

You might be familiar with web scraping using the popular languages Python and JavaScript. You might have also done web scraping in R. But have you ever thought of trying web scraping in Rust? If not, Rust is certainly worth considering.
Rust offers many advantages in terms of higher concurrency, a reliable and faster scraper, and a smaller resource footprint, which make it a compelling choice for web scraping.
This article provides a comprehensive guide to web scraping with Rust using the Reqwest library. Let’s build a simple scraper and scrape the website ScrapeMe to extract Pokemon data.
Prerequisites
- Understand the basics of Rust.
- Install Rust on your computer.
- Learn the basics of Cargo (package manager in Rust, which comes pre-installed with Rust).
Creating a New Project in Rust
Web scraping in Rust can begin with creating a new project in Rust using Cargo with the command:
$ cargo new scrapeme_scraperFind the following output in the terminal:
Created binary (application) `scrapeme_scraper` packageAlso, create a similar directory in the folder.
.
└── scrapeme_scraper/
├── src/
│ └── main.rs
├── Cargo.toml
├── .gitignore
└── .git # git will be preconfigured by defaultYou can find the main.rs file in the src/ directory. Here, you can write the scraper.
After that, test run the project by executing the given command after moving into the directory “scrapeme_scraper”:
$ cargo runThe output is a “Hello, world!” message, as shown:
Compiling scrapeme_scraper v0.1.0 (~/scrapeme_scraper)
Finished dev [unoptimized + debuginfo] target(s) in 0.86s
Running `target/debug/scrapeme_scraper`
Hello, world!Your project is successfully set up once you see this message.
Installing the Dependencies
Use Cargo to install the 3 dependencies:
- Reqwest– To send HTTP requests. This article chooses the blocking feature, but if you need a complex concurrent scraper, then you can opt for the non-blocking default package.
- Scraper– To parse and extract data from HTML using CSS Selectors. You can also use alternative libraries.
- CSV– To write data to CSV files.
$ cargo add reqwest -F blocking
$ cargo add scraper
$ cargo add csvWriting the Scraper
Open the src/main.rs file to see the already defined main function:
fn main() {
println!("Hello, world!");
}This just prints “Hello, world!” to the terminal. You can replace the body with the scraper.
Flow of the scraper:
- Go to https://scrapeme.live/shop/
- Extract Pokemon URLs
- Go to each of the products
- Extract the Pokemon details, such as title, price, description, SKU, and stock count
Sending a Request Using Rust
So let’s start the scraper by defining the starting URL:
fn main() {
let start_url = "https://scrapeme.live/shop/";
}You can now use the Reqwest library to send requests to the URL:
fn main() {
let start_url = "https://scrapeme.live/shop/";
let resp = reqwest::blocking::get(String::from(start_url)).expect("Request failed to start url");
}As already mentioned, when web scraping with Rust, the blocking API is used to get the data. But instead, you can use the non-blocking code if you want to.
Once you have the response for the page, extract the HTML from it. To do that, you can use the text method of the response object as follows:
fn main() {
let start_url = "https://scrapeme.live/shop/";
let resp = reqwest::blocking::get(String::from(start_url)).expect("Request failed to start url");
let body = resp.text().expect("Failed to get the response");
}You have HTML in the body variable. You can try printing the response using the mentioned line and see if you are getting the correct response:
println!("{}", body)Before moving to parsing, you should make the code to get the response into a function since you need to use it multiple times. The function and updated main function are:
/// Returns the HTML response from sending request to the input URL
fn get_response(url: &String) -> String {
let resp = reqwest::blocking::get(url).expect("Request failed to start url");
let body = resp.text().expect("Failed to get the response");
body
}fn main() {
let start_url = "https://scrapeme.live/shop/";
let response = get_response(&String::from(start_url));
}Parsing the HTML Content and Extracting Data Using Scraper Crate
The next step in web scraping using Rust is parsing the response HTML with the scraper and extracting Pokemon URLs. To parse the document use HTML struct from Scraper crate. Add the lines to the top of the main.rs:
use scraper::{ElementRef, Html, Selector};The above line imports ElementRef, HTML, and Selector structs from the Scraper crate into the code. Now you can parse the document:
fn main() {
let start_url = "https://scrapeme.live/shop/";
let response = get_response(&String::from(start_url));
let document = Html::parse_document(&response);
}Next, create a Selector to extract the URL. To find the Selector for each of the Pokemon, you can use the inspector/elements tab. You can use the Selector to extract data from the parsed document.
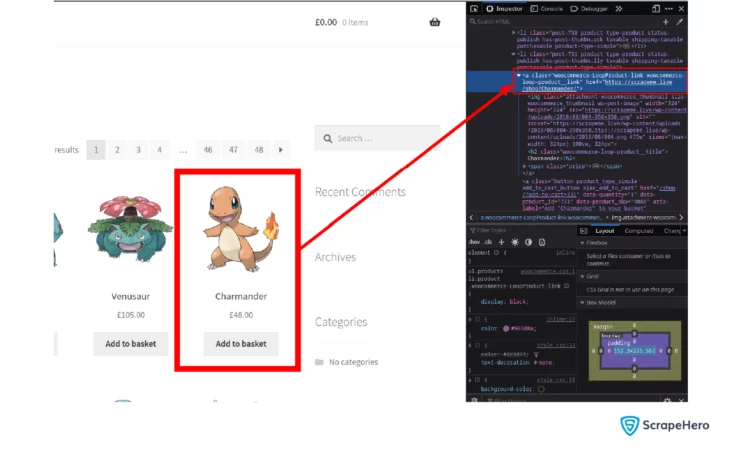
For this, use the Selector struct from the Scraper crate:
let url_selector = Selector::parse("li.product a.woocommerce-loop-product__link").unwrap();Once you have the Selector, use it to extract URLs from the document.
let url_elem = document.select(&url_selector).next().unwrap();You have the anchor element in the url_elem variable. Extract the “href” attribute from it.
let url = String::from(url_elem.attr("href").unwrap());So you have the URL for one Pokemon. Since there are many Pokemon on a single page, you can make the code into a function and make it return the list of Pokemon URLs. Create two functions for this:
/// Gets the `href` attribute of an element and returns the string
fn get_url_from_element(elem: ElementRef) -> String {
String::from(elem.attr("href").unwrap())
}To extract URL attributes from an anchor tag:
/// Extract and returns pokemon URLs from a listing page
fn get_pokemon_urls(listing_page: Html) -> Vec {
let url_selector = Selector::parse("li.product a.woocommerce-loop-product__link").unwrap();
let pokemon_urls: Vec = listing_page
.select(&url_selector)
.into_iter()
.map(|elem| get_url_from_element(elem))
.collect();
pokemon_urls
}So by calling get_pokemon_urls while passing a listing page document, you will get all the Pokemon URLs as a list. Let’s add this to the main function:
fn main() {
let start_url = "https://scrapeme.live/shop/";
let response = get_response(&String::from(start_url));
let document = Html::parse_document(&response);
for url in get_pokemon_urls(document) {
}
}A for-in loop is used here since you need to send requests to each of the URLs. You can follow the same process for downloading the response for each Pokemon page and parsing it into HTML documents:
for url in get_pokemon_urls(document) {
let pokemon_resp = get_response(&url);
let pokemon_document = Html::parse_document(&pokemon_resp);
}Extract the required data points from the parsed Pokemon page.
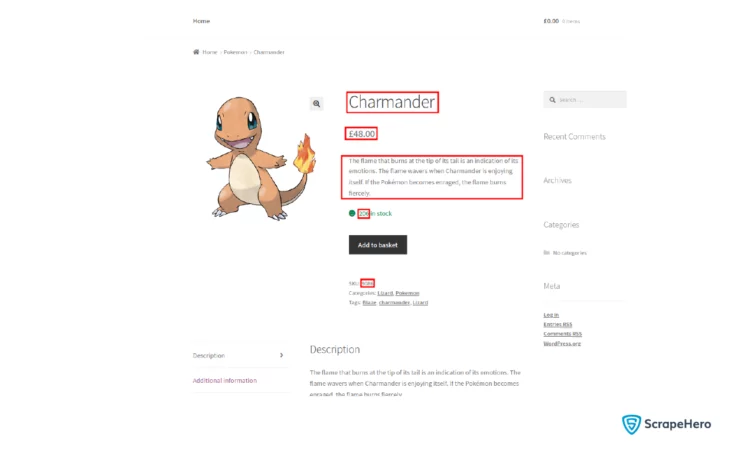
Add three more helper functions before writing code to extract data:
To extract text from HTML tags:
/// Gets all the texts inside an HTML element
fn get_text_from_element(elem: ElementRef) -> String {
let mut output_string = String::new();
for text in elem.text() {
output_string = output_string.add(text);
}
output_string
}Add the line to the top of the file to support String concatenation:
use std::ops::Add;To extract one matching element using the CSS Selector:
/// Runs css selector using the given selector query on the document and returns one matching element
fn css_select_one(selector: String, document: &Html) -> ElementRef<'_> {
let selector = Selector::parse(&selector).unwrap();
let element: ElementRef<'_> = document.select(&selector).next().unwrap();
element
}To remove unnecessary whitespace from text:
/// Removes any unnecessary whitespaces from the string and returns the cleaned string
fn clean_text(text: String) -> String {
let x: Vec<&str> = text.split_whitespace().collect();
x.join(" ")
}You can write a css_select_many function to extract multiple elements to use in get_pokemon_urls.
By using these three functions, you can create an extract_pokemon_data function to extract the required data points and return them as an array:
/// Extract and returns a list of required data points from a product page
fn extract_pokemon_data(pokemon_page: Html) -> Vec {
let title_elem = css_select_one(String::from("h1"), &pokemon_page);
let title = get_text_from_element(title_elem);
let price_elem = css_select_one(String::from("p.price span"), &pokemon_page);
let price = get_text_from_element(price_elem);
let description_elem = css_select_one(
String::from("div[class*=\"short-description\"]"),
&pokemon_page,
);
let description = clean_text(get_text_from_element(description_elem));
let sku_elem = css_select_one(String::from("span.sku"), &pokemon_page);
let sku = get_text_from_element(sku_elem);
let stock_count_elem = css_select_one(String::from("p.stock"), &pokemon_page);
let stock_count_raw = get_text_from_element(stock_count_elem);
let stock_count = String::from(stock_count_raw.split_whitespace().collect::<Vec<_>>()[0]);
vec![title, price, description, stock_count, sku]
}Note: A vector is used here to return the extracted data. You may also choose to use a struct or a mapping for the same purpose.
Add the above function to the for loop.
for url in get_pokemon_urls(document) {
let pokemon_resp = get_response(&url);
let pokemon_document = Html::parse_document(&pokemon_resp);
let pokemon = extract_pokemon_data(pokemon_document);
}It is not recommended to write every Pokemon data to the file. Instead, you can temporarily store it in memory using a vector or an array. Let’s create a vector because it doesn’t require an initial size and can grow dynamically.
let mut pokemons: Vec<Vec> = Vec::new();
for url in get_pokemon_urls(document) {
let pokemon_resp = get_response(&url);
let pokemon_document = Html::parse_document(&pokemon_resp);
let pokemon = extract_pokemon_data(pokemon_document);
pokemons.push(pokemon);
println!("Processed {}", url);
}Also, add a nice log to indicate that the URL has been processed.
Saving the Data Into a CSV File
Now that you have collected all the Pokemon, write them into a CSV file. You can write a generic CSV writer function using CSV crate as follows:
Add the CSV writer struct to the main file by including these lines at the top of main.rs:
use csv::Writer;Create a generic CSV writer function as shown:
fn write_to_csv(filename: &str, field_names: Vec<&str>, records: Vec<Vec>) {
let mut writer = Writer::from_path(filename).unwrap();
writer.write_record(field_names).unwrap();
records
.into_iter()
.map(|x| writer.write_record(x))
.for_each(drop);
}It accepts a filename, a vector of field names, and a vector of Pokemon data. Add the mentioned line to the main function to save the data to a “pokemons.csv” file:
let field_names = vec!["title", "price", "sku", "stock_count", "description"];
write_to_csv("pokemons.csv", field_names, pokemons);That’s it; you have successfully created a scraper in Rust.
The complete main function is:
fn main() {
let start_url = "https://scrapeme.live/shop/";
let response = get_response(&String::from(start_url));
let document = Html::parse_document(&response);
let mut pokemons: Vec<Vec> = Vec::new();
for url in get_pokemon_urls(document) {
let pokemon_resp = get_response(&url);
let pokemon_document = Html::parse_document(&pokemon_resp);
let pokemon = extract_pokemon_data(pokemon_document);
pokemons.push(pokemon);
println!("Processed {}", url);
}
let field_names = vec!["title", "price", "sku", "stock_count", "description"];
write_to_csv("pokemons.csv", field_names, pokemons);
}To improve your scraper, you can
- Add pagination logic so that you can extract all the Pokemon.
- Add concurrency by using the non-blocking feature of Reqwest, and experiment with concurrency in Rust.
Access the complete code for Web Scraping Using Rust on GitHub
Wrapping Up
Rust can be considered for web scraping due to its high performance and the ability to manage low-level processes. It allows you to write efficient scrapers and increase the speed of scraping. But on the other hand, there are a few drawbacks when it comes to web scraping using Rust.
Libraries and tools specifically tailored for scraping are limited in the case of Rust when compared to web scraping with Python. Moreover, the dynamic content generated through JavaScript execution by modern websites poses another hurdle to web scraping. Also, dealing with scraping prevention methods like CAPTCHAs can be tricky during web scraping with Rust.
Even if you overcome all these hurdles, you may still need a web scraping service provider like ScrapeHero to deal with your scraping needs. You can make use of ScrapeHero Cloud, which is a hassle-free,no-code, and affordable means of scraping popular websites. But if you need enterprise-grade scraping, then you can go for ScrapeHero web scraping services, which are bespoke, custom, and more advanced.
Frequently Asked Questions
-
Is Rust good for scraping?
Yes. Rust is a good choice if you need the performance benefits it offers and are comfortable with its learning curve and ecosystem.
-
What is the Rust equivalent of BeautifulSoup?
In Rust, the equivalent functionality to Python’s BeautifulSoup is provided by the Scraper crate, which is an HTML parsing and querying library.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data


