using web scraping with Python.
However, the code used in the article only considers headlines and excerpts, and the results may not accurately reflect the sentiment of each article. You need to alter the code for that.
Moreover, you must also update your code according to changes in The Atlantic’s HTML structure.
If you don’t want to alter or update the code yourself, contact ScrapeHero.
ScrapeHero provides enterprise-grade web scraping services. We can build large-scale, high-quality web scrapers and crawlers customized to your specifications. You can then focus only on sentiment analysis.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



