
Yahoo Finance is a good source for extracting financial data, be it – stock market data, trading prices or business-related news.
Steps to Scrape Yahoo Finance
- Construct the URL of the search results page from Yahoo Finance. For example, here is the one for Apple-http://finance.yahoo.com/quote/AAPL?p=AAPL
- Download HTML of the search result page using Python Requests
- Parse the page using LXML – LXML lets you navigate the HTML Tree Structure using Xpaths. We have predefined the XPaths for the details we need in the code.
- Save the data to a JSON file.
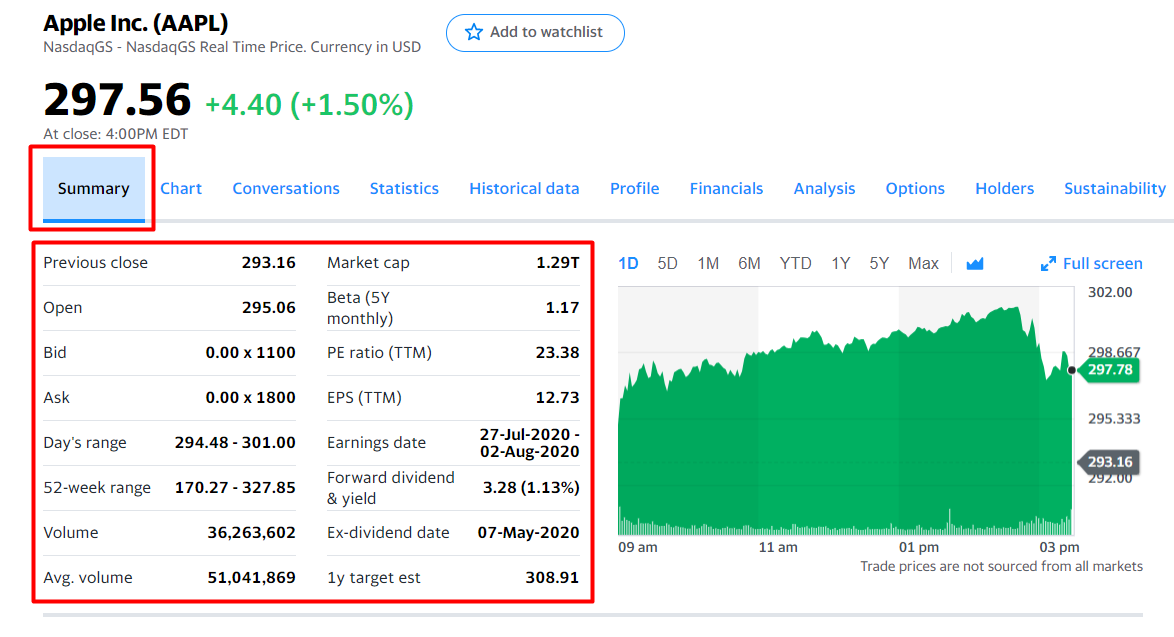
In this tutorial, we will extract the trading summary for a public company from Yahoo Finance ( like http://finance.yahoo.com/quote/AAPL?p=AAPL ). We’ll be extracting the following fields for this tutorial.
- Previous Close
- Open
- Bid
- Ask
- Day’s Range
- 52 Week Range
- Volume
- Average Volume
- Market Cap
- Beta
- PE Ratio
- EPS
- Earning’s Date
- Dividend & Yield
- Ex-Dividend Date
- 1yr Target EST
Below is a screenshot of what data fields we will be web scraping from Yahoo Finance.
Requirements
Install Python 3 and Pip
Here is a guide to install Python 3 in Linux – http://docs.python-guide.org/en/latest/starting/install3/linux/
Mac Users can follow this guide – http://docs.python-guide.org/en/latest/starting/install3/osx/
Windows Users go here – https://www.scrapehero.com/how-to-install-python3-in-windows-10/
Packages
For this web scraping tutorial using Python 3, we will need some packages for downloading and parsing the HTML. Below are the package requirements:
- PIP to install the following packages in Python (https://pip.pypa.io/en/stable/installing/ )
- Python Requests, to make requests and download the HTML content of the pages ( http://docs.python-requests.org/en/master/user/install/).
- Python LXML, for parsing the HTML Tree Structure using Xpaths ( Learn how to install that here – http://lxml.de/installation.html )
The Code
from lxml import html
import requests
import json
import argparse
from collections import OrderedDict
def get_headers():
return {"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-encoding": "gzip, deflate, br",
"accept-language": "en-GB,en;q=0.9,en-US;q=0.8,ml;q=0.7",
"cache-control": "max-age=0",
"dnt": "1",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "none",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36"}
def parse(ticker):
url = "http://finance.yahoo.com/quote/%s?p=%s" % (ticker, ticker)
response = requests.get(
url, verify=False, headers=get_headers(), timeout=30)
print("Parsing %s" % (url))
parser = html.fromstring(response.text)
summary_table = parser.xpath(
'//div[contains(@data-test,"summary-table")]//tr')
summary_data = OrderedDict()
other_details_json_link = "https://query2.finance.yahoo.com/v10/finance/quoteSummary/{0}?formatted=true&lang=en-US®ion=US&modules=summaryProfile%2CfinancialData%2CrecommendationTrend%2CupgradeDowngradeHistory%2Cearnings%2CdefaultKeyStatistics%2CcalendarEvents&corsDomain=finance.yahoo.com".format(
ticker)
summary_json_response = requests.get(other_details_json_link)
try:
json_loaded_summary = json.loads(summary_json_response.text)
summary = json_loaded_summary["quoteSummary"]["result"][0]
y_Target_Est = summary["financialData"]["targetMeanPrice"]['raw']
earnings_list = summary["calendarEvents"]['earnings']
eps = summary["defaultKeyStatistics"]["trailingEps"]['raw']
datelist = []
for i in earnings_list['earningsDate']:
datelist.append(i['fmt'])
earnings_date = ' to '.join(datelist)
for table_data in summary_table:
raw_table_key = table_data.xpath(
'.//td[1]//text()')
raw_table_value = table_data.xpath(
'.//td[2]//text()')
table_key = ''.join(raw_table_key).strip()
table_value = ''.join(raw_table_value).strip()
summary_data.update({table_key: table_value})
summary_data.update({'1y Target Est': y_Target_Est, 'EPS (TTM)': eps,
'Earnings Date': earnings_date, 'ticker': ticker,
'url': url})
return summary_data
except ValueError:
print("Failed to parse json response")
return {"error": "Failed to parse json response"}
except:
return {"error": "Unhandled Error"}
if __name__ == "__main__":
argparser = argparse.ArgumentParser()
argparser.add_argument('ticker', help='')
args = argparser.parse_args()
ticker = args.ticker
print("Fetching data for %s" % (ticker))
scraped_data = parse(ticker)
print("Writing data to output file")
with open('%s-summary.json' % (ticker), 'w') as fp:
json.dump(scraped_data, fp, indent=4)
You can download the code from the link https://gist.github.com/scrapehero-code/6d87e1e1369ee701dcea8880b4b620e9.
If you would like the code in Python 2 check out this link https://gist.github.com/scrapehero/b0c7426f85aeaba441d603bb81e1d0e2
Running the Scraper
Assume the script is named yahoofinance.py. If you type in the script name in command prompt or terminal with a -h
python3 yahoofinance.py -h usage: yahoo_finance.py [-h] ticker positional arguments: ticker optional arguments: -h, --help show this help message and exit
The ticker argument is the ticker symbol or stock symbol to identify a company.
To find the stock data for Apple Inc we would put the argument like this:
python3 yahoofinance.py AAPL
This should create a JSON file called AAPL-summary.json that will be in the same folder as the script.
The output file would look similar to this:
{
"Previous Close": "293.16",
"Open": "295.06",
"Bid": "298.51 x 800",
"Ask": "298.88 x 900",
"Day's Range": "294.48 - 301.00",
"52 Week Range": "170.27 - 327.85",
"Volume": "36,263,602",
"Avg. Volume": "50,925,925",
"Market Cap": "1.29T",
"Beta (5Y Monthly)": "1.17",
"PE Ratio (TTM)": "23.38",
"EPS (TTM)": 12.728,
"Earnings Date": "2020-07-28 to 2020-08-03",
"Forward Dividend & Yield": "3.28 (1.13%)",
"Ex-Dividend Date": "May 08, 2020",
"1y Target Est": 308.91,
"ticker": "AAPL",
"url": "http://finance.yahoo.com/quote/AAPL?p=AAPL"
}
You can download the code at https://gist.github.com/scrapehero/516fc801a210433602fe9fd41a69b496
Let us know in the comments how this scraper worked for you.
Known Limitations
This code should work for grabbing stock market data of most companies. However, if you want to scrape for thousands of pages and do it frequently (say, multiple times per hour) there are some important things you should be aware of, and you can read about them at How to build and run scrapers on a large scale and How to prevent getting blacklisted while scraping. If you want help extracting custom sources of data you can contact us.
If you need some professional help with scraping complex websites contact us by filling up the form below.
Tell us about your complex web scraping projects
Turn the Internet into meaningful, structured and usable data
Disclaimer: Any code provided in our tutorials is for illustration and learning purposes only. We are not responsible for how it is used and assume no liability for any detrimental usage of the source code. The mere presence of this code on our site does not imply that we encourage scraping or scrape the websites referenced in the code and accompanying tutorial. The tutorials only help illustrate the technique of programming web scrapers for popular internet websites. We are not obligated to provide any support for the code, however, if you add your questions in the comments section, we may periodically address them.



