

Almost all programming languages can be used to create a web scraper. Then why should you choose R for web scraping? Is it just because of its rich libraries? Well, that can be considered one of the reasons. R is a popular choice also due to its features like ease of use, dynamic typing, etc.
This article will help you create a scraper in R using the rvest (or harvest) library. rvest is inspired by libraries like BeautifulSoup. It scrapes information from multiple web pages and reads it into R. Here you also learn the method to gather data using the XPath.
What is the Use of rvest When Web Scraping in R?
rvest is a popular library used for web scraping in R due to its user-friendly interface and integration with Tidyverse. It is tailored for parsing HTML and XML content, which helps it easily navigate the structure of a webpage.
rvest simplifies extracting text and attributes from HTML nodes, which is crucial for web scraping. Moreover, its syntax is readable and simple, and it is supported by a strong community.
Installation
To install R, run the following commands in the terminal.
sudo apt update && sudo apt upgrade
sudo apt install r-base
To check the version, run the command
r --versionInstall Required Libraries
You should now install the following libraries:
- httr
- rvest
- parallel
To install the libraries, you must launch the R console and run the following command.
install.packages("httr")Note: To launch the R console, go to the terminal and type R or R.exe (for Windows OS).
The above code installs the package httr.
Similarly, install the packages rvest and parallel.
install.packages("rvest")
install.packages("parallel")Create Your R Scraper
You can now create your scraper using R. The workflow of the scraper is mentioned below:
- Go to the website https://scrapeme.live/shop
- Navigate through the first 5 listing pages and collect all product URLs
- Visit each product page and collect the following data
- Name
- Description
- Price
- tock
- Image URL
- Product URL
- Save the collected data to a CSV file
Import Required Libraries
First, you need to import the mentioned libraries.
library('httr')
library('rvest')
library('parallel')Send Request to the Website
The httr library is used to collect data from the websites. httr allows the R program to send HTTP requests. It also helps you handle the responses received from the website.
Now send a request to https://scrapeme.live/shop
headers <- c(
"User-Agent" = "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36",
"Accept-Language" = "en-US,en;q=0.5"
)
url <- 'https://scrapeme.live/shop/'
response <- httr::GET(url, add_headers(headers))The above code sends an HTTP request to the website and stores the response in the variable response.
Now, you need to validate the response
verify_response <- function(response){
if (status_code(response) == 200){
return(TRUE)
} else {
return(FALSE)
}
}Here you can verify the website response using the status code; if the status code is 200, the response is valid; otherwise, it is invalid. If you get an invalid response, you can add retries. This may solve the invalid response issue.
max_retry <- 3 while (max_retry >= 1){
response <- httr::GET(url, add_headers(headers))
if (verify_response(response)) {
return(response)
} else {
max_retry <- max_retry - 1
}
} Collect Required Data
Now you have the response from the listing page. Collect the product URLs. To parse the HTML response, you can use the rvest library.
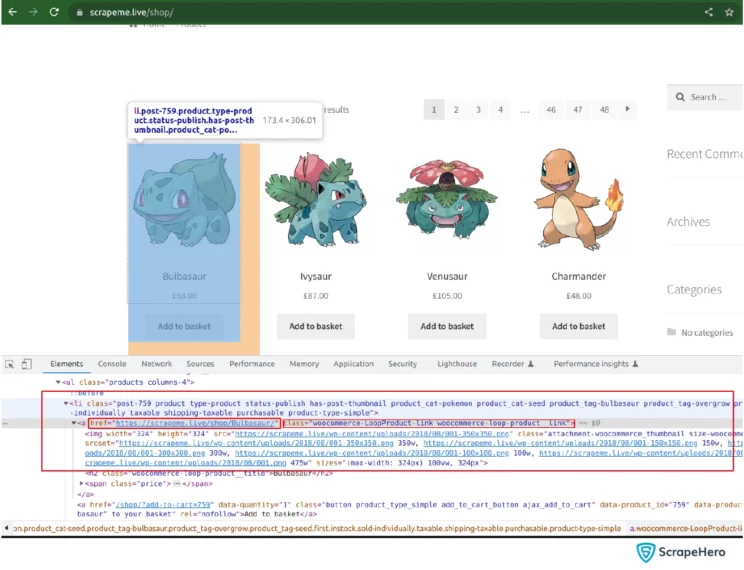
As you can see in the above screenshot, the URL to the product page is in the node ‘a’ having the class name woocommerce-LoopProduct-link woocommerce-loop-product link. The node “a” comes under another node ‘li,’ so its XPATH can be written as
//li/a[contains(@<strong>class</strong>, "<strong>product__link</strong>")]The URL to the product is in the “href” attribute of that node. So you access the attribute value using rvest as below:
product_urls <- html_nodes
( parser, xpath='//li/a[contains(@class, "product__link")]') %>% html_attr(
'href')
Similarly, you can get the next page URL from the next button in HTML.
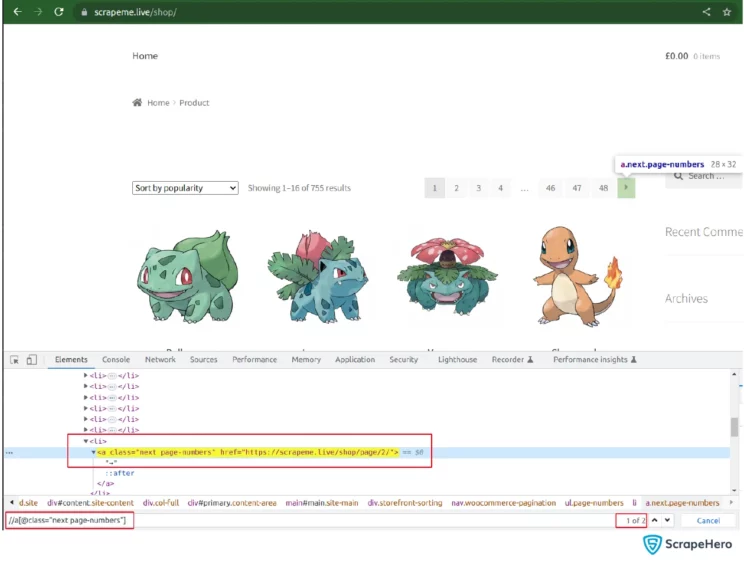
Since there are two results for the same xpath and you want to select the first result to get the next page URL from the ‘a’ node, you should give the xpath inside a bracket () and index it. So the XPATH //a[@class=”next page-numbers“] becomes (//a[@class=”next page-numbers“])[1].
Now use the help of html_attr from the rvest library to collect the data.
next_page_url <- html_nodes(parser, xpath='(//a[@class="next page-numbers"])[1]') %>% html_attr('href')Save all the product URLs that you have now into a list. Paginate through the listing page and add the product URLs to the same list. Once all the paginations are done, you send the request to the product URLs using the httr library.
Process the URLs Parallelly
Now that you have collected all product URLs, you can send the request to the product pages.
Since there are many product URLs, and each request takes a few seconds to collect the response through the network, the code block will wait for the response to execute the remaining code, leading to a much greater execution time.
To overcome this, you can use the parallel library. It has a function called mclapply(), which takes a vector as its first argument; the second argument is a function. It also accepts the number of cores that need to be used.
Assign the number of cores to be used to the mc.cores params. Here, the scrape_page function will be called for each URL in the urls vector. mc.cores defines the number of cores that need to be used for running the function block.
If mc.cores is not defined, it will run with the default number of cores available. If the assigned value of mc.cores is greater than the available number of cores, then it does not affect the processing.
results <- mclapply(product_urls, get_product_data, mc.cores = 8)Now collect the required data points’ Name, Description, Price, Stock, Image URL.
Name
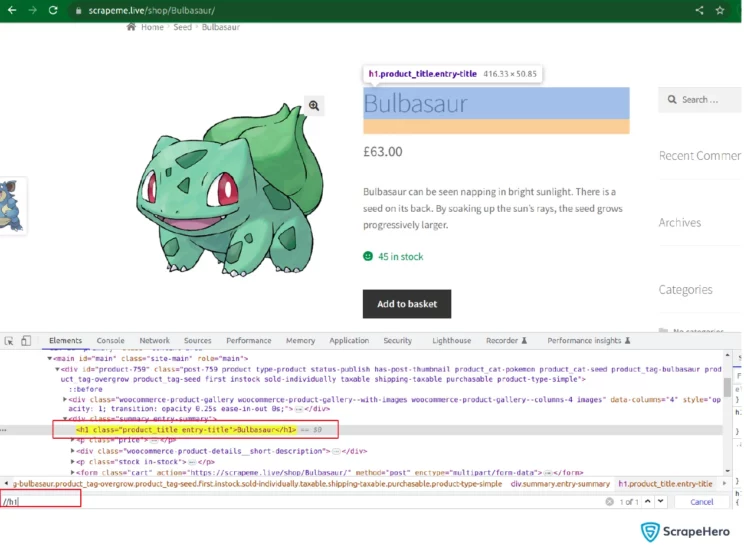
It is clear from the screenshot that the product’s name is inside node h1. Since no other h1 nodes are on the product page, you can simply call the XPATH //h1 to select that particular node.
Since the text is inside the node, you can use:
title <- html_nodes(parser, xpath='//h1') %>% html_text2()There are two methods within the rvest library to extract text. Those are html_text2() and html_text(). The html_text2() cleans and strips any unwanted white spaces between the selected string, whereas the html_text() returns the text as it is available on the website.
Description
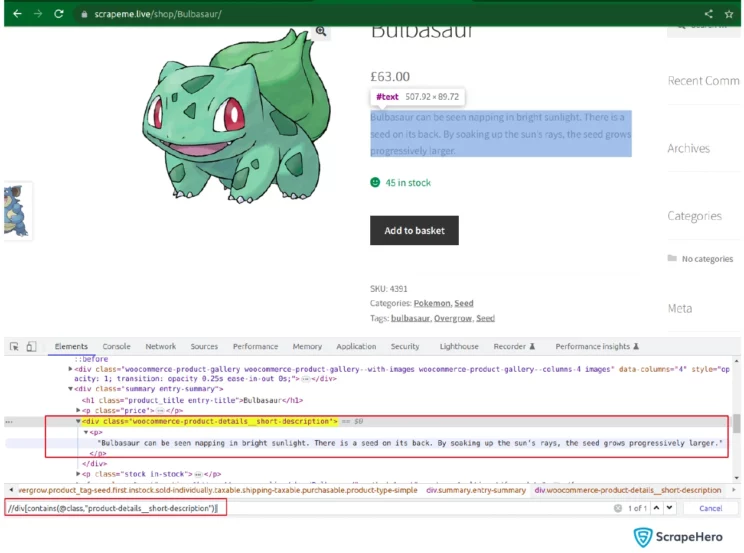
As you can see, the product description is inside the node p, which is inside div having class name substring ‘product-details__short-description.’ You can collect the text inside it as follows:
description <- html_nodes(parser, xpath='//div[contains(@class,"product-details__short-description")]') %>% html_text2()Stock
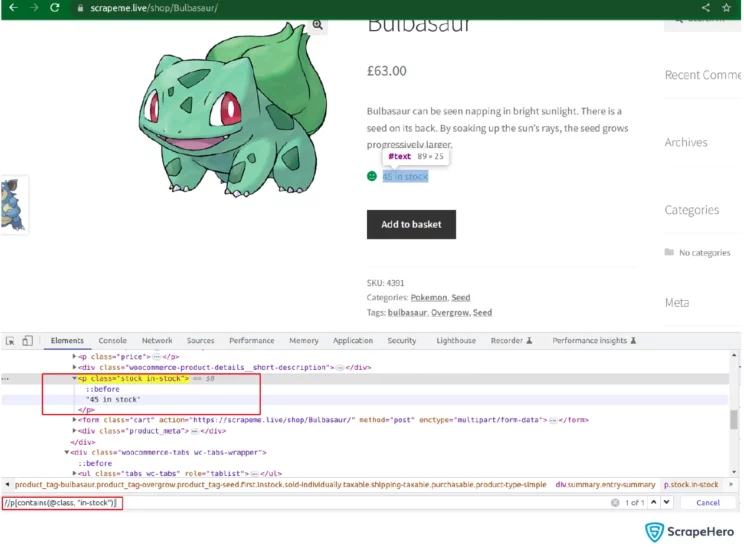
Since stock is directly present inside the node p, whose class contains the string ‘in-stock’ you can use the following code to collect data from it.
stock <- html_nodes(parser, xpath='//p[contains(@class, "in-stock")]') %>% html_text2()Price
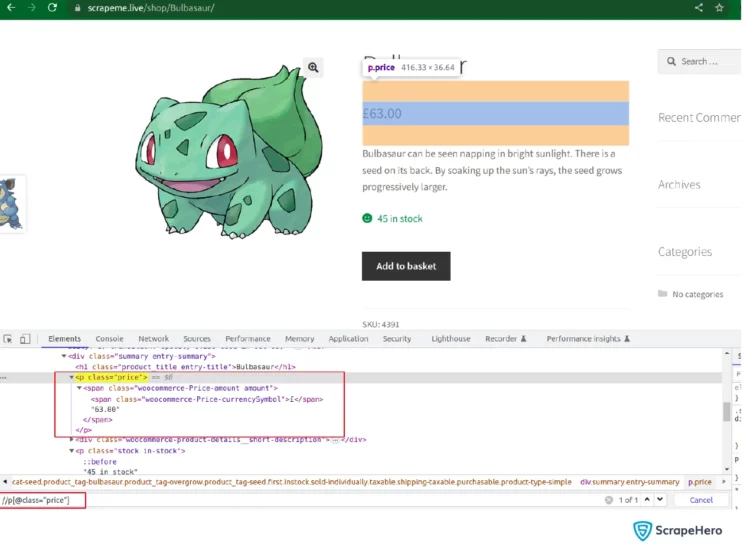
You can get the product’s price using the following code since the price is directly available in the node p having class price.
price <- html_nodes(parser, xpath='//p[@class="price"]') %>% html_text2()Image URL
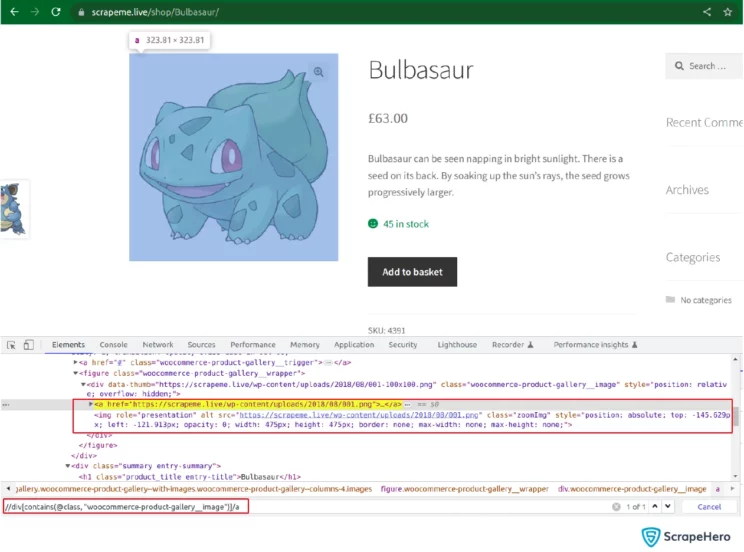
You can get the image URL from the attribute href of the node ‘a’ which is selected as shown in the screenshot above.
image_url <- html_nodes(parser, xpath='//div[contains(@class, "woocommerce-product-gallery__image")]/a') %>% html_attr('href')Now return the collected data for each product as a new data frame and append it to a common list. To create the data frame, use:
image_url <- html_nodes(parser, xpath='//div[contains(@class, "woocommerce-product-gallery__image")]/a') %>% html_attr('href')To combine each data frame into a single one use:
single_data_frame <- do.call(rbind, data_frame_list)To save the collected data to CSV format, you can use:
write.csv(single_data_frame, file = "scrapeme_live_R_data.csv", row.names = FALSE)Here’s the complete code for Web scraping in R
How to Send GET Requests Using Cookies and Headers
Now, let’s see how to send the requests using headers and cookies. First, call the library httr and initialize the required parameters.
library('httr')
# URL to which we send the request
url <- "https://httpbin.org/anything"
# Set the required headers
headers <- c(
"User-Agent" = "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36",
"Accept-Language" = "en-US,en;q=0.5"
)
# Set the cookies if any, else no need to use set_cookies()
cookies <- c(
"cookie_name1" = "cookie_value1",
"cookie_name2" = "cookie_value2"
)After the initialization, send the request and save the response object to a variable.
# Send the GET request from httr library
response <- GET(url, add_headers(headers), set_cookies(cookies))
# Print the response to see if it is a valid response
print(response)In web scraping, the usage of headers is critical to avoid getting blocked.
Sending POST Requests in R
Now let’s see how to send a POST request using httr.
library(httr)
# Set the URL
url <- "https://httpbin.org/anything"Initialize the POST request payload as below.
# Set the request body (payload)
payload <- list(
key1 = "value1",
key2 = "value2"
)
# Set the headers
headers <- c(
"Content-Type" = "application/json",
"Authorization" = "Bearer YOUR_TOKEN",
"User-Agent" = "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"
)Here you have to mention the encode type as “json” to convert the payload to JSON before sending the request.
# Send the POST request
response <- POST(url, body=payload, encode ="json", add_headers(headers))
# Print the response to see if it is a valid response
print(response)Wrapping Up
Even though Python is regarded as a popular choice for web scraping, you can still try out web scraping in R using libraries like rvest. R can easily manage, manipulate, and display data, which are its major advantages.
Creating a scraper in R can meet your small-scale web scraping needs. But for enterprise-grade requirements, you may need a full-service option from a reputed data provider like ScrapeHero. Let’s connect if your needs range from data extraction to alternative data.
Frequently Asked Questions
-
What is the best web scraping tool in R?
rvest is a widely used library for web scraping in R. But you can also choose RSelenium, httr and parallel.
-
How can I perform advanced web scraping using R?
You can carry out Advanced web scraping in R using various ways, for instance with RSelenium, especially when websites require login credentials or maintain user sessions.
-
How can you do Dynamic web scraping in R?
Using RSelenium you can do Dynamic web scraping in R. Note that it controls a real browser, so it can be slower and require more resources.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data


