
StockTwits is a website that hosts share-market data from where you can pull stock data. The website is dynamic.
Therefore, you need headless browsers like Selenium for scraping StockTwits data from their official website.
However, you can also extract data from StockTwits using the URLs from which the website fetches the stock data. These URLs deliver data in a JSON format, and you can use Python requests to fetch them.
This tutorial illustrates StockTwits data scraping using Python requests and Selenium.
Data Scraped from StockTwits
The tutorial teaches you how to get data from StockTwits using Python. It scrapes three kinds of stock information.
- Top Gainers: Stocks whose value has increased that day
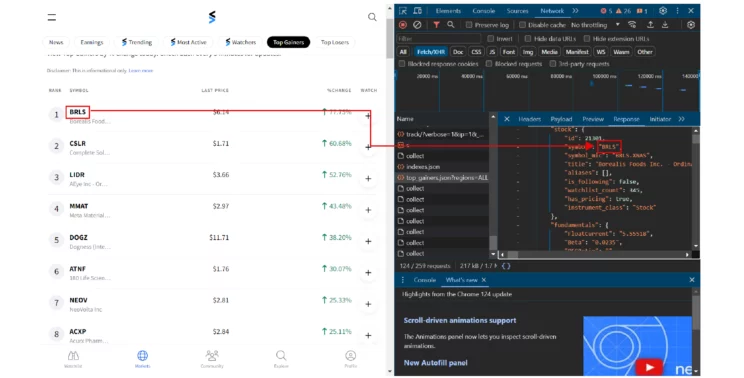
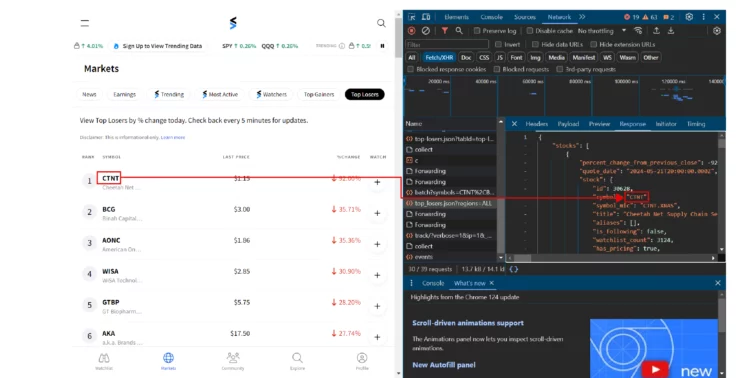
- Top Losers: Stocks whose value has decreased that day
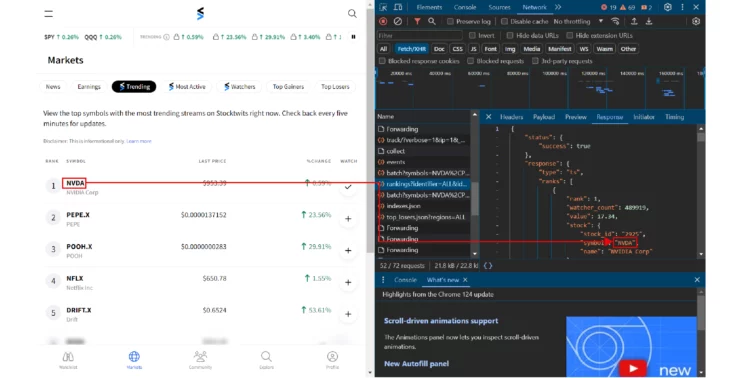
- Trending Stocks: Stocks traded most that day
- Earnings Reported: Companies that have reported their earnings that day
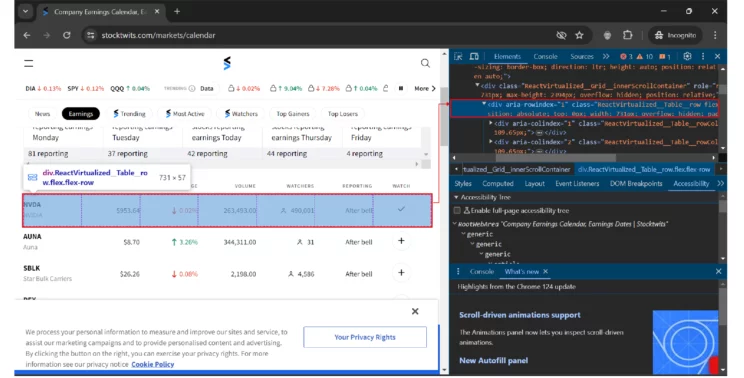
This code scraps the first three list directly from the URL that delivers this information to StockTwits. To find these URL:
- Visit StockTwits
- Open developer options
- Go to the network tab
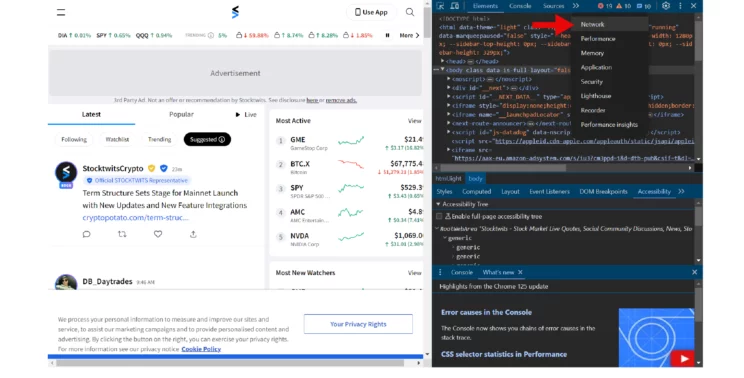
- Make sure you have selected Fetch/XHR
- Scroll in the name panel to find the URL
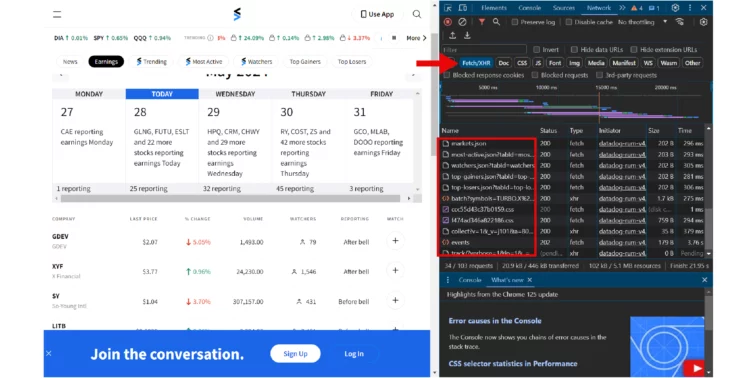
The Environment
This tutorial uses Selenium to get the HTML code from the StockTwits website and Python requests to extract data from the URLs that deliver stock data.
Therefore, install Python requests and Selenium using pip.
pip install requests seleniumThe tutorial uses BeautifulSoup to parse data. It is also an external library you can install using pip.
pip install beautifulsoup4The code also requires the json module to save the extracted data to a JSON file; however, the standard Python library includes the json module.
Scraping StockTwits Data: The Code
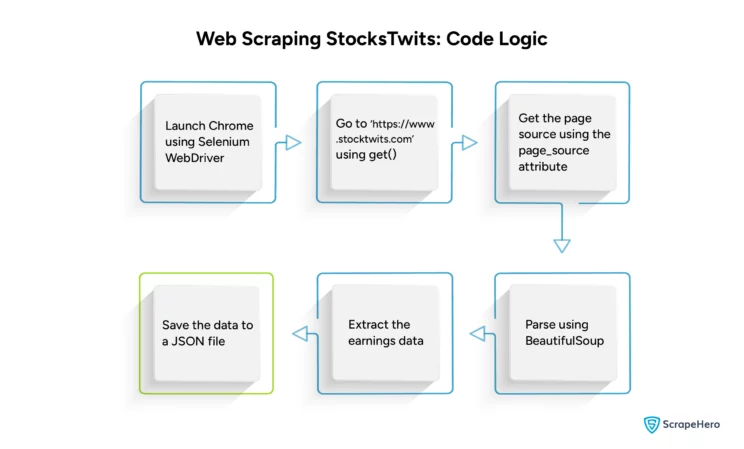
The code for Scraping StockTwits data begins with the import statements. Import the json module, BeautifulSoup, the Selenium By module, and the Selenium webdriver module. There will be a total of four import statements.
The code uses two functions: earnings() and extract():
- The first function, earnings(), extracts details of the companies that reported their earnings that day.
- The second function, extract(), is the code’s entry point. It asks the user what to scrape and executes the code accordingly.
earnings()
The earnings function adds the headless option to the Selenium webdriver object; this makes scraping faster by removing GUI.
options = webdriver.ChromeOptions()
options.add_argument("--headless")Then, it launches Chrome using the options as an arguement and goes to the https://stocktwits.com/markets/calendar page using the get method.
chrome = webdriver.Chrome(options=options)
page = chrome.get("https://stocktwits.com/markets/calendar")You can now get the HTML code of the page using the page_source attribute.
htmlContent = chrome.page_sourceThen, parse the page source using BeautifulSoup. Pass the page source to the BeautifulSoup constructor.
soup = BeautifulSoup(htmlContent)Locate all the rows inside a div element with the role row.
earnings = soup.find_all("div",{"role":"row"})You can then iterate through all the rows and extract each detail.
companyEarnings = []
for earning in earnings[1:]:
company = earning.find_all("p")
symbol = company[0].text
name = company[1].text
price = earning.find("div",{"class":"EarningsTable_priceCell__Sxx1_"}).textNote: The loop begins with the second member of the earnings array as the first is the header row.
The code extracts symbols, the company name, and the stock price. You can find the symbols and the name of the company in the p tags and the price in the div tag with the class EarningsTable_priceCell__Sxx1_.
In each loop, the function appends the extracted data to an array.
companyEarnings.append(
{
"Symbol":symbol,
"Company Name": name,
"Price": price
}
)
Finally, the function saves the array as a JSON file.
with open("earnings.json","w") as earningsFile:
json.dump(companyEarnings,earningsFile,indent=4,ensure_ascii=False)extract()
The extract() function acts as the entry point of the code. It asks you to select what to scrape and gives five choices.
The first four choices ask you what to scrape:
- top gainers
- top losers
- trending stocks
- stocks that reported their earnings that day
query = input("What to scrape? \n top-gainers [1]\n top-losers[2]\n trending stocks[3]\n stocks which reported earnings today[4]\n Insert a number (1,2,3, or 4)\n To cancel, enter 0.")When you select the option four, the function calls earnings(). The fifth choice exits the program.
if query == "4":
earnings()
elif query == "0":
return
For the other three choices, the function uses Python requests to scrape top gainers, top losers, and trending stocks. It
- Sets the URL corresponding to the choice
- Gets the data from that URL through Python requests
- Saves the data to a JSON file
For the above process, extract() uses a switch().
else:
match int(query):
case 1:
url = "https://api.stocktwits.com/api/2/symbols/stats/top_gainers.json?regions=US"
name = "topGainers"
case 2:
url = "https://api.stocktwits.com/api/2/symbols/stats/top_losers.json?regions=US"
name = "topLosers"
case 3:
url = "https://api-gw-prd.stocktwits.com/rankings/api/v1/rankings?identifier=US&identifier-type=exchange-set&limit=15&page-num=1&type=ts"
name = "trending"
response = requests.get(url,headers=headers)
responseJson = json.loads(response.text)
with open(f"{name}.json","w") as jsonFile:
json.dump(responseJson,jsonFile,indent=4)Finally, the function asks whether they need to restart the process afterward. If you choose yes, the extract() function gets called again—otherwise, the program exits.
more = input("Do you want to continue")
if more.lower() == "yes":
extract()
else:
return
Want to scrape financial data from Yahoo? Check this tutorial on how to scrape Yahoo Finance.
Code Limitations
Even though the code is suitable for scraping StockTwits data, you might need to alter it later. This is because StockTwits may change the site’s structure.
Or it might change the URL from which it fetches the stock data. In either case, the code may fail to execute.
Moreover, the code may not work for large-scale data extraction, as it doesn’t consider anti-scraping measures.
Wrapping Up
Using the code in this tutorial, you can scrape stock Market data from StockTwits with Python requests and Selenium.
However, you might need to change the code whenever StockTwits changes its website structure or the URL that delivers the stock data.
But you don’t have to change the code yourself; ScrapeHero can help you. We can take care of all your web scraping needs.
ScrapeHero is a full-service web scraping service provider capable of building enterprise-grade web scrapers and crawlers according to your specifications. ScrapeHero services include large-scale scraping and crawling, monitoring, and custom robotic process automation.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data


