We obtained the details of 19,493 properties in California with our Zillow scraper and analyzed them to obtain interesting insights.
Web scraping real estate data allows you to track listings available for sellers and agents. This data allows you to adjust prices on your website and even create your own database. In this tutorial, you will read about scraping Zillow data.
Here, you will perform web scraping using Python lxml and requests. The requests library gets the raw data from Zillow, and lxml parses it.
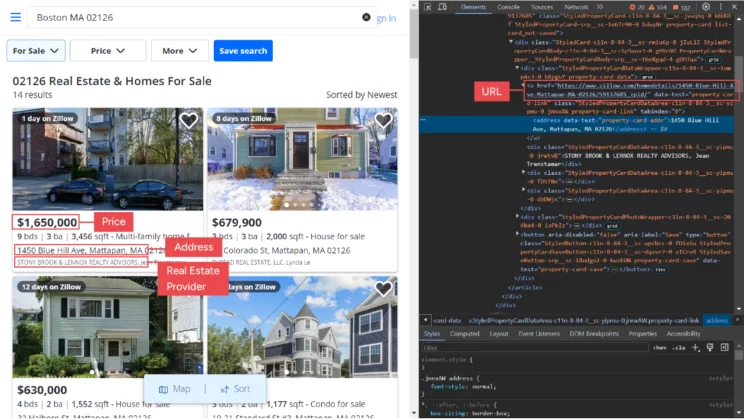
Information Scraped From Zillow
You can scrape Zillow data with this tutorial’s code that extracts the following data points:
- Address
- Price
- Real Estate Provider
- URL
Install Packages for Scraping Zillow Data
Both requests and lxml are external Python libraries. That means you must use pip to install them.
pip install lxml requestsYou must also install the unicodecsv library for writing CSV files.
pip install unicodecsv
How to Scrape Zillow: The Code
Here is the Python code for web scraping Zillow leads. First, you must import the necessary libraries and modules.
from lxml import html
import requests
import unicodecsv as csv
import argparse
import json
Extracted data may have unnecessary white spaces. So define a function clean() that removes any such spaces.
def clean(text):
if text
return ' '.join(' '.join(text).split())
return NoneTo keep things organized, keep headers in a separate function. You can call this function to get the headers. This approach also makes it easy when updating headers, as you can avoid touching the main code.
def get_headers():
# Creating headers.
headers = {'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,'
'*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-language': 'en-GB;q=0.9,en-US;q=0.8,en;q=0.7',
'dpr': '1',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'}
return headersThe code can get the results sorted either by cheapest or by newest. And it can deliver unsorted listings if you didn’t specify a sort option.
All these scenarios demand a separate request URL while scraping Zillow data using Python lxml. Therefore, define a create_url function that returns the appropriate URL based on the filter.
def create_url(zipcode, filter):
# Creating Zillow URL based on the filter.
if filter == "newest":
url = "https://www.zillow.com/homes/for_sale/{0}/0_singlestory/days_sort".format(zipcode)
elif filter == "cheapest":
url = "https://www.zillow.com/homes/for_sale/{0}/0_singlestory/pricea_sort/".format(zipcode)
else:
url = "https://www.zillow.com/homes/for_sale/{0}_rb/?fromHomePage=true&shouldFireSellPageImplicitClaimGA=false&fromHomePageTab=buy".format(zipcode)
print(url)
return urlYou might need to check the response text to debug any error. Thus, define a function save_to_file() that writes the response to a file.
def save_to_file(response):
# saving response to `response.html`
with open("response.html", 'w', encoding="utf-8") as fp:
fp.write(response.text)Define a function write_data_to_csv to write the extracted data to a CSV file.
def write_data_to_csv(data):
# saving scraped data to csv.
with open("properties-%s.csv" % (zipcode), 'wb') as csvfile:
fieldnames = ['address', 'price','real estate provider', 'url']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for row in data:
writer.writerow(row)To get the response, define a get_response() function that will send the HTTP request to Zillow.com. Here, the function also calls save_to_file() to save the response to a file.
def get_response(url):
# Getting response from zillow.com.
for i in range(5):
response = requests.get(url, headers=get_headers())
print("status code received:", response.status_code)
if response.status_code != 200:
# saving response to file for debugging purpose.
save_to_file(response)
continue
else:
save_to_file(response)
return response
return NoneDefine a parse() function that integrates
- create_url(),
- get_response(),
- clean(),
and returns the list of Zillow properties.
The parse() function uses lxml to parse the response text. It then uses XPath to locate HTML elements from the response and extract the corresponding data.
def parse(zipcode, filter=None):
url = create_url(zipcode, filter)
response = get_response(url)
if not response:
print("Failed to fetch the page, please check `response.html` to see the response received from zillow.com.")
return None
parser = html.fromstring(response.text)
search_results = parser.xpath("//div[@id='grid-search-results']//article")
print(search_results)
print("parsing from html page")
properties_list = []
for properties in search_results:
raw_address = properties.xpath(".//address//text()")
raw_price = properties.xpath(".//span[@class='PropertyCardWrapper__StyledPriceLine-srp__sc-16e8gqd-1 iMKTKr']//text()")
raw_broker_name = properties.xpath(".//div[@class='StyledPropertyCardDataArea-c11n-8-84-3__sc-yipmu-0 jretvB']//text()")
url = properties.xpath(".//a[@class='StyledPropertyCardDataArea-c11n-8-84-3__sc-yipmu-0 jnnxAW property-card-link']/@href")
raw_title = properties.xpath(".//h4//text()")
address = clean(raw_address)
price = clean(raw_price)
#info = clean(raw_info).replace(u"\xb7", ',')
broker = clean(raw_broker_name)
title = clean(raw_title)
property_url = "https://www.zillow.com" + url[0] if url else None
properties = {'address': address,
'price': price,
'real estate provider': broker,
'url': property_url,
}
print(properties)
properties_list.append(properties)
return properties_listFinally, call the parse() function and use write_data_to_csv() to write the extracted property listings to a CSV file.
if __name__ == "__main__":
# Reading arguments
argparser = argparse.ArgumentParser(formatter_class=argparse.RawTextHelpFormatter)
argparser.add_argument('zipcode', help='')
sortorder_help = """
available sort orders are :
newest : Latest property details,
cheapest : Properties with cheapest price
"""
argparser.add_argument('sort', nargs='?', help=sortorder_help, default='Homes For You')
args = argparser.parse_args()
zipcode = args.zipcode
sort = args.sort
print ("Fetching data for %s" % (zipcode))
scraped_data = parse(zipcode, sort)
if scraped_data:
print ("Writing data to output file")
write_data_to_csv(scraped_data)
The code also uses the argparse module to provide command-line functionality to the script. That is how you pass the ZIP code and the sorting option to the script.
Here is a flowchart showing the order of execution of the defined functions for web scraping Zillow with Python.

How to Use the Script
The argparse module made it possible to use arguments while executing the script via terminal. Save the script as zillow.py and use the terminal commands to execute the script.
usage: zillow.py [-h] zipcode sort
positional arguments:
zipcode
sort
available sort orders are :
newest : Latest property details
cheapest : Properties with cheapest price
optional arguments:
-h, --help show this help message and exit
You must execute the script using Python with ZIP code as an argument. There is also an optional sort argument. The sort argument has the options ‘newest’ and ‘cheapest’ listings. For example,
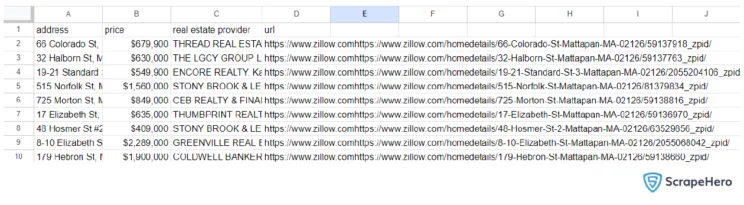
python3 zillow.py 02126 newestThe above code gets the listings in Boston, Massachusetts sorted by newest. You will get the following CSV file.
Possible Errors While Scraping Zillow data
You may encounter the following errors while Zillow scraping using Python lxml:
ModuleNotFoundError
This error says that you have not installed the corresponding package. You can use Python’s pip package manager to install the package as mentioned above. For example,
ModuleNotFoundError: No module named ‘lxml’
This error means you must install lxml.
AttributeError
This error occurs because the extracted data didn’t match the structure for which you wrote the program. For example,
AttributeError: “NoneType’ object has no attribute ‘replace’
The error tells you that the program failed to extract anything. Most likely, the structure of the website changed. You must find the new XPaths and update the program.
Status Code: 403
Here, you must analyze the response text to find out the source of the error.
Sometimes, you can access the website using a browser. However, the response text may show “access has been denied to this page”. This means that Zillow has prevented you from web scraping.
In this case, you must try different headers or add some more to pose as a legitimate user.
Conclusion
You saw how to scrape data from Zillow using Python libraries. The approach works by making an HTTP request using the request library and parsing the response using lxml. Then you can use XPaths to locate the required data from the parsed text.
However, the process to get XPaths is tedious. And the website structure may change frequently, making it necessary to repeat the process. For a free, no-code approach, you can use ScrapeHero Zillow Scraper from ScrapeHero Cloud.
The code is also not appropriate for large-scale web scraping. Moreover, scraping more listings from Zillow may need more resources. It also requires advanced technical knowledge. Therefore, it is better to look for managed scraping services like ScrapeHero.
ScrapeHero is a fully managed web scraping service provider. Our services include custom enterprise-grade web crawling and scraping solutions. We also provide high-quality retail store location datasets.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data