

TikTok has emerged as a vast repository of entertaining content in the realm of social media, with millions of users worldwide. The data obtained after web scraping TikTok can be invaluable for researchers, marketers, and data enthusiasts.
In this article, let’s learn how to scrape TikTok’s ‘For You’ page using Playwright browser automation and extract data points such as likes, shares, comments, usernames, and descriptions.
Prerequisites
You need to set up an environment and gather the necessary tools before web scraping TikTok.
1. Python Installation
Install Python on your system. Here Python version 3.10 is used.
2. Install Third Party Libraries
You’ll need the Python library:
Playwright – Playwright is used for browser-based automation. It is used for web scraping as well as interacting with web APIs.
Installation:
pip install playwrightInstall the required browsers:
playwright installUnderstanding TikTok
Before learning how to scrape data from TikTok, you should first understand TikTok’s ‘For You’ page. This page showcases trending and personalized content that is tailored to each user’s preferences. Once you scrape data from TikTok, it can be used for analysis, ranging from user engagement metrics to content trends.
1. Importing Libraries
For web scraping TikTok using Python you need to import necessary libraries.
import asyncio
import csv
from playwright.async_api import Playwright, async_playwrightNote that ‘asyncio’ is for asynchronous execution, ‘csv’ for handling CSV files, and ‘Playwright’ for browser automation.
2. Browser Launch and Page Creation
The code lines mentioned can launch a Chromium browser, create a new browser context, and open a new page within that context.
browser = await playwright.chromium.launch(headless=False)
context = await browser.new_context()
page = await context.new_page()3. Navigation and Element Interaction
Homepage
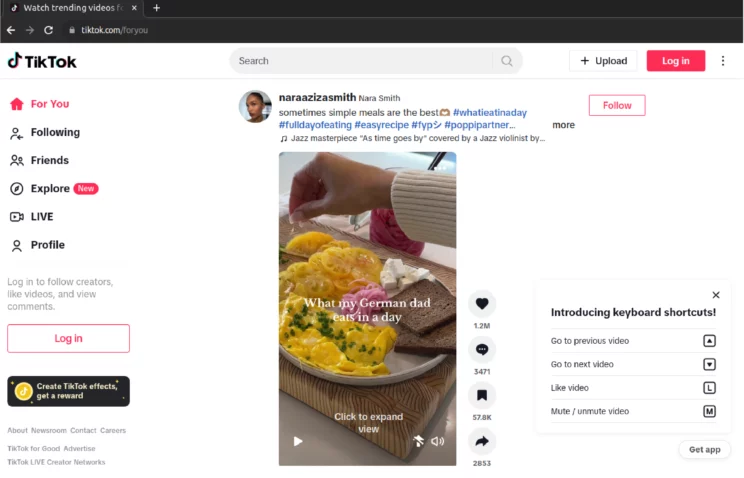
await page.goto("https://www.TikTok.com/foryou", timeout=120000)Pop-up to be Handled
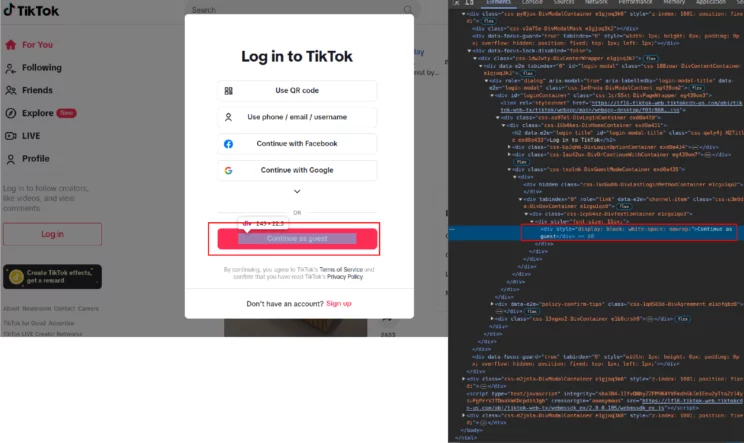
await page.locator('//div[@id="loginContainer"]').wait_for()
await page.get_by_role("link", name="Continue as guest").click()
await page.wait_for_timeout(2000)Here, you navigate to the TikTok “For You” page, wait for the login container to appear, click on the “Continue as guest” link, and wait for 2 seconds.
4. Data Extraction
You can extract usernames, descriptions, likes, comments, shares, and other data from the TikTok page using specific CSS selectors.
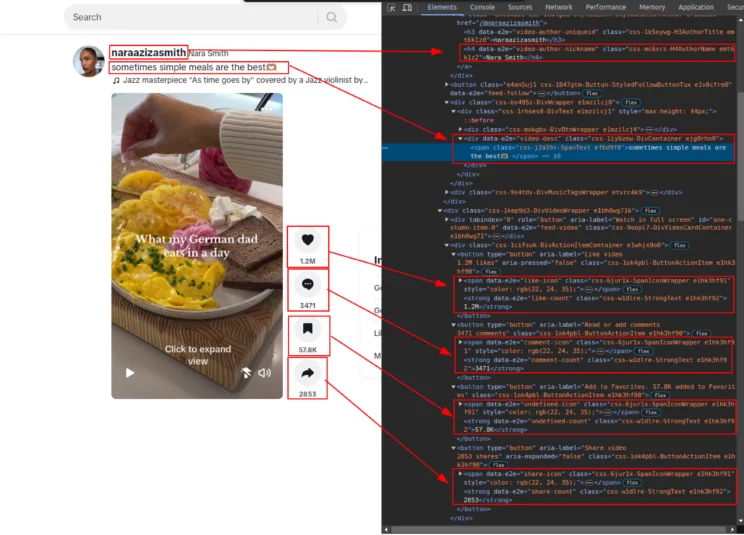
usernames = await extract_text(page, 'h3[data-e2e="video-author-uniqueid"]')
descriptions = await extract_text(page, 'div[data-e2e="video-desc"]')
likes = await extract_text(page, 'strong[data-e2e="like-count"]')
comments = await extract_text(page, 'strong[data-e2e="comment-count"]')
shares = await extract_text(page, 'strong[data-e2e="share-count"]')
others = await extract_text(page, 'strong[data-e2e="undefined-count"]')4.1 extract_text(page, selector)
Based on a provided CSS selector, this function extracts text content from elements on a web page. It also accepts the input parameters page and selector.
Note that Page is a playwright page object on which the extraction is performed, and selector is an XPath or CSS selector used to identify the elements containing the required data.
async def extract_text(page, selector):
elements = await page.query_selector_all(selector)
texts = []
for element in elements:
texts.append(await element.inner_text() if element else "")
return texts5. CSV Writing
Write the extracted data into a CSV file.
write_to_csv([usernames, descriptions, likes, comments, shares, others])5.1 write_to_csv(data_lists)
This function is used to write data to a CSV file. Here data_lists are lists of data to be written to the CSV file, each list corresponding to a column.
def write_to_csv(data_lists):
headers = ["Username", "Description", "Likes", "Comments", "Shares", "Others"]
filename = "instagram_extracted_data.csv"
with open(filename, "w", newline="") as csvfile:
writer = csv.writer(csvfile)
writer.writerow(headers)
for row in zip(*data_lists):
writer.writerow(row)6. Browser Closure
As a final step, close both the browser context and the browser itself.
await context.close()
await browser.close()Access the complete code for the TikTok scraper on GitHub.
Wrapping Up
Web scraping TikTok using Python Playwright offers numerous opportunities for data analysis, content monitoring, and trend tracking. But TikTok web scraping is challenging due to its anti-scraping measures like rate limits and IP blocking.
Moreover, the video content and login requirements of TikTok make it even more difficult, especially for large-scale web scraping. In such situations, you need an enterprise-grade web scraping service provider like ScrapeHero.
The pre-built crawlers and APIs of ScrapeHero Cloud can provide you with hassle-free, affordable, fast, and reliable solutions for your scraping needs. ScrapeHero web scraping services can develop custom solutions for your businesses, providing unmatched data quality and consistency.
Frequently Asked Questions
It is not illegal to scrape publicly available data on the web, including TikTok. But it has to comply with the laws and regulations of the country.
To pull or extract data from TikTok, you can either use the TikTok scraper in Python discussed in this article or else use the TikTok Developer API. For large-scale web scraping, we recommend using ScrapeHero services.
You can either use various third-party TikTok scrapers and services or reach out to TikTok for potential partnerships or collaborations.
You can scrape TikTok followers by creating a Python scraper using BeautifulSoup or Selenium. If coding is not your area of expertise, then consult ScrapeHero web scraping services to meet your data requirements.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data


