

Web scraping tools and managed web scraping services both do the same job on paper. When weighing scraping tools vs scraping services, the difference is in what happens six months in, when your operation depends on that data every single day. One scales with you. One starts costing you more than it gives.
The good news is this isn’t a hard call once you know what to look for. By the end of this guide, you’ll know exactly which option fits where your business is right now and where it’s going.

Understanding Web Scraping Tools
Web scraping tools do one thing: they pull data from websites automatically. No manual copying, no spreadsheet headaches. The tool visits a page, grabs what you need, and stores it in a format you can actually use, whether that’s a CSV, Excel file, or a database.
For e-commerce brands, that usually means tracking competitor prices, product listings, stock levels, ratings, and reviews across marketplaces. The kind of data that, if you’re getting it late or getting it wrong, is costing you real money.
On the surface, these tools look straightforward. Set up, point, extract. And for small projects or one-off research, they hold up just fine.
But here’s where it gets interesting: not all scraping tools are built the same. Some are designed for business users who’ve never written a line of code. Others need a developer to even get started. Knowing the difference matters before you commit to anything.
Here are the types of Scraping tools
1. No-Code Scraping Tools
No-code scraping tools are built for people who don’t want to touch code and shouldn’t have to.
You get a visual interface. You click on the elements you want: a product title, a price, a rating, and the tool figures out the pattern. Then it replicates that across hundreds or thousands of similar pages on its own.
It’s a genuinely useful starting point. Business users can get up and running quickly, pull product listings, do basic competitive research, and not depend on engineering teams for every little thing.
The catch is that these tools are only as reliable as the websites they’re scraping. The moment a site changes its layout or adds anti-bot protection, your scraper stops working. And it usually stops without warning.
2. Browser Extensions
Browser extensions are the quickest way to get data off a page. Install, open a website, and start extracting. No setup, no learning curve.
Teams use them for fast, focused tasks. Pulling competitor pricing before a campaign. Exporting a marketplace search page into a spreadsheet. Getting a quick snapshot of what’s out there.
They’re fine for that. But there’s a catch: they’re not built for scale. You’re scraping what’s in front of you, one page at a time. If your data needs have grown beyond quick snapshots, a browser extension will slow you down more than it helps.
3. Developer-Focused Frameworks
Developer frameworks are where scraping tools get serious.
Instead of clicking around a visual interface, your engineers write code that tells the system exactly where to go, what to look for, and how to handle it. These frameworks can navigate complex websites, manage logins, and process large volumes of data in ways no-code tools simply can’t.
The tradeoff is real, though. You need engineering resources to build them, and more resources to maintain them. Every time a website updates its structure, someone has to go in and fix the scraper. For some teams, that’s manageable. For others, it quietly becomes a full-time job.
Understanding Web Scraping Services
Web scraping tools put you in the driver’s seat. Web scraping services take the wheel entirely.
Instead of setting up the system and figuring it out yourself, you’re working with a team that handles everything. They build the infrastructure, run the scraping, clean the data, and deliver it in a format your team can actually use. You don’t manage pipelines. You don’t fix broken scrapers at midnight. You just get the data.
For e-commerce brands, that typically means competitor pricing, product listings, reviews, stock levels, and marketplace trends, across as many retailers as you need, on whatever schedule makes sense for your business.
Here’s how it usually works from start to finish.
1. Consultation
It starts with a conversation, not a setup guide.
You tell the provider what you need. Daily competitor pricing across three major marketplaces. Weekly stock availability updates. The data to power a full assortment analysis across multiple retailers. Whatever it is, they listen first.
From there, they look at the websites involved, the scale of what you’re asking for, and how to collect it reliably. The goal at this stage is to design something tailored to your business, not to hand you a generic template and wish you luck.
2. Setup
Once they understand what you need, they build it.
Custom scrapers for your target websites. An infrastructure that can handle large request volumes without choking. Proxies, scheduling, and monitoring systems. All of it is configured to keep the pipeline running consistently, even when websites push back.
This is the part that takes weeks to build yourself and minutes to hand off. Most teams don’t realize that until they’ve already spent the weeks.
3. Extraction and Cleaning
This is where the actual work happens, and it’s more involved than it looks.
Scrapers run on a schedule and pull exactly what you asked for. Prices, ratings, product descriptions, inventory levels, seller details.
But raw scraped data is messy. Product names show up in three different formats. Fields go missing. Inconsistencies creep in everywhere.
A good service doesn’t just collect the data. They clean, validate, and standardize it. So what lands in your hands is something your team can actually trust and act on, not a spreadsheet that needs another hour of cleanup before it’s usable.
4. Delivery
The last step is getting the data where it needs to go.
That might be an API your BI tools plug into directly. A dashboard that your pricing team checks every morning. Scheduled feeds into cloud storage. A direct database integration. Whatever fits how your team already works.
The point is simple: by the time the data reaches you, your job is just to use it. No pipelines to babysit. No engineers pulled off real work to fix a scraper. Just clean, structured, ready-to-use data showing up when you need it.

What Is the Difference Between Scraping Tools and Scraping Services?
Both approaches collect web data. But understanding the differences between scraping tools and services, how they operate, and what that means for your team day-to-day, is where they completely part ways.
For e-commerce brands, the decision usually comes down to three things: how much internal resource you’re willing to spend, how much data you actually need, and how badly things go when that data is wrong or missing.
Here’s where the two approaches differ.
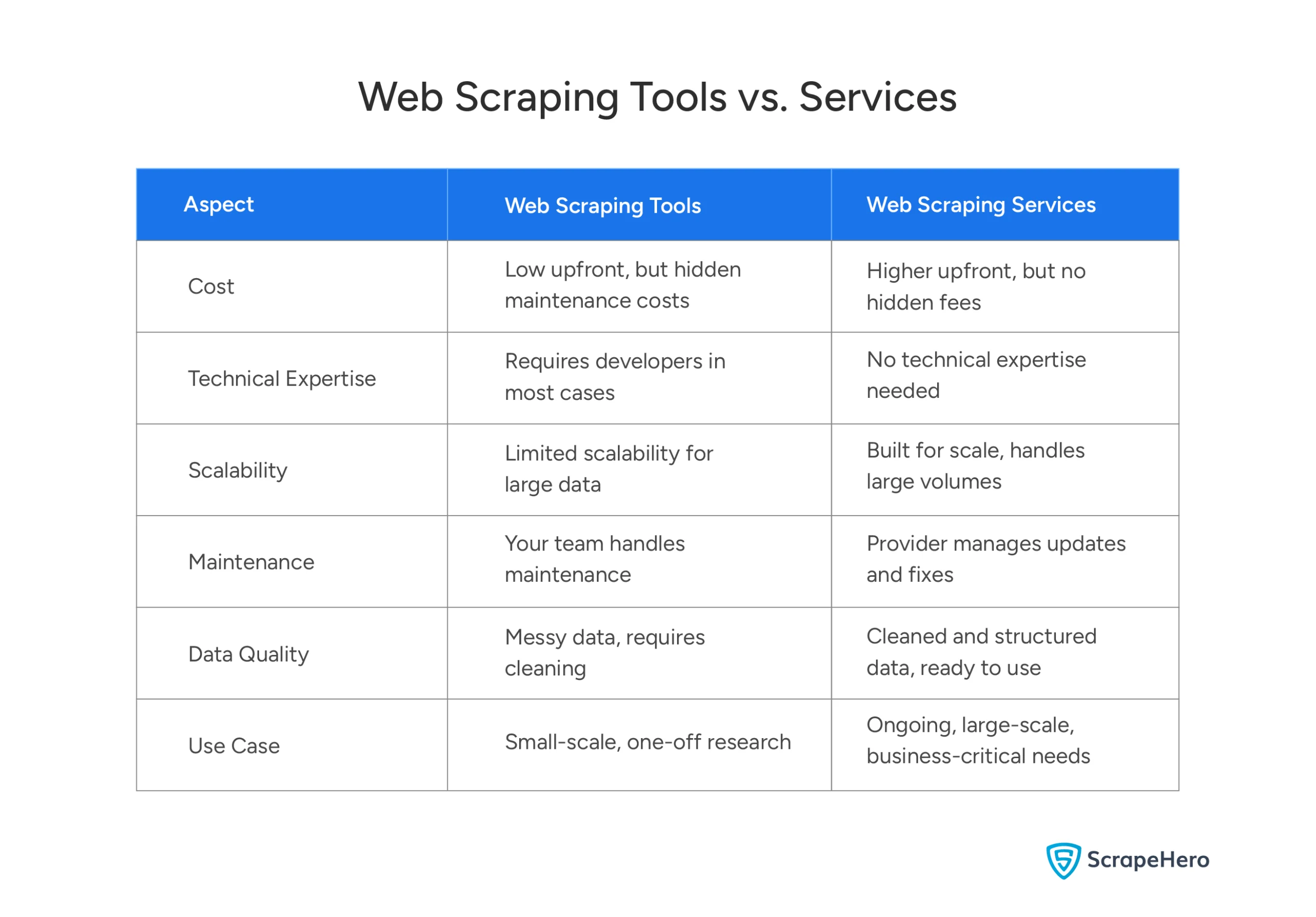
1. Cost
Tools look cheaper. The surprising truth is, they’re often not.
The subscription fee is low, sometimes free. That part’s real. But the moment your scraping needs grow beyond a simple project, costs start stacking up quietly. Developer time to configure things. Infrastructure to manage. Hours spent fixing scrapers when websites change. None of that shows up on the tool’s pricing page.Scraping services cost more upfront. What you’re buying is a fully built and managed pipeline, development, monitoring, maintenance, and clean data delivery included. For businesses that depend on web data consistently, that total cost is often lower than running everything in-house.

2. Technical Expertise
No-code tools are easier to start with, but they’re rarely easy to sustain.
Once you’re dealing with dynamic content, pagination, or anti-bot protection, the point-and-click interface runs out of road fast. At that point, someone with real technical knowledge has to step in. For many teams, that means pulling a developer off something more important.
Scraping services remove that burden entirely. Their team handles the technical side. Your team handles the insights. That’s a clean division of labor most business leaders appreciate once they’ve experienced the alternative.
3. Scalability
Tools handle small projects well. That’s genuinely true.
A few hundred pages across a couple of websites? Fine. But when you’re tracking thousands of product listings across multiple marketplaces that are updated daily, the infrastructure required to do so reliably is not trivial. Rate limits kick in. IPs get blocked. Jobs fail silently, and nobody notices until the data’s already stale.
Scraping services are built for that scale from day one. Distributed systems, high request volumes, and multiple websites running in parallel. It’s what they do. You don’t have to grow into it gradually and painfully.
4. Maintenance
Websites change all the time. That’s just the reality.
A layout update, a new HTML structure, a small design tweak, and your scraper stops working. With a tool, that’s your team’s problem. Someone has to catch it, fix it, and get the pipeline back up. If it breaks overnight, you’re waking up to a gap in your data.
With a service, that’s the provider’s problem. They monitor, they catch it, they fix it. You might not even know it happened. That kind of reliability is easy to undervalue until the first time a broken scraper costs you a bad pricing decision.
5. Data Quality
This one doesn’t get enough attention.
Raw scraped data is messy. Product names in three different formats. Missing fields. Duplicate records. Inconsistencies that seem minor until they’re quietly skewing your analysis.
Tools extract the data. What you do with the mess afterward is on you.
Services clean it before it reaches you. Validated, standardized, structured, and ready to use. For teams making pricing calls or assortment decisions based on this data, that difference in quality isn’t a nice-to-have. It’s what makes the insights actually trustworthy.
Which Option is Right for Your Business?
Honestly, the answer isn’t that complicated once you’re clear on two things: how much your business actually depends on web data, and how much of that dependency is going to grow.
If you’re running small experiments, doing one-off research, or just testing whether competitor tracking is worth investing in, a scraping tool is fine. Start there. It’s low-cost, low-commitment, and good enough for what you need right now.
But if web data is already part of how you make pricing calls, monitor competitors, or track marketplace trends, and you need that data consistently and at scale, tools will eventually let you down. Not because they’re bad. Because they’re not built for what you’re asking them to do. This is crucial when comparing scraping tools vs scraping services.
That’s when a managed web scraping service like ScrapeHero stops being an expense and starts being the obvious call.
Why ScrapeHero is the Right Choice for E-commerce Brands
Most scraping-tool vs. service conversations stop at features. ScrapeHero ensures it’s actually usable when it reaches you.
Your team doesn’t touch the infrastructure. We design the scrapers, manage the proxies, handle anti-bot protections, and keep the pipelines running. What arrives on your end is clean, structured, and ready for your analysts to work with, whether you’re tracking competitor prices, monitoring product listings, or watching how marketplaces shift across regions.
ScrapeHero is built for scale. As your data needs grow, the infrastructure grows with it. You don’t rebuild. You don’t re-negotiate. It just handles more.
Over 14,700 companies trust ScrapeHero to run their data pipelines. And a 98% customer retention rate doesn’t happen because the product is adequate. It happens because businesses that depend on consistent web data no longer want to do it any other way.
Final Thoughts
Scraping tools vs. scraping services isn’t a debate with a single universal winner. Tools work well for small projects, early experiments, and limited data needs. But they’re not designed to be the backbone of an e-commerce data strategy.
When your needs grow, the cracks show fast. But managed services remove the complexity. You get scalable infrastructure, ongoing maintenance, and clean data delivered on schedule. Your team focuses on decisions, not pipelines.
Discover how ScrapeHero handles your e‑commerce data needs. No guesswork and no pipelines to manage. Just the data you need, when you need it.
FAQs
A scraping service is a managed solution where a team handles all aspects of web scraping, including data extraction, cleaning, and delivery. It provides businesses with clean, structured data without requiring technical expertise or infrastructure management.
Scraping tools are generally legal, but their use can violate some websites’ terms of service, which may lead to legal challenges. It’s important to ensure compliance with website policies and local laws when using scraping tools.
The best scraping service depends on your specific needs, such as data volume, frequency, and customization requirements. Services like ScrapeHero are highly rated for providing reliable, scalable, and managed web scraping solutions tailored to e-commerce brands.
Scraping tools are worth it for small projects or basic data needs, offering low upfront costs. However, for large-scale, ongoing data collection, managed web scraping services like ScrapeHero often offer better scalability, reliability, and data quality.



