

Blogging is a vital marketing tool for increasing a business’s lead conversion rate. It can boost website traffic, enhance SEO and SERP rankings, and build backlinks.
This article gives you an overview of web scraping blog posts using the extracted data for strategic business advantages.
Scraping Blog Data Using Python
Follow the steps mentioned to scrape blog posts and display the extracted content in a tabular form using Python.
Step 1: Install the Libraries – Requests, BeautifulSoup, and Pandas
pip install requests beautifulsoup4 pandasStep 2: Import all the libraries given
import requests
from bs4 import BeautifulSoup
import pandas as pd
- Requests – To make HTTP requests to fetch the web page content
- BeautifulSoup – To parse the HTML content and extract data
- Pandas – To store and manipulate the data in a tabular format
Step 3: Define a function to scrape blog articles from a given URL
def scrape_blog_articles(url):
# Send a request to the website
response = requests.get(url)
# Check if the request was successful
if response.status_code != 200:
print(f"Failed to retrieve the page. Status code: {response.status_code}")
return []
# Parse the HTML content
soup = BeautifulSoup(response.content, 'html.parser')
# Find all articles (this example assumes articles are in <article> tags)
articles = soup.find_all('article')
# List to store article data
article_list = []
# Loop through all found articles and extract relevant information
for article in articles:
title = article.find('h2').text if article.find('h2') else 'No title'
date = article.find('time').text if article.find('time') else 'No date'
summary = article.find('p').text if article.find('p') else 'No summary'
# Append the extracted information to the list
article_list.append({
'Title': title,
'Date': date,
'Summary': summary
})
return article_list
Let’s understand each section of the code in detail.
-
Fetch the Web Page
response = requests.get(url)This line of code sends GET requests to the specified URL and fetches the page’s HTML content.
-
Check the Request Status
if response.status_code != 200: print(f"Failed to retrieve the page. Status code: {response.status_code}") return []This block can check whether the request was successful (status code 200). If not, it prints an error message and returns an empty list.
-
Parse the HTML Content
soup = BeautifulSoup(response.content, 'html.parser')BeautifulSoup is used to parse the HTML content.
-
Find Articles
articles = soup.find_all('article')You use this specific code to find all the <article> tags in the HTML content. You can also adjust this selector based on the actual structure of the website that you are scraping.
-
Extract Data
for article in articles: title = article.find('h2').text if article.find('h2') else 'No title' date = article.find('time').text if article.find('time') else 'No date' summary = article.find('p').text if article.find('p') else 'No summary'This loop reads each article, extracting the title, date, and summary. The tags (‘h2’, ‘time,’ ‘p’) are adjusted based on the HTML structure.
-
Store Data
article_list.append({ 'Title': title, 'Date': date, 'Summary': summary })This line is used to append the extracted data to the article_list.
Step 4: Use the function given for blog posts scraping from a given URL
url = 'https://example-blog-website.com'
articles = scrape_blog_articles(url)
You can replace ‘https://example-blog-website.com’ with the actual URL of the blog you need to scrape.
Step 5: Convert the list of articles to a DataFrame and display the data in a table
# Create a DataFrame from the list of articles
df = pd.DataFrame(articles)
# Display the DataFrame
print(df)
Complete Code
Here’s the complete code for the scraper created for web scraping blog posts
import requests
from bs4 import BeautifulSoup
import pandas as pd
def scrape_blog_articles(url):
# Send a request to the website
response = requests.get(url)
# Check if the request was successful
if response.status_code != 200:
print(f"Failed to retrieve the page. Status code: {response.status_code}")
return []
# Parse the HTML content
soup = BeautifulSoup(response.content, 'html.parser')
# Find all articles (this example assumes articles are in <article> tags)
articles = soup.find_all('article')
# List to store article data
article_list = []
# Loop through all found articles and extract relevant information
for article in articles:
title = article.find('h2').text if article.find('h2') else 'No title'
date = article.find('time').text if article.find('time') else 'No date'
summary = article.find('p').text if article.find('p') else 'No summary'
# Append the extracted information to the list
article_list.append({
'Title': title,
'Date': date,
'Summary': summary
})
return article_list
# Example usage
url = 'https://example-blog-website.com'
articles = scrape_blog_articles(url)
# Create a DataFrame from the list of articles
df = pd.DataFrame(articles)
# Display the DataFrame
print(df)
What Are the Benefits of Web Scraping Blog Posts?
Web scraping blog posts give businesses a comprehensive view of market trends and industry insights. Listed are some benefits of blog data scraping:
- Competitive Analysis
- Market Trend Awareness
- Content Optimization
- Brand Monitoring
- Social Media Monitoring
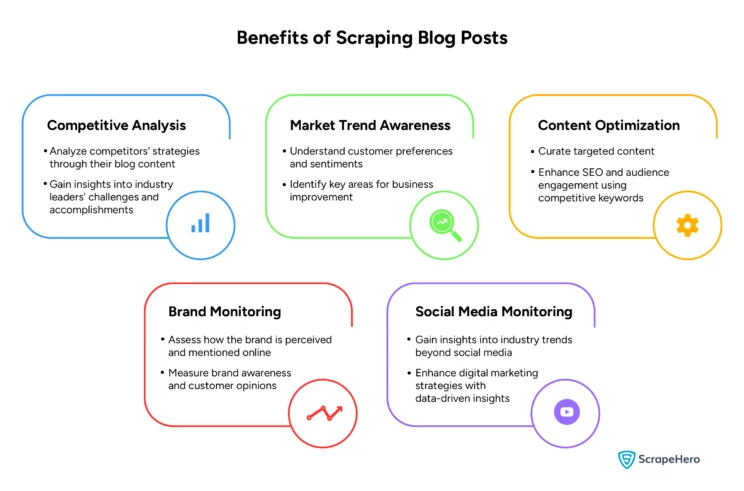
1. Competitive Analysis
By web scraping blog posts, you can systematically gather competitors’ content strategies and adopt best practices to stay competitive.
These blog posts gather information such as topics, the frequency of posts, engagement levels, and the type of content that resonates with audiences.
Scraping blog data can also provide insights into the challenges and accomplishments of industry leaders, identifying gaps in your content strategy.
2. Market Trend Awareness
It is crucial for businesses to keep updated on evolving market trends. Blogs help in detecting new trends, highlighting shifting consumer sentiments and industry changes.
You can adjust your products, services, and marketing strategies accordingly by analyzing the data extracted from blogs to meet market demands.
You can also identify potential business improvement and innovation areas by scraping and analyzing blog content.
Want to know how you can do sentiment analysis using web scraping? Find out here!
3. Content Optimization
Scraping blog data can help businesses identify the type of content that attracts and engages readers.
By analyzing keywords, topics, and the structure of successful posts, you can optimize your content to improve SEO rankings.
Creating strategic content can lead to higher web traffic and better conversion rates.
However, scaling a content pipeline based on market research can be incredibly time-consuming. While generative models can help draft articles quickly, raw outputs often lack a distinct brand voice. Savvy digital marketers bridge this gap by running initial drafts through an AI humanizer, which refines the text’s sentence structure and flow to ensure it reads as organic, engaging, and genuinely human-written before it goes live.
4. Brand Monitoring
Web scraping blog posts provide valuable insights into public perception and awareness of the brand.
When you scrape blog posts, you can monitor how often and in what context your brand is mentioned across various blogs.
By regularly monitoring such blogs, you can track changes in customer opinion, respond to feedback promptly, and manage your online reputation more effectively.
5. Social Media Monitoring
The social media-like aspects of blogging platforms, such as comments and shares, can be scraped to understand customer preferences, market competition, and relevant topics.
You can use the data from blog posts to boost your brand’s data-driven decision-making.
Web scraping blog posts can also improve your digital marketing strategies, ensuring effective marketing.
Wrapping Up
You can gather insights into market trends, competitor strategies, and consumer behavior by scraping blog data.
You can effectively refine your marketing and content strategies by creating a Python scraper for web scraping blog posts.
However, using a simple Python scraper is only sometimes practical, especially for web crawling services for enterprises.
It would help to have a reliable data partner like ScrapeHero who can understand all your needs.
You can rely on ScrapeHero web scraping services for a complete data pipeline with unmatched quality and consistency.
Frequently Asked Questions
You can use a web scraping tool to scrape articles from websites or create a Python scraper that helps you access web pages, extract relevant data, and store it for analysis.
For web scraping new articles, you can either create a Google News Python Scraper or use the ScrapeHero Cloud News API.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



