

Modern businesses can’t survive without web data extraction.
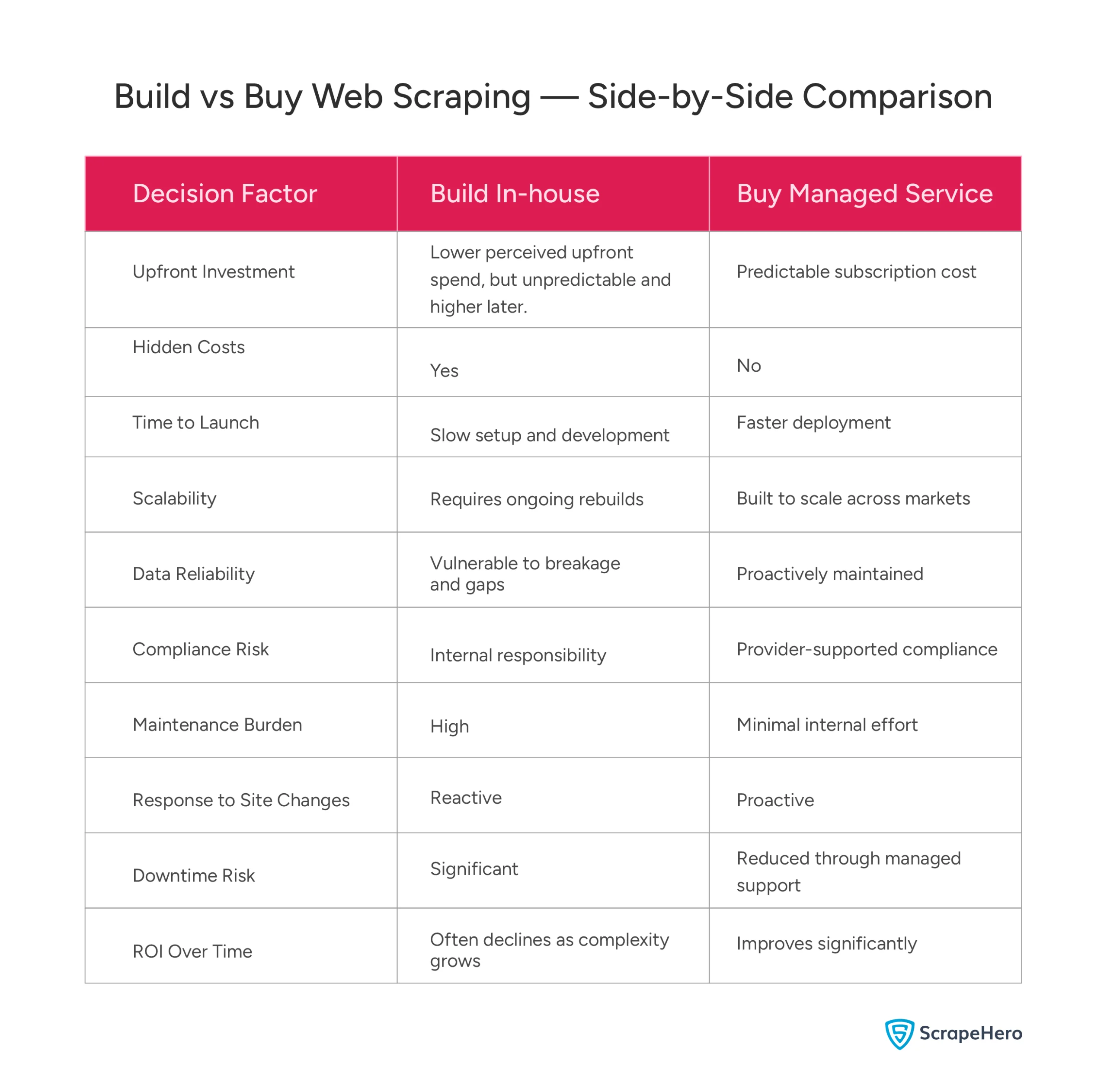
When it comes to web scraping for e-commerce, price monitoring, competitor tracking, and digital shelf analytics are all fueled by web data extraction. But at some point, every team hits the same wall: The build vs. buy decision. Do we build our own web scraping infrastructure, or do we let someone else handle it?
It seems like a straightforward call. It never is.
If you’re sitting with this decision right now, you’re probably worried about making the wrong decision. A bad call here doesn’t just slow you down. It can quietly hollow out your competitive edge while rivals move faster on cleaner, better data.
But by the time you finish reading this article, you won’t need anyone to tell you what to do. You’ll already know.

The True Costs of Building In-House Web Scraping
Engineering and Build Costs
Building an in-house scraping system takes more than most teams’ budget. Custom coding, server management, and configuring frameworks such as Playwright, Puppeteer, and Selenium require skilled engineers already stretched across other priorities. Without prior scraping experience, the learning curve is expensive, and the timeline drags.
Here’s where it gets interesting. Once the system is live, the work doesn’t stop:
- Proxies need rotating, CAPTCHA needs solving, and data pipelines need constant monitoring.
- Troubleshooting pulls engineers away from higher-value work, and data analysts waste hours cleaning the raw data. Those hours don’t show up on the original plan, but they absolutely show up on your revenue.
- Growth adds another layer of difficulty. Every new retailer, location, or product category brings its own anti-scraping measures, data structures, and formatting quirks that need tailored solutions.
Scaling up means:
- More infrastructure
- More people to maintain it.
The Risk of Silent Failures
This connects to something bigger. In-house systems don’t always fail loudly. More often, they quietly stop returning accurate data. Gaps creep in, insights get skewed, and by the time anyone notices, business decisions have already been made on incomplete or wrong information.
The consequences ripple across operations:
- Pricing calls get miscalculated
- Inventory decisions go sideways
- Competitor reads become unreliable
Over time, that erodes trust in the data across the whole team. And rebuilding that trust takes far longer than fixing the scraper.
Legal and Compliance Exposure
Web scraping carries real legal risk. GDPR and CCPA restrict how data can be collected, stored, and used. Robots.txt files and Terms of Service agreements add another layer of restrictions on what can be extracted and from where.
Here’s the uncomfortable truth. If something gets missed, the exposure isn’t limited to fines. It extends to legal action and reputational damage that takes years to recover from.
Data Quality and Operational Downtime
Websites change constantly. Structures shift, anti-scraping measures tighten, and content gets reorganized. An internal system that doesn’t keep pace returns inconsistent, incomplete, or outdated data, and none of it flags itself as wrong. It just corrupts the decisions downstream.
Downtime compounds this even further. A price monitoring tool that goes offline Friday afternoon and isn’t caught until Monday means a competitor has already moved on pricing, the window has closed, and those sales don’t come back.
In-house systems have no built-in safety net for this. When they go down, the data stops, and the business operates blind until someone fixes the problem.
What we covered so far

Why Outsourcing is the Better Choice: A Build vs. Buy Breakdown
Operational Simplicity and Cost
Outsourcing web scraping hands off the entire infrastructure burden, proxies, CAPTCHA management, broken pipelines, and shifting website structures to a team built specifically to handle it. Engineers get their time back for work that requires their actual expertise.
The cost structure changes, too. In-house scraping looks affordable at the build stage, but infrastructure bills, server maintenance, and unplanned troubleshooting compound quickly. Managed services, however, run on predictable, subscription-based pricing with no surprise invoices when something breaks or when the business needs to scale.
Scalability and Ongoing Reliability
Your scraping needs will look different 18 months from now. This build vs buy web scraping decision becomes even more consequential as you scale. Managed services are built to absorb that growth without requiring new development cycles or infrastructure investment every time a new market or retailer gets added.
More importantly, they also don’t just respond to website changes; they stay ahead of them, updating systems proactively so data keeps flowing without interruption.
An in-house system that works today can be completely blind after a site update tomorrow. A managed service accounts for that before it becomes a problem.
The ROI of Managed Web Scraping Services
Where the Savings Actually Come From
The real cost of in-house scraping is engineers, servers, proxies, and unplanned troubleshooting hours that nobody puts in the budget but everyone ends up paying for. Any honest web scraping solution comparison will show that managed services replace that unpredictable spend with a fixed cost that covers exactly what the business needs.
The money recovered, therefore, goes toward product development, marketing, and work that generates revenue rather than maintaining infrastructure that just enables it.
Here’s why that matters. Every hour an engineer spends rotating proxies or debugging a scraper is an hour not spent on pricing strategy, customer experience, or product expansion. That trade-off has a real dollar value, and it accumulates faster than most teams account for.
Reliability as a Business Input
Competitors aren’t waiting for a scraper to come back online. When in-house systems go down, the data gap widens while the market keeps moving, and by the time the issue gets caught, the actionable window has already passed.
Managed services are built around data accuracy because their business depends on delivering it. There’s a dedicated team whose entire focus is on keeping data flowing accurately and on schedule. That consistency consequently makes data a dependable business input rather than something the team mentally discounts because they’re not sure if it’s current.
Now you see the connection. The in-house scraping setup that handles today’s volume won’t automatically handle two years of growth. Managed services, on the other hand, scale as the business scales, adding regions, categories, and retailers without rebuild cycles or resource spikes.
ScrapeHero – The Best Web Scraping Service for E-commerce
What ScrapeHero Handles
ScrapeHero, the best data extraction service, manages the entire data collection operation. On our end, we handle:
- Proxies
- CAPTCHA solving
- Rotating IPs
- Data structuring
- Data cleaning
- Data delivery
Whether the need is competitor price tracking, product availability monitoring, or customer review aggregation, the data arrives accurately and ready to use, with no infrastructure to manage and no technical issues to resolve internally.
The solution also scales as the business scales, adding new retailers, locations, and categories without requiring a rebuild.
Compliance, Reliability, and Support
Most businesses don’t track how close they are to a compliance problem until they’re already in one. ScrapeHero collects data in line with relevant laws and website policies, removing that exposure entirely. There are no surprise maintenance windows, and no engineers pulled off other work to fix a broken scraper. As a result, the team handles ongoing maintenance in the background, so the data stays current and the internal team stays focused on using it rather than managing the system that collects it.
Every operational challenge that comes with in-house scraping, CAPTCHA bypassing, proxy network maintenance, uptime consistency, and data accuracy has a built-in solution at ScrapeHero.
This brings us full circle. As needs shift and the business expands across e-commerce markets, ScrapeHero’s web scraping service for e-commerce adapts without friction. The result is a reliable data operation that runs without requiring internal resources to keep it stable.
Final Thoughts
In-house scraping is a business risk that compounds over time. The hidden costs, maintenance drain, compliance exposure, and silent data failures don’t resolve themselves. They accumulate until they’re affecting decisions, revenue, and team confidence in the data itself.
Outsourcing removes that weight. Reliable data, predictable costs, and no internal resources spent on infrastructure maintenance. Engineers focus on work that moves the business. Data quality improves. And operational risk drops.
For build-vs-buy ecommerce decisions, ScrapeHero’s web scraping service is built for e-commerce teams that need accurate, consistent data without running the infrastructure themselves. Fully managed, legally compliant, and built to scale with the business.
If your goal is to use data rather than manage the system collecting it, the build vs. buy case for outsourcing is clear. ScrapeHero is your ideal choice.
FAQs
E-commerce teams use web scraping to track competitor prices, monitor product availability, and analyze digital shelf performance. It’s essentially how they stay informed and make faster, data-backed decisions on pricing, inventory, and strategy.
Yes. Outsourcing removes the infrastructure burden, keeps costs predictable, and ensures data keeps flowing even when websites change or go through updates.
The biggest risk is silent failure, where the scraper stops returning accurate data without anyone noticing until decisions have already been made on bad information. On top of that, there’s real legal exposure around compliance with GDPR, CCPA, and website terms of service that’s easy to overlook when you’re focused on just getting the system to work.



