

When it comes to web scraping that drives decision-making, you should choose which method to employ, which paves the way for a serious discussion on cloud scraping vs. manual scraping.
Both cloud scraping and manual scraping are prominent methods of gathering data from websites to gain competitive insights.
This article will discuss both concepts in detail, including their workings, use cases, benefits, and challenges.
Cloud Scraping vs Manual Scraping: The Concept
What is Cloud Scraping?
Cloud scraping is the method of extracting data from websites automatically using cloud-based web scraping tools or services.
Cloud scraping uses the benefit of cloud computing and enables users to scrape large volumes of data with minimal technical intervention.
An example is a real estate company that uses Google Cloud Platform’s Dataflow to extract listings from various websites and consolidate the data into its database.
What is Manual Scraping?
Manual scraping or hands-on web scraping is the traditional process of collecting data from websites involving creating custom codes.
Even though manual scraping is effective for small-scale tasks, it is time-consuming and requires extensive coding knowledge.
An example is an e-commerce analyst writing Python code for web scraping using BeautifulSoup to manually extract product prices and customer reviews from various online marketplaces.
Cloud Scraping vs Manual Scraping: Working
How Cloud Scraping Works
In cloud scraping, the user gives the URL of the target website to the cloud scraping tool.
The tool uses its resources to navigate pages and extract and store data in a structured format.
There may be advanced features like data cleansing and deduplication for the tool that ensure high-quality results.
How Manual Scraping Works
Manual scraping is a labor-intensive process. Users usually directly copy text from web pages or write scraping scripts to extract data.
That is, the user needs to manually access websites, identify the data, and copy it into a desired format.
Manual scraping has control over the process, but it’s more prone to errors. At times, it can be prolonged, especially for large datasets.
Cloud Scraping vs Manual Scraping: Key Differences
To decide between cloud scraping and manual scraping, you need to understand the differences between these two methods. Some key differences include:
- Automation and Efficiency
- Scalability and Resource Management
- Accuracy and Reliability
- Cost and Resource Allocation
- Flexibility and Adaptability
1. Automation and Efficiency
Cloud scraping can automate data extraction using advanced algorithms and machine learning to handle complex tasks without manual intervention.
It is this automation capability that makes cloud scraping efficient, especially for large-scale web scraping projects.
Whereas manual scraping has human intervention, making it more labor-intensive in every step of the data collection.
Since manual scraping relies on manual efforts, it is slower and less efficient, especially when dealing with extensive datasets, as said earlier.
2. Scalability and Resource Management
Cloud scraping platforms can scale quickly and handle fluctuations in data volume without affecting performance.
Also, the cloud infrastructure efficiently manages resources and ensures the scraping operations remain scalable and cost-effective.
On the other hand, manual scraping is limited in scalability and needs help with large-scale projects or frequent data updates.
Resource management for manual scraping is also challenging and requires additional workforce and infrastructure when data demands increase.
3. Accuracy and Reliability
Cloud scraping tools can ensure high accuracy in data extraction as they have features for error-checking and data validation and adapt to website structure changes.
Cloud scraping is also highly reliable, as it consistently delivers accurate data even when dealing with complex and dynamic websites.
Manual scraping is prone to human errors and provides inaccurate data. These errors occur either at the time of data entry or when interpreting complex web layouts.
Since the reliability of manual scraping depends on the skill and attention of the individuals performing the task, it can vary widely.
Interested in knowing how to extract data from JavaScript-loaded websites effortlessly? Then you can read our article on how to scrape a dynamic website.
4. Cost and Resource Allocation
Cloud scraping can reduce the need for manual labor and infrastructure in the long term, even though it may involve initial setup costs.
Since cloud scraping utilizes cloud-based infrastructure, the allocation of resources can be optimized and adjusted based on data needs.
Manual scraping is cost-effective for small projects. However, it can be expensive and resource-intensive for large-scale scraping requirements.
Also, manual scraping requires managing personnel and hardware, which increases the cost and can be time-consuming.
5. Flexibility and Adaptability
Cloud scraping tools can handle a wide range of data formats, adapt to various website structures, and be customized for specific requirements.
Cloud scraping platforms automatically adjust to any changes in the website layouts and structures. This ensures that there is continued data accuracy.
Even though manual scraping is more flexible in data collection methods, it is difficult to handle complex or frequently changing websites.
Constant script updates or manual interventions are required for manual scraping in situations where the website continuously changes.
|
Feature |
Cloud Scraping |
Manual Scraping |
| Automation | Automated data extraction | Manual intervention required |
| Efficiency | Highly efficient for large-scale tasks | Slower, labor-intensive |
| Scalability | Easily scalable to handle large volumes | Limited scalability |
| Resource Management | Efficient cloud-based resource management | Requires additional manpower and infrastructure |
| Accuracy | High accuracy with error-checking | Prone to human errors |
| Reliability | Consistent and reliable | Depends on individual skills |
| Cost | Cost-effective in the long term | Potentially costly for large projects |
| Flexibility | Handles diverse data formats | Skill-intensive and resource-dependent extraction |
| Adaptability | Adapts automatically to website changes | Requires constant updates |
Cloud Scraping vs Manual Scraping: Use Cases

Use Cases for Cloud Scraping
Cloud scraping is efficient for large-scale web scraping needs and has high accuracy and speed. Some of its other use cases include:
- E-commerce Price Monitoring
- Market Research and Analysis
- Real Estate Listings
- Financial Data Aggregation
- Travel and Hospitality
1. E-commerce Price Monitoring
Cloud scraping supports price and product monitoring. E-commerce companies can identify pricing trends, track the prices of competitors, and adjust their pricing strategies.
2. Market Research and Analysis
Data scraped from various sources, such as review sites and forums, can be used for market research and consumer behavior studies to make informed decisions.
Do you know that web scraping can simplify identifying market trends in businesses? Find out how by reading our article on identifying market opportunities for business growth using web scraping.
3. Real Estate Listings
Cloud scraping is helpful in gathering real estate and housing data to monitor property listings, prices, and availability across different platforms and analyze market trends.
4. Financial Data Aggregation
Using cloud scraping, you can gather real-time data on stock prices, currency exchange rates, and economic indicators for risk assessment.
How do you scrape share-market data from a dynamic website like StockTwits? Read the article on web scraping StockTwits data to learn about it.
5. Travel and Hospitality
Travel agencies and hospitality businesses can gather travel, hotel, and airline data on flight schedules and hotel prices to optimize pricing strategies.
Use Cases for Manual Scraping
Manual scraping is helpful for specific tasks, especially for small-scale data extraction. Some of its typical use cases include:
- Small-Scale Data Collection
- Websites with Dynamic Content
- Data Quality Assurance
- One-Time Data Extraction
- Complex Web Structures
1. Small-Scale Data Collection
Manual scraping is suitable for small research projects where the volume of data required is manageable.
2. Websites with Dynamic Content
Websites use JavaScript to render content dynamically, and manual scraping can effectively handle this type of data.
3. Data Quality Assurance
Manual scraping ensures that the accuracy and quality of data extracted by automated methods meet specific standards and criteria.
4. One-Time Data Extraction
For one-time data extraction projects or if there is no need for regular updates, manual scraping will be a cost-effective solution.
5. Complex Web Structures
Manual scraping is beneficial when handling websites with intricate structures or that require user interactions or navigation through multiple layers.
Benefits of Cloud Scraping Over Manual Scraping
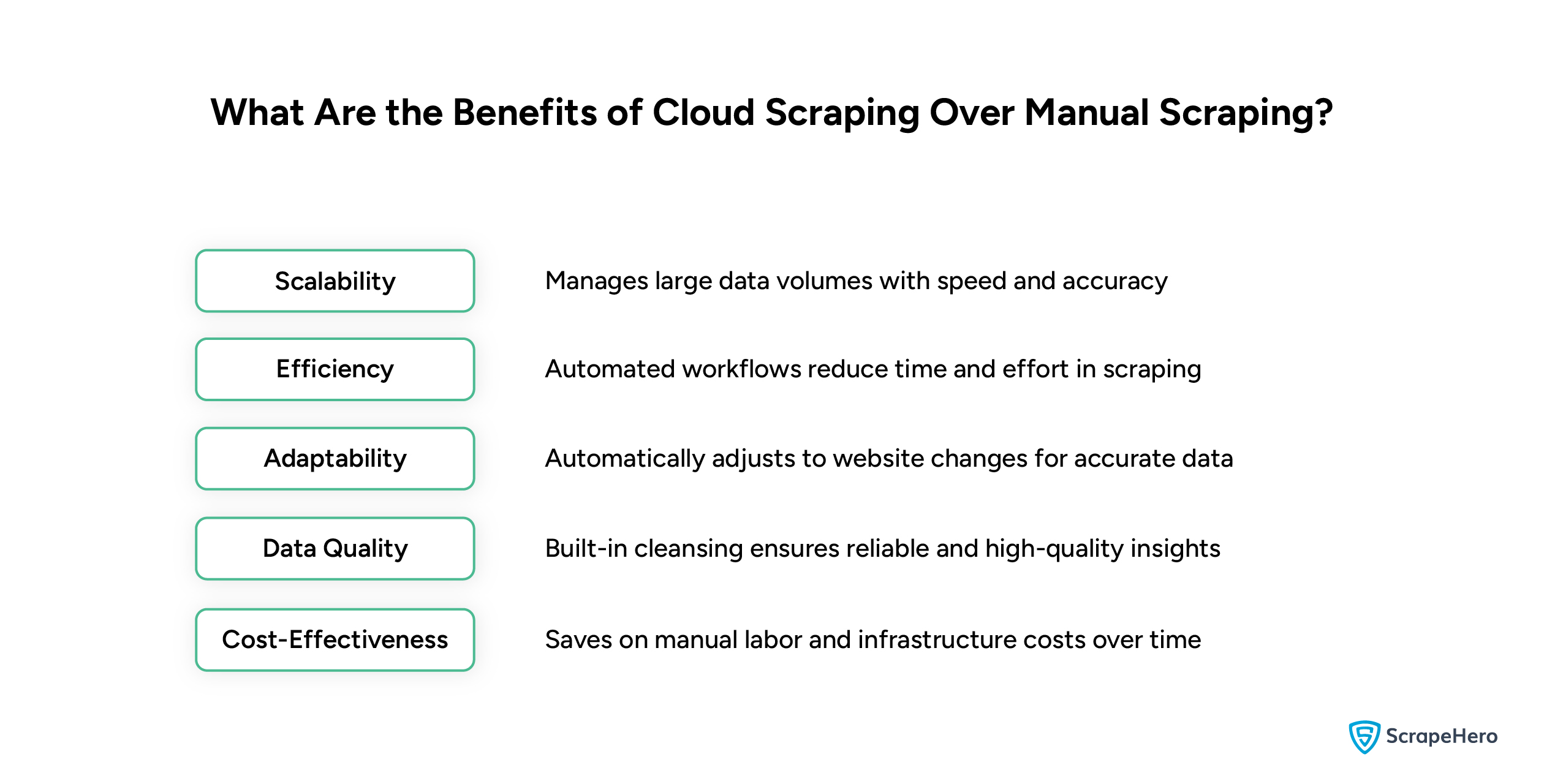
Both cloud scraping and manual scraping have their own advantages, but cloud scraping is the preferred choice for many.
Some of the benefits of cloud scraping over manual scraping include:
1. Scalability
When compared to manual scraping, cloud scraping handles vast amounts of data with speed and accuracy.
2. Efficiency
Cloud scraping platforms depend on automated processes that optimize workflows and minimize manual intervention, reducing the time and effort for data extraction.
3. Adaptability
As mentioned earlier, cloud scraping tools can automatically adapt to website changes, ensuring data accuracy compared to manual scraping.
4. Data Quality
Cloud scraping supports features like data cleansing and deduplication, which enhances the quality of extracted data.
5. Cost-Effectiveness
Cloud scraping is more cost-effective in the long run since no manual labor is involved. It also resolves all the manual scraping challenges related to cost.
ScrapeHero Cloud– A Cloud-Based Web Scraping Platform
When choosing between cloud scraping and manual scraping, you need to consider crucial factors like whether you should scrape large data volumes, handle time-sensitive projects, or have limited resources or expertise.
You should also consider whether the option you selected is reliable for your needs and provides long-term savings.
If you prefer cloud scraping, then ScrapeHero Cloud is an excellent choice for your scraping requirements.
We have more than 25 easy-to-use and pre-built scrapers, including Google Maps search results scraper and Amazon product details and pricing scraper, that can extract data periodically.
Our scrapers require no coding knowledge to use, and they are affordable, too. You can even take advantage of a free trial we are offering and scrape up to 25 pages.
An added benefit of our scrapers is zero maintenance. So you don’t need to worry about website structure changes, blocking, etc.
Why Choose ScrapeHero Web Scraping Services?
If your data requirements are much larger in scale and you need a service provider to regularly tailor solutions for the long term, then ScrapeHero’s web scraping service may be the only option.
We can provide you with custom solutions and ensure all your specific data requirements are met.
We have a track record of successful projects, and we can deliver accurate and consistent data to small businesses or large enterprises.
Wrapping Up
Choosing between manual or cloud-based web scraping depends on the size of your project, available resources, and specific requirements.
For your web scraping requirements, you can contact ScrapeHero. We are a full-service data provider that can cater to your data needs without compromising quality.
We have automated quality checks that utilize AI and ML and can scale according to your requirements. We can offer customized plans that fit your business well.
Frequently Asked Question
The legality of web scraping, in general, depends on several factors, such as the nature of the data you are scraping, the website’s terms of service, and regional laws.
Yes. Cloud scraping can manage large-scale data extraction efficiently.
Limitations of manual scraping include its inability to scale, high error rates, and difficulties with anti-scraping measures from websites.



